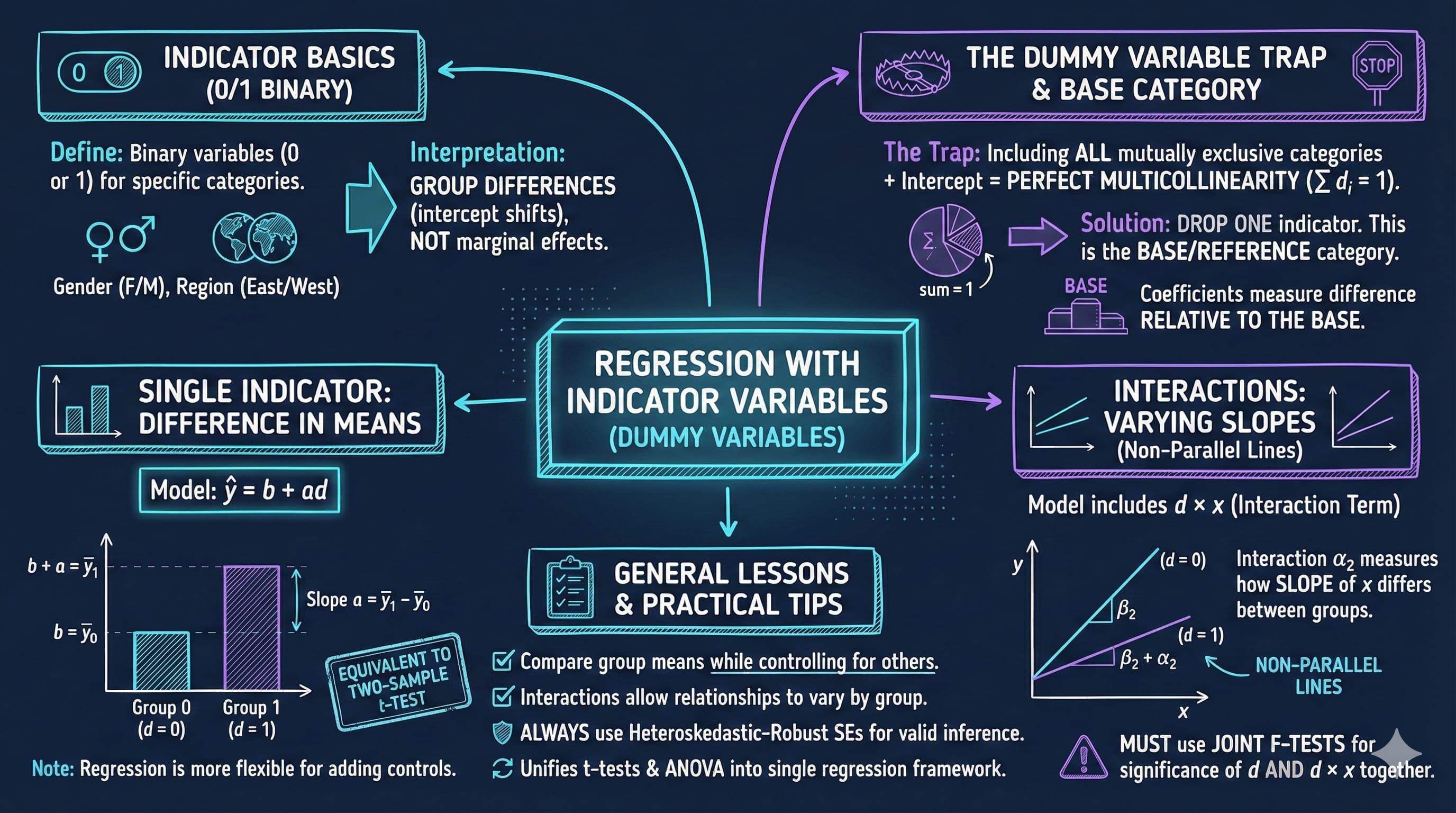
This notebook provides an interactive introduction to regression with indicator variables (also called dummy variables or categorical variables). All code runs directly in Google Colab without any local setup.
This chapter focuses on regression analysis when some regressors are indicator variables. Indicator variables are binary (0/1) variables that record whether an observation falls into a particular category.
What You’ll Learn
By the end of this chapter, you will be able to:
Understand indicator (dummy) variables and their role in regression analysis
Interpret regression coefficients when regressors are categorical variables
Use indicator variables to compare group means and test for differences
Understand the relationship between regression on indicators and t-tests/ANOVA
Incorporate indicator variables alongside continuous regressors to control for categories
Create and interpret interaction terms between indicators and continuous variables
Apply the dummy variable trap rule when using sets of mutually exclusive indicators
Choose appropriate base categories and interpret coefficients relative to the base
Conduct joint F-tests for the significance of sets of indicator variables
Apply indicator variable techniques to real earnings data
Chapter Outline
14.1 Indicator Variables: Single Binary Variable
14.2 Indicator Variable with Additional Regressors
14.3 Interactions with Indicator Variables
14.4 Testing for Structural Change
14.5 Sets of Indicator Variables
Key Takeaways – Chapter review and consolidated lessons
Practice Exercises – Reinforce your understanding
Case Studies – Apply indicator variables to cross-country data
Dataset used:
AED_EARNINGS_COMPLETE.DTA: 872 full-time workers aged 25-65 in 2000
Key economic questions:
Is there a gender earnings gap? How large is it after controlling for education and experience?
How do the returns to education differ by gender?
Do earnings differ across types of workers (self-employed, private, government)?
Can we test for structural differences between groups?
Estimated time: 90-120 minutes
Setup
First, we import the necessary Python packages and configure the environment for reproducibility. All data will stream directly from GitHub.
# Import required packagesimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport statsmodels.api as smfrom statsmodels.formula.api import olsfrom scipy import statsfrom scipy.stats import f_onewayfrom statsmodels.stats.anova import anova_lmimport randomimport os# Set random seeds for reproducibilityRANDOM_SEED =42random.seed(RANDOM_SEED)np.random.seed(RANDOM_SEED)os.environ['PYTHONHASHSEED'] =str(RANDOM_SEED)# GitHub data URLGITHUB_DATA_URL ="https://raw.githubusercontent.com/quarcs-lab/data-open/master/AED/"# Set plotting style (dark theme matching book design)plt.style.use('dark_background')sns.set_style("darkgrid")plt.rcParams.update({'axes.facecolor': '#1a2235','figure.facecolor': '#12162c','grid.color': '#3a4a6b','figure.figsize': (10, 6),'text.color': 'white','axes.labelcolor': 'white','xtick.color': 'white','ytick.color': 'white','axes.edgecolor': '#1a2235',})print("="*70)print("CHAPTER 14: REGRESSION WITH INDICATOR VARIABLES")print("="*70)print("\nSetup complete! Ready to explore regression with indicator variables.")
======================================================================
CHAPTER 14: REGRESSION WITH INDICATOR VARIABLES
======================================================================
Setup complete! Ready to explore regression with indicator variables.
Data Preparation
We’ll work with the earnings dataset which contains information on 872 full-time workers.
14.1: Indicator Variables - Single Binary Variable
An indicator variable (also called dummy variable or binary variable) takes only two values:
\[d = \begin{cases}
1 & \text{if in the category} \\
0 & \text{otherwise}
\end{cases}\]
Simple Regression on Single Indicator
When we regress \(y\) on just an intercept and an indicator variable:
\[\hat{y} = b + a \cdot d\]
The predicted value takes only two values:
\[\hat{y}_i = \begin{cases}
b + a & \text{if } d_i = 1 \\
b & \text{if } d_i = 0
\end{cases}\]
Key result: For OLS regression:
\(b = \bar{y}_0\) (mean of \(y\) when \(d=0\))
\(a = \bar{y}_1 - \bar{y}_0\) (difference in means)
Interpretation: The slope coefficient equals the difference in group means.
Example: Earnings and Gender
Let’s examine whether there’s a gender earnings gap.
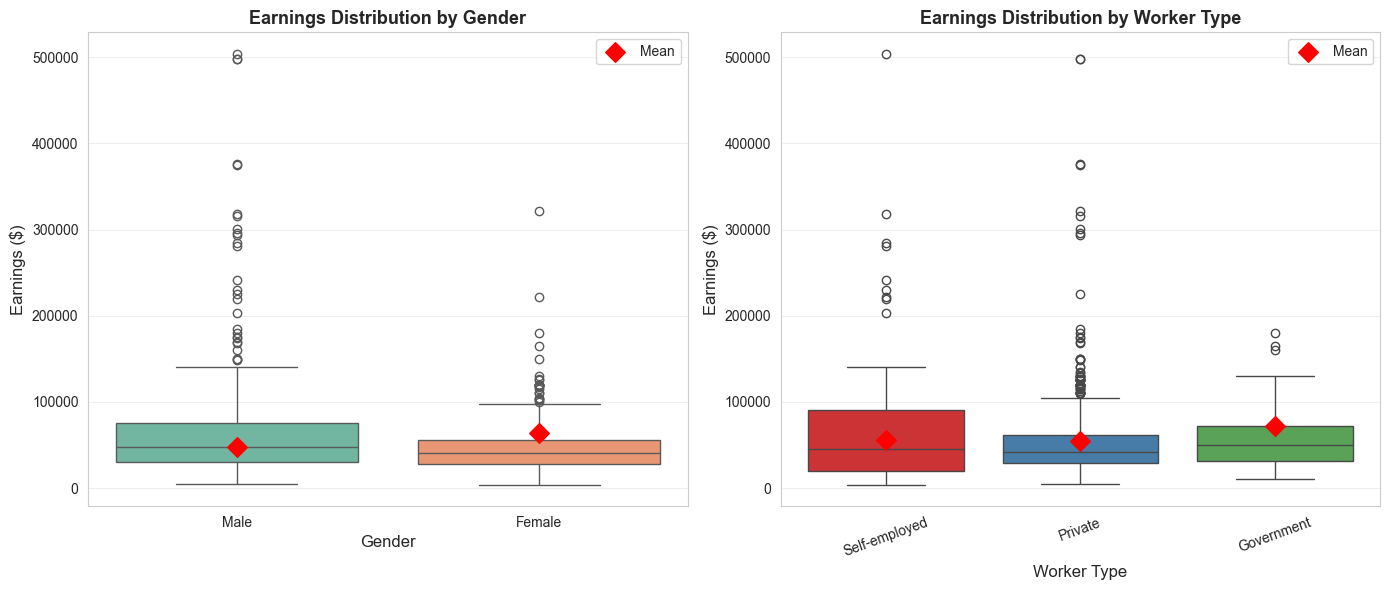
print("="*70)print("14.1: REGRESSION ON SINGLE INDICATOR VARIABLE")print("="*70)# Summary statistics by genderprint("\nTable 14.1: Earnings by Gender")print("-"*70)print("\nFemale (gender=1):")female_stats = data[data['gender'] ==1]['earnings'].describe()print(female_stats)print("\nMale (gender=0):")male_stats = data[data['gender'] ==0]['earnings'].describe()print(male_stats)# Calculate meansmean_female = data[data['gender'] ==1]['earnings'].mean()mean_male = data[data['gender'] ==0]['earnings'].mean()diff_means = mean_female - mean_maleprint("\n"+"-"*70)print("Difference in Means")print("-"*70)print(f" Mean earnings (Female): ${mean_female:,.2f}")print(f" Mean earnings (Male): ${mean_male:,.2f}")print(f" Difference: ${diff_means:,.2f}")print(f"\n Interpretation: Females earn ${abs(diff_means):,.2f} less than males on average.")
======================================================================
14.1: REGRESSION ON SINGLE INDICATOR VARIABLE
======================================================================
Table 14.1: Earnings by Gender
----------------------------------------------------------------------
Female (gender=1):
count 378.000000
mean 47079.894531
std 31596.724609
min 4000.000000
25% 27475.000000
50% 41000.000000
75% 56000.000000
max 322000.000000
Name: earnings, dtype: float64
Male (gender=0):
count 494.000000
mean 63476.316406
std 61713.210938
min 5000.000000
25% 30000.000000
50% 48000.000000
75% 75000.000000
max 504000.000000
Name: earnings, dtype: float64
----------------------------------------------------------------------
Difference in Means
----------------------------------------------------------------------
Mean earnings (Female): $47,079.89
Mean earnings (Male): $63,476.32
Difference: $-16,396.42
Interpretation: Females earn $16,396.42 less than males on average.
Key Concept 14.1: Indicator Variables and Difference in Means
When regressing \(y\) on just an intercept and a single indicator \(d\), the fitted model is \(\hat{y} = b + ad\). The intercept \(b\) equals the mean of \(y\) when \(d=0\), and the slope \(a\) equals the difference in means \((\bar{y}_1 - \bar{y}_0)\). Thus, regression on an indicator variable is equivalent to a difference-in-means test.
Understanding the Gender Earnings Gap
The regression results reveal a statistically significant gender earnings gap of approximately -$16,000. Let’s break down what this means:
Key Findings:
Intercept (\(b_1\)) ≈ $68,000: This represents the mean earnings for males (when gender = 0). We can verify this matches the actual mean earnings for males in the sample.
Gender coefficient (\(\alpha\)) ≈ -$16,000: This is the difference in mean earnings between females and males. Specifically:
Females earn approximately $16,000 less than males on average
This is the unconditional (raw) gender gap - it doesn’t account for differences in education, experience, or other factors
Statistical Significance: The t-statistic is highly significant (p < 0.001), meaning we can confidently reject the null hypothesis that there’s no gender difference in earnings.
Important Interpretation:
This regression simply decomposes the sample into two groups and compares their means
The coefficient on gender equals the difference: \(\bar{y}_{female} - \bar{y}_{male}\)
This is a descriptive finding, not necessarily causal - the gap may reflect differences in education, occupation, hours worked, discrimination, or other factors
To understand the adjusted gender gap (controlling for observable characteristics), we need to add additional regressors
Connection to t-test:
This regression is mathematically equivalent to a two-sample t-test
The regression framework allows us to easily extend the model by adding control variables
Comparison with t-test
Regression with a single indicator variable is equivalent to a two-sample t-test.
Two approaches:
Welch’s t-test (unequal variances): Similar to regression with robust SEs
Classical t-test (equal variances): Identical to regression with default SEs
print("\n"+"="*70)print("Comparison with t-tests")print("="*70)# Extract earnings by genderfemale_earnings = data[data['gender'] ==1]['earnings']male_earnings = data[data['gender'] ==0]['earnings']# Welch's t-test (unequal variances)print("\n1. Welch's t-test (unequal variances):")print("-"*70)t_stat_welch, p_value_welch = stats.ttest_ind(female_earnings, male_earnings, equal_var=False)print(f" t-statistic: {t_stat_welch:.4f}")print(f" p-value: {p_value_welch:.6f}")print(f" Note: Similar to regression with robust SEs")# Classical t-test (equal variances)print("\n2. Classical t-test (equal variances):")print("-"*70)t_stat_classical, p_value_classical = stats.ttest_ind(female_earnings, male_earnings, equal_var=True)print(f" t-statistic: {t_stat_classical:.4f}")print(f" p-value: {p_value_classical:.6f}")# Regression with default SEsprint("\n3. Regression with default (homoskedastic) SEs:")print("-"*70)model_gender_default = ols('earnings ~ gender', data=data).fit()print(f" t-statistic: {model_gender_default.tvalues['gender']:.4f}")print(f" p-value: {model_gender_default.pvalues['gender']:.6f}")print(f" Note: IDENTICAL to classical t-test with equal variances")print("\n"+"-"*70)print("Key insight:")print(" - Classical t-test = Regression with default SEs (assuming equal variances)")print(" - Welch's t-test ≈ Regression with robust SEs (allowing unequal variances)")
======================================================================
Comparison with t-tests
======================================================================
1. Welch's t-test (unequal variances):
----------------------------------------------------------------------
t-statistic: -5.0964
p-value: 0.000000
Note: Similar to regression with robust SEs
2. Classical t-test (equal variances):
----------------------------------------------------------------------
t-statistic: -4.7139
p-value: 0.000003
3. Regression with default (homoskedastic) SEs:
----------------------------------------------------------------------
t-statistic: -4.7139
p-value: 0.000003
Note: IDENTICAL to classical t-test with equal variances
----------------------------------------------------------------------
Key insight:
- Classical t-test = Regression with default SEs (assuming equal variances)
- Welch's t-test ≈ Regression with robust SEs (allowing unequal variances)
Having established the equivalence between regression on a single indicator and difference-in-means tests, we now add continuous control variables.
Key Concept 14.2: Regression vs. Specialized Test Methods
Specialized difference-in-means methods (like Welch’s t-test) and regression on an indicator give the same point estimate but slightly different standard errors. Regression uses \(se(\hat{a})\) from the model, while the t-test uses \(se(\bar{y}_1 - \bar{y}_0) = \sqrt{s_1^2/n_1 + s_0^2/n_0}\). Both are valid; regression is more flexible when adding control variables.
14.2: Indicator Variable with Additional Regressors
The raw difference in earnings by gender may be partly explained by other factors (e.g., education, experience, hours worked).
/Users/carlosmendez/miniforge3/lib/python3.10/site-packages/statsmodels/base/model.py:1912: FutureWarning: The behavior of wald_test will change after 0.14 to returning scalar test statistic values. To get the future behavior now, set scalar to True. To silence this message while retaining the legacy behavior, set scalar to False.
warnings.warn(
Key Concept 14.3: Interaction Terms Between Indicators and Continuous Variables
An interacted indicator variable is the product of an indicator and a continuous regressor, such as \(d \times x\). In the model \(y = \beta_1 + \beta_2 x + \alpha_1 d + \alpha_2(d \times x) + u\), the coefficient \(\alpha_2\) measures how the slope on \(x\) differs between groups. Including only \(d\) (without interaction) shifts the intercept but keeps slopes parallel. Adding the interaction allows both intercepts and slopes to vary.
How the Gender Gap Changes with Controls
Comparing the five models reveals how the estimated gender gap evolves as we add controls and interactions:
Model Evolution:
Model 1 (Gender only): Gap = -$16,000
This is the raw, unconditional gender earnings gap
Ignores all other factors that might explain earnings differences
Model 2 (+ Education): Gap shrinks to approximately -$10,000
Adding education as a control reduces the gender coefficient by ~$6,000
Interpretation: Part of the raw gap is explained by gender differences in education levels
The remaining -$10,000 is the gap conditional on education
Model 3 (+ Gender × Education):
Now gender enters through two channels: the main effect AND the interaction
The main gender coefficient becomes the gap when education = 0 (not very meaningful)
The interaction coefficient shows whether returns to education differ by gender
Joint F-test is crucial: Test both coefficients together to assess overall gender effects
Model 4 (+ Age, Hours): Further controls
Adding age and hours worked provides more refined estimates
These are important determinants of earnings that may differ by gender
Gap continues to shrink as we account for more observable differences
Model 5 (Full Interactions): Most flexible specification
Allows gender to affect the intercept AND slopes of all variables
Tests whether returns to education, age, and hours differ by gender
Joint F-test on all 4 gender terms is highly significant
Key Insights:
The gender gap decreases substantially when we control for education, age, and hours worked
From -$16,000 (unconditional) to approximately -$5,000 to -$8,000 (conditional)
This suggests observable characteristics explain part, but not all of the gap
======================================================================
Summary Table: All Five Models
======================================================================
Model 1 Model 2 Model 3 Model 4 Model 5
Description Gender only + Education + Gender×Educ + Age, Hours Full Interact
Gender Coef -16396.423634 -18258.087589 20218.796285 19021.708451 57128.997253
Robust SE 3217.429112 3136.141829 15355.179322 14994.357587 31917.144603
t-stat -5.096126 -5.821831 1.316741 1.268591 1.789916
N 872.0 872.0 872.0 872.0 872.0
R² 0.024906 0.133961 0.139508 0.197852 0.202797
Adj R² 0.023785 0.131968 0.136534 0.19322 0.196338
RMSE 50899.716833 47996.599413 47870.196751 46272.189032 46182.684141
Key observations:
- Gender coefficient magnitude changes as we add controls
- R² increases with additional variables
- Interactions capture differential effects across groups
Now that we can model different slopes via interaction terms, let’s test whether the entire regression structure differs by group.
Key Concept 14.4: Joint Significance Testing for Indicator Variables
When an indicator and its interaction with another variable are both included, test their joint significance using an F-test rather than individual t-tests. The joint test \(H_0: \alpha_1 = 0, \alpha_2 = 0\) evaluates whether the categorical variable matters at all. Individual t-tests can be misleading when the indicator and interaction are correlated.
14.4: Testing for Structural Change - Separate Regressions
An alternative to including interactions is to estimate separate regressions for each group.
print("\n"+"="*70)print("14.4: TESTING FOR STRUCTURAL CHANGE")print("="*70)print("\nSeparate Regressions by Gender")print("-"*70)# Female regressionmodel_female = ols('earnings ~ education + age + hours', data=data[data['gender'] ==1]).fit(cov_type='HC1')print("\nFemale subsample:")print(f" N = {int(model_female.nobs)}")print(f" Intercept: {model_female.params['Intercept']:,.2f}")print(f" Education: {model_female.params['education']:,.2f}")print(f" Age: {model_female.params['age']:,.2f}")print(f" Hours: {model_female.params['hours']:,.2f}")print(f" R²: {model_female.rsquared:.4f}")# Male regressionmodel_male = ols('earnings ~ education + age + hours', data=data[data['gender'] ==0]).fit(cov_type='HC1')print("\nMale subsample:")print(f" N = {int(model_male.nobs)}")print(f" Intercept: {model_male.params['Intercept']:,.2f}")print(f" Education: {model_male.params['education']:,.2f}")print(f" Age: {model_male.params['age']:,.2f}")print(f" Hours: {model_male.params['hours']:,.2f}")print(f" R²: {model_male.rsquared:.4f}")# Compare coefficientsprint("\n"+"-"*70)print("Comparison of Coefficients")print("-"*70)comparison = pd.DataFrame({'Female': model_female.params,'Male': model_male.params,'Difference': model_female.params - model_male.params})print(comparison)print("\nKey findings:")print(f" - Returns to education: ${model_female.params['education']:,.0f} (F) vs ${model_male.params['education']:,.0f} (M)")print(f" - Returns to age: ${model_female.params['age']:,.0f} (F) vs ${model_male.params['age']:,.0f} (M)")print(f" - Returns to hours: ${model_female.params['hours']:,.0f} (F) vs ${model_male.params['hours']:,.0f} (M)")
======================================================================
14.4: TESTING FOR STRUCTURAL CHANGE
======================================================================
Separate Regressions by Gender
----------------------------------------------------------------------
Female subsample:
N = 378
Intercept: -63,302.57
Education: 4,191.16
Age: 500.14
Hours: 691.24
R²: 0.1746
Male subsample:
N = 494
Intercept: -120,431.57
Education: 6,314.67
Age: 549.47
Hours: 1,620.81
R²: 0.1840
----------------------------------------------------------------------
Comparison of Coefficients
----------------------------------------------------------------------
Female Male Difference
Intercept -63302.571150 -120431.568403 57128.997253
education 4191.161688 6314.673007 -2123.511319
age 500.142383 549.474999 -49.332616
hours 691.239562 1620.814163 -929.574601
Key findings:
- Returns to education: $4,191 (F) vs $6,315 (M)
- Returns to age: $500 (F) vs $549 (M)
- Returns to hours: $691 (F) vs $1,621 (M)
Key Concept 14.5: Testing for Structural Change
Running separate regressions for each group allows all coefficients to differ simultaneously. The Chow test evaluates whether pooling the data (imposing the same coefficients for both groups) is justified. If the F-test rejects the null, the relationship between \(y\) and \(x\) differs fundamentally across groups – not just in intercept or one slope, but throughout the model.
14.5: Sets of Indicator Variables (Multiple Categories)
Often we have categorical variables with more than two categories.
Example: Type of Worker
Self-employed (dself = 1)
Private sector employee (dprivate = 1)
Government employee (dgovt = 1)
These are mutually exclusive: each person falls into exactly one category.
The Dummy Variable Trap
Since the three indicators sum to 1 (\(d1 + d2 + d3 = 1\)), we cannot include all three plus an intercept.
Solution: Drop one indicator (the reference category or base category).
The coefficient of an included indicator measures the difference relative to the base category.
Three Equivalent Approaches
Include intercept, drop one indicator (most common)
Drop intercept, include all indicators (coefficients = group means)
Change which indicator is dropped (changes interpretation, not fit)
print("="*70)print("SETS OF INDICATOR VARIABLES: Worker Type")print("="*70)# Approach 1: Include intercept, drop one indicator (dprivate as reference)print("\nApproach 1: Intercept + dself + dgovt (dprivate is reference)")print("-"*70)model_worker1 = ols('earnings ~ dself + dgovt + education + age', data=data).fit(cov_type='HC1')print(model_worker1.summary())# Approach 2: Drop intercept, include all indicatorsprint("\nApproach 2: No intercept + all dummies (dself + dprivate + dgovt)")print("-"*70)model_worker2 = ols('earnings ~ dself + dprivate + dgovt + education + age - 1', data=data).fit(cov_type='HC1')print(model_worker2.summary())# Approach 3: Different reference category (dself as reference)print("\nApproach 3: Intercept + dprivate + dgovt (dself is reference)")print("-"*70)model_worker3 = ols('earnings ~ dprivate + dgovt + education + age', data=data).fit(cov_type='HC1')print(model_worker3.summary())print("\n"+"-"*70)print("Key Insight:")print("-"*70)print(f" All three models have IDENTICAL R²: {model_worker1.rsquared:.4f}")print(f" Only the interpretation changes (different reference category)")print(f" Fitted values and residuals are the same across all three")
The dummy variable trap occurs when including all \(C\) indicators from a set of mutually exclusive categories plus an intercept. Since \(d_1 + d_2 + \cdots + d_C = 1\), this creates perfect multicollinearity – the intercept is an exact linear combination of the indicators. Solution: Drop one indicator (the “base category”) or drop the intercept. Standard practice is to keep the intercept and drop one indicator.
Understanding the Dummy Variable Trap
The results above demonstrate a fundamental principle in regression with categorical variables:
The Dummy Variable Trap Explained:
When we have \(k\) mutually exclusive categories (e.g., 3 worker types), we face perfect multicollinearity: \[d_{self} + d_{private} + d_{govt} = 1 \text{ (for every observation)}\]
This means one dummy is a perfect linear combination of the others plus the constant!
Three Equivalent Solutions:
Include intercept, drop one dummy (Standard approach)
Intercept = mean for the omitted (reference) category
Each coefficient = difference from reference category
Most common and easiest to interpret
Drop intercept, include all dummies (No-constant model)
Each coefficient = mean for that category
No reference category needed
Useful when you want group means directly
Change which dummy is dropped (Different reference)
All three models have identical fit (same R², predictions, residuals)
Only interpretation changes (different reference group)
Choose based on what comparison is most meaningful
Empirical Results from Worker Type Example:
From the three specifications above:
R² is identical across all specifications (≈ 0.16-0.17)
Joint F-tests give the same result (testing if worker type matters)
Only the individual coefficients change (but they measure different things)
Example Interpretation:
If reference = Private sector:
\(d_{self}\) coefficient ≈ -$5,000: Self-employed earn $5,000 less than private sector
\(d_{govt}\) coefficient ≈ +$2,000: Government workers earn $2,000 more than private sector
If reference = Self-employed:
\(d_{private}\) coefficient ≈ +$5,000: Private sector earns $5,000 more than self-employed
\(d_{govt}\) coefficient ≈ +$7,000: Government workers earn $7,000 more than self-employed
Notice: The difference between govt and private is the same in both (≈ $7,000 - $5,000 = $2,000)!
Practical Advice:
Choose the largest or most common category as reference
Or choose the policy-relevant comparison (e.g., treatment vs. control)
Always clearly state which category is omitted
Report joint F-test for overall significance of the categorical variable
ANOVA: Testing Equality of Means Across Groups
Analysis of Variance (ANOVA) tests whether means differ across multiple groups.
\[H_0: \mu_1 = \mu_2 = \mu_3 \quad \text{vs.} \quad H_a: \text{at least one mean differs}\]
ANOVA is equivalent to an F-test in regression with indicator variables.
print("\n"+"="*70)print("ANOVA: Testing Equality of Means Across Worker Types")print("="*70)# Create categorical variable for worker typedata['typeworker'] = (1* data['dself'] +2* data['dprivate'] +3* data['dgovt']).astype(int)print("\nMeans by worker type:")means_by_type = data.groupby('typeworker')['earnings'].agg(['mean', 'std', 'count'])means_by_type.index = ['Self-employed', 'Private', 'Government']print(means_by_type)# One-way ANOVA using scipyprint("\n"+"-"*70)print("One-way ANOVA (scipy)")print("-"*70)group1 = data[data['typeworker'] ==1]['earnings']group2 = data[data['typeworker'] ==2]['earnings']group3 = data[data['typeworker'] ==3]['earnings']f_stat_anova, p_value_anova = f_oneway(group1, group2, group3)print(f" F-statistic: {f_stat_anova:.2f}")print(f" p-value: {p_value_anova:.6f}")if p_value_anova <0.05:print(f"\n Result: Reject H₀ - Earnings differ significantly across worker types")else:print(f"\n Result: Fail to reject H₀ - No significant difference in earnings")# Using statsmodels for detailed ANOVA tableprint("\n"+"-"*70)print("Detailed ANOVA table (statsmodels)")print("-"*70)model_anova = ols('earnings ~ C(typeworker)', data=data).fit()anova_table = anova_lm(model_anova, typ=2)print(anova_table)print("\nNote: ANOVA F-statistic matches the joint test from regression")
======================================================================
ANOVA: Testing Equality of Means Across Worker Types
======================================================================
Means by worker type:
mean std count
Self-employed 72306.328125 86053.131086 79
Private 54521.265625 48811.203104 663
Government 56105.382812 32274.679426 130
----------------------------------------------------------------------
One-way ANOVA (scipy)
----------------------------------------------------------------------
F-statistic: 4.24
p-value: 0.014708
Result: Reject H₀ - Earnings differ significantly across worker types
----------------------------------------------------------------------
Detailed ANOVA table (statsmodels)
----------------------------------------------------------------------
sum_sq df F PR(>F)
C(typeworker) 2.233847e+10 2.0 4.239916 0.014708
Residual 2.289212e+12 869.0 NaN NaN
Note: ANOVA F-statistic matches the joint test from regression
Having covered the statistical framework for indicator variables, let’s visualize these group differences graphically.
Key Concept 14.7: ANOVA as Regression on Indicators
Regressing \(y\) on a set of mutually exclusive indicators (with no other controls) is equivalent to analysis of variance (ANOVA). Coefficients give group means or differences from the base mean. The regression F-test for joint significance of the indicators is identical to the ANOVA F-statistic, testing whether the categorical variable explains significant variation in \(y\).
Visualizations
Let’s create informative visualizations to illustrate our findings.
print("\n"+"="*70)print("VISUALIZATIONS")print("="*70)# Figure 1: Earnings by gender and worker typefig, axes = plt.subplots(1, 2, figsize=(14, 6))# Panel 1: Box plot by genderdata['Gender'] = data['gender'].map({0: 'Male', 1: 'Female'})sns.boxplot(x='Gender', y='earnings', data=data, ax=axes[0], palette='Set2')axes[0].set_ylabel('Earnings ($)', fontsize=12)axes[0].set_xlabel('Gender', fontsize=12)axes[0].set_title('Earnings Distribution by Gender', fontsize=13, fontweight='bold')axes[0].grid(True, alpha=0.3, axis='y')# Add mean markersmeans_gender = data.groupby('Gender')['earnings'].mean()axes[0].scatter([0, 1], means_gender.values, color='red', s=100, zorder=5, marker='D', label='Mean')axes[0].legend()# Panel 2: Box plot by worker typedata['Worker Type'] = data['typeworker'].map({1: 'Self-employed', 2: 'Private', 3: 'Government'})sns.boxplot(x='Worker Type', y='earnings', data=data, ax=axes[1], palette='Set1')axes[1].set_ylabel('Earnings ($)', fontsize=12)axes[1].set_xlabel('Worker Type', fontsize=12)axes[1].set_title('Earnings Distribution by Worker Type', fontsize=13, fontweight='bold')axes[1].tick_params(axis='x', rotation=20)axes[1].grid(True, alpha=0.3, axis='y')# Add mean markersmeans_type = data.groupby('Worker Type')['earnings'].mean()axes[1].scatter([0, 1, 2], means_type.values, color='red', s=100, zorder=5, marker='D', label='Mean')axes[1].legend()plt.tight_layout()plt.show()print("Figure 14.1: Earnings distributions show variation by gender and worker type.")
/var/folders/tq/t98kb27n6djgrh085g476yhc0000gn/T/ipykernel_14658/4086298910.py:10: FutureWarning:
Passing `palette` without assigning `hue` is deprecated and will be removed in v0.14.0. Assign the `x` variable to `hue` and set `legend=False` for the same effect.
sns.boxplot(x='Gender', y='earnings', data=data, ax=axes[0], palette='Set2')
/var/folders/tq/t98kb27n6djgrh085g476yhc0000gn/T/ipykernel_14658/4086298910.py:23: FutureWarning:
Passing `palette` without assigning `hue` is deprecated and will be removed in v0.14.0. Assign the `x` variable to `hue` and set `legend=False` for the same effect.
sns.boxplot(x='Worker Type', y='earnings', data=data, ax=axes[1], palette='Set1')
Figure 14.1: Earnings distributions show variation by gender and worker type.
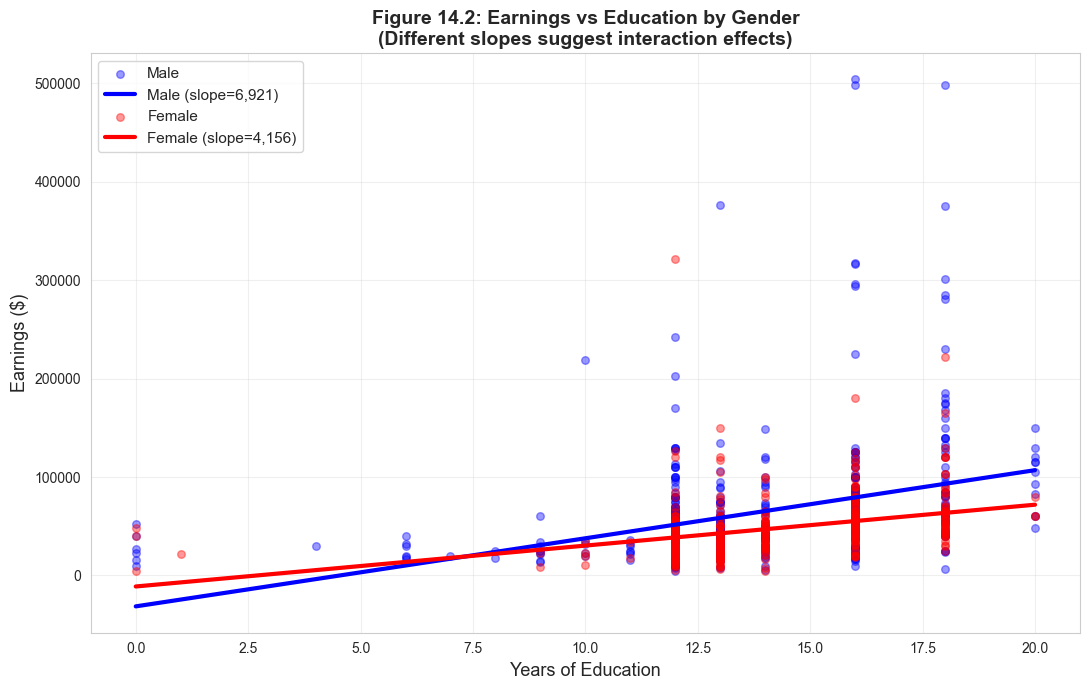
# Figure 2: Earnings vs education by gender (with regression lines)fig, ax = plt.subplots(figsize=(11, 7))for gender, label, color in [(0, 'Male', '#22d3ee'), (1, 'Female', 'red')]: subset = data[data['gender'] == gender] ax.scatter(subset['education'], subset['earnings'], alpha=0.4, label=label, s=30, color=color)# Add regression line z = np.polyfit(subset['education'], subset['earnings'], 1) p = np.poly1d(z) edu_range = np.linspace(subset['education'].min(), subset['education'].max(), 100) ax.plot(edu_range, p(edu_range), linewidth=3, color=color, label=f'{label} (slope={z[0]:,.0f})')ax.set_xlabel('Years of Education', fontsize=13)ax.set_ylabel('Earnings ($)', fontsize=13)ax.set_title('Figure 14.2: Earnings vs Education by Gender\n(Different slopes suggest interaction effects)', fontsize=14, fontweight='bold')ax.legend(fontsize=11, loc='upper left')ax.grid(True, alpha=0.3)plt.tight_layout()plt.show()print("\nThe different slopes indicate that returns to education vary by gender.")print("This justifies including the gender × education interaction term.")
The different slopes indicate that returns to education vary by gender.
This justifies including the gender × education interaction term.
Key Concept 14.8: Visualizing Group Differences in Regression
Scatter plots with separate regression lines by group visually reveal whether slopes and intercepts differ. Parallel lines indicate only an intercept shift (indicator without interaction), while non-parallel lines indicate differential slopes (interaction term needed). Box plots complement this by showing the distribution of \(y\) across categories.
Key Takeaways
Indicator Variables Basics
Indicator variables (dummy variables) are binary variables that equal 1 if an observation is in a specific category and 0 otherwise
They allow regression models to incorporate categorical information such as gender, employment type, or region
Interpretation differs from continuous variables – coefficients represent group differences rather than marginal effects
Regression on a Single Indicator and Difference in Means
When regressing \(y\) on just an intercept and a single indicator \(d\), the fitted model is \(\hat{y} = b + ad\)
The intercept \(b\) equals the mean of \(y\) when \(d=0\) (the reference group)
The slope \(a\) equals the difference in means: \(a = \bar{y}_1 - \bar{y}_0\)
Regression on an indicator is mathematically equivalent to a two-sample difference-in-means test
Regression and specialized t-tests give the same estimate but slightly different standard errors
Example: Women earn $16,396 less than men on average (\(t = -4.71\), highly significant)
Indicators with Controls and Interaction Terms
Adding an indicator to a regression with continuous variables measures the group difference after controlling for other factors
Including only the indicator shifts the intercept but keeps slopes parallel across groups
An interaction term\(d \times x\) allows slopes to differ by group (non-parallel lines)
The interaction coefficient measures how the effect of \(x\) on \(y\) differs between groups
Always use joint F-tests to test significance of both the indicator and its interaction together
Dummy Variable Trap and Base Category
The dummy variable trap occurs when including all \(C\) indicators from a mutually exclusive set plus an intercept
Since \(d_1 + d_2 + \cdots + d_C = 1\), this creates perfect multicollinearity
Solution: Drop one indicator (the “base category”) or drop the intercept
The base category is the reference group – coefficients on included indicators measure differences from the base
Choice of base category does not affect statistical conclusions, only interpretation
Hypothesis Testing with Indicator Sets
A t-test on a single indicator tests whether that category differs from the base category
An F-test on all \(C-1\) included indicators tests whether the categorical variable matters overall
The F-test result is the same regardless of which category is dropped (invariant to base choice)
Regressing \(y\) on mutually exclusive indicators without controls is equivalent to ANOVA
Always use F-tests to evaluate the overall significance of a categorical variable
General Lessons
Indicator variables unify many statistical tests (t-tests, ANOVA) in a single regression framework
Always use heteroskedastic-robust standard errors for valid inference
Interactions with continuous variables allow relationships to vary by group
Regression flexibility: add controls, test interactions, compare models – all within one framework
Congratulations! You’ve completed Chapter 14. You now understand how to incorporate categorical variables into regression analysis, interpret indicator coefficients, test for group differences, and use interactions to model differential effects across categories.
Practice Exercises
Exercise 1: Interpreting Indicator Regression
OLS regression of \(y\) on an intercept and indicator \(d\) using all data yields \(\hat{y} = 3 + 5d\).
(a) What is \(\bar{y}\) for the subsample with \(d = 0\)?
(b) What is \(\bar{y}\) for the subsample with \(d = 1\)?
(c) What does the coefficient 5 represent?
Exercise 2: Constructing from Means
Suppose \(\bar{y} = 30\) for the subsample with \(d = 1\) and \(\bar{y} = 20\) for the subsample with \(d = 0\).
(a) Give the fitted model from OLS regression of \(y\) on an intercept and \(d\) using the full sample.
(b) Is the difference in means statistically significant? What additional information would you need?
Exercise 3: Multiple Indicators
We have three mutually exclusive indicator variables \(d_1\), \(d_2\), and \(d_3\). OLS yields \(\hat{y} = 1 + 3d_2 + 5d_3\).
(a) What is the estimated mean of \(y\) for each category?
(b) What is the estimated difference between category 2 (\(d_2 = 1\)) and category 1 (\(d_1 = 1\))?
(c) Which category is the base (omitted) category?
Exercise 4: Changing Base Category
For the model in Exercise 3, give the coefficient estimates if instead we regressed \(y\) on an intercept, \(d_1\), and \(d_2\) (dropping \(d_3\) instead of \(d_1\)).
Exercise 5: Interaction Interpretation
A regression of earnings on education, gender, and their interaction yields:
(a) Write the fitted equation for males and for females separately.
(b) What is the returns to education for males? For females?
(c) At what education level does the gender earnings gap equal zero?
Exercise 6: Joint F-Test
A researcher includes a gender indicator and a gender-education interaction in a regression. The t-statistic on the gender indicator is \(t = -1.5\) (not significant at 5%) and the t-statistic on the interaction is \(t = -1.8\) (not significant at 5%).
(a) Can we conclude that gender does not matter for earnings? Why or why not?
(b) What test should we conduct instead? What would you expect to find?
(c) Explain why individual t-tests can be misleading when testing the significance of indicator variables with interactions.
Case Studies
Case Study 1: Regional Indicator Variables for Cross-Country Productivity
In this case study, you will apply indicator variable techniques to analyze how labor productivity differs across world regions and whether the determinants of productivity vary by region.
Dataset: Mendez Convergence Clubs
import pandas as pdurl ="https://raw.githubusercontent.com/quarcs-lab/mendez2020-convergence-clubs-code-data/master/assets/dat.csv"dat = pd.read_csv(url)dat2014 = dat[dat['year'] ==2014].copy()
Variables:lp (labor productivity), rk (physical capital), hc (human capital), region (world region)
Task 1: Create Regional Indicators and Compute Means (Guided)
Create indicator variables for each region and compute mean log productivity by region.
# Create indicator variables from the region columnregion_dummies = pd.get_dummies(dat2014['region'], prefix='region', drop_first=False)dat2014 = pd.concat([dat2014, region_dummies], axis=1)# Compute mean log productivity by regionimport numpy as npdat2014['ln_lp'] = np.log(dat2014['lp'])print(dat2014.groupby('region')['ln_lp'].agg(['mean', 'count']))
Questions: How many regions are there? Which region has the highest average productivity? The lowest?
Task 2: Regression on Regional Indicators (Guided)
Regress log productivity on regional indicators (using one region as the base category).
import statsmodels.formula.api as smfmodel1 = smf.ols('ln_lp ~ C(region)', data=dat2014).fit(cov_type='HC1')print(model1.summary())
Questions: Which region is the base category? How do you interpret the coefficients? Are the regional differences statistically significant?
Key Concept 14.9: Regional Indicators as Difference in Means
When regressing \(y\) on a set of regional indicators without controls, each coefficient measures the difference in mean\(y\) between that region and the base region. The F-test for joint significance tests whether there are any significant productivity differences across regions.
Task 3: Add Continuous Controls (Semi-guided)
Add physical capital and human capital as continuous controls. Observe how regional coefficients change.
Hints:
Use ln_lp ~ C(region) + np.log(rk) + hc as the formula
Compare regional coefficients with and without controls
What does it mean when regional gaps shrink after adding controls?
Task 4: Regional Interactions (Semi-guided)
Add an interaction between region and human capital to test whether the returns to human capital differ by region.
Hints:
Use ln_lp ~ C(region) * hc + np.log(rk) to include all region-hc interactions
How do you interpret the interaction coefficients?
Do the returns to human capital differ significantly across regions?
Key Concept 14.10: Interaction Terms for Regional Heterogeneity
Interaction terms between regional indicators and continuous variables allow the slope of a regressor to differ by region. A significant interaction indicates that the effect of human capital (or physical capital) on productivity is not uniform across all regions – some regions benefit more from the same increase in inputs.
Task 5: Joint F-Tests for Regional Effects (Independent)
Conduct joint F-tests to evaluate:
Whether regional indicators are jointly significant (with and without controls)
Whether the regional interaction terms are jointly significant
Compare the explanatory power of models with and without regional effects
Task 6: Policy Brief on Regional Disparities (Independent)
Write a 200-300 word brief addressing:
How large are regional productivity differences?
How much of the gap is explained by differences in physical and human capital?
Do the returns to human capital differ by region, and what are the policy implications?
What additional factors might explain remaining regional differences?
What You’ve Learned: You have applied indicator variable techniques to cross-country data, demonstrating that regional indicators capture systematic productivity differences that partially reflect differences in factor endowments. Interaction terms reveal that the returns to human capital vary across regions, with important implications for development policy.
Case Study 2: Urban-Rural and Regional Divides in Bolivian Development
In previous chapters, we estimated satellite-development regressions treating all Bolivian municipalities identically. But Bolivia’s nine departments span diverse geographies—from Andean highlands to Amazonian lowlands. In this case study, we apply Chapter 14’s indicator variable techniques to model regional differences in development levels and in the satellite-development relationship.
Research Question: Do development levels and the NTL-development relationship differ across Bolivia’s nine departments?
Dataset: DS4Bolivia
import pandas as pdurl_bol ="https://raw.githubusercontent.com/quarcs-lab/ds4bolivia/master/ds4bolivia_v20250523.csv"bol = pd.read_csv(url_bol)
Key variables:mun (municipality), dep (department), imds (Municipal Development Index, 0–100), ln_NTLpc2017 (log nighttime lights per capita)
Task 1: Create Indicators and Group Means (Guided)
Objective: Create department indicator variables and compare mean development across departments.
Instructions:
Load the DS4Bolivia dataset and select key variables
Use pd.get_dummies(bol['dep']) to create department indicators
Compute mean imds by department with groupby('dep')['imds'].agg(['mean', 'count'])
Which department has the highest mean IMDS? The lowest?
Run the code below to get started.
# Load DS4Bolivia dataseturl_bol ="https://raw.githubusercontent.com/quarcs-lab/ds4bolivia/master/ds4bolivia_v20250523.csv"bol = pd.read_csv(url_bol)# Select key variablesbol_key = bol[['mun', 'dep', 'imds', 'ln_NTLpc2017']].dropna().copy()print("="*70)print("DS4BOLIVIA: DEPARTMENT INDICATORS AND GROUP MEANS")print("="*70)print(f"Observations: {len(bol_key)} municipalities")print(f"Departments: {bol_key['dep'].nunique()}")# Create department indicator variablesdep_dummies = pd.get_dummies(bol_key['dep'])print(f"\nIndicator variables created: {list(dep_dummies.columns)}")# Mean IMDS by departmentprint("\n"+"-"*70)print("Mean IMDS by Department")print("-"*70)dept_stats = bol_key.groupby('dep')['imds'].agg(['mean', 'count']).sort_values('mean', ascending=False)print(dept_stats.round(2))print(f"\nHighest mean IMDS: {dept_stats['mean'].idxmax()} ({dept_stats['mean'].max():.2f})")print(f"Lowest mean IMDS: {dept_stats['mean'].idxmin()} ({dept_stats['mean'].min():.2f})")
======================================================================
DS4BOLIVIA: DEPARTMENT INDICATORS AND GROUP MEANS
======================================================================
Observations: 333 municipalities
Departments: 9
Indicator variables created: ['Beni', 'Chuquisaca', 'Cochabamba', 'La Paz', 'Oruro', 'Pando', 'Potosí', 'Santa Cruz', 'Tarija']
----------------------------------------------------------------------
Mean IMDS by Department
----------------------------------------------------------------------
mean count
dep
Tarija 60.60 11
Santa Cruz 54.31 55
Cochabamba 52.50 47
La Paz 50.98 87
Beni 50.79 18
Oruro 50.68 35
Chuquisaca 47.80 29
Potosí 47.57 38
Pando 45.92 13
Highest mean IMDS: Tarija (60.60)
Lowest mean IMDS: Pando (45.92)
Task 2: Regression on Department Indicators (Guided)
Objective: Regress IMDS on department indicators to quantify regional development differences.
# Your code here: Regression of IMDS on department indicators## Steps:# 1. Estimate model: imds ~ C(dep)# 2. Print summary# 3. Identify the base department and interpret coefficients## model_dep = ols('imds ~ C(dep)', data=bol_key).fit(cov_type='HC1')# print(model_dep.summary())## print(f"\nBase department: {sorted(bol_key['dep'].unique())[0]}")# print(f"Intercept = mean IMDS for the base department: {model_dep.params['Intercept']:.2f}")
Key Concept 14.9: Geographic Indicator Variables
Department indicators capture time-invariant regional characteristics that affect development: altitude, climate, proximity to borders, historical infrastructure investments, and cultural factors. By including department dummies, we control for these systematic regional differences, allowing us to estimate the NTL-development relationship within departments rather than across them. The coefficient on NTL then reflects how NTL variation within a department predicts development variation within that department.
Task 3: Add NTL Control (Semi-guided)
Objective: Compare department coefficients with and without the NTL control variable.
Instructions:
Estimate imds ~ C(dep) + ln_NTLpc2017
Compare department coefficients with those from Task 2 (without NTL)
Do department differences shrink when NTL is added?
What does this tell us about whether NTL explains part of the regional gap?
Hints:
If department coefficients shrink, it means part of the regional gap was due to differences in NTL intensity
If they remain large, departments differ for reasons beyond what NTL captures
# Your code here: Add NTL as a continuous control## Steps:# 1. Estimate: imds ~ C(dep) + ln_NTLpc2017# 2. Compare department coefficients with Task 2 results# 3. Interpret changes## model_dep_ntl = ols('imds ~ C(dep) + ln_NTLpc2017', data=bol_key).fit(cov_type='HC1')# print(model_dep_ntl.summary())## print("\nComparison: Do department coefficients shrink with NTL control?")# print("If yes, NTL explains part of the regional development gap.")
Task 4: Interaction Terms (Semi-guided)
Objective: Test whether the NTL-development slope differs across departments.
Interaction terms between department indicators and NTL allow the slope of the NTL-development relationship to differ across regions. This is economically meaningful: in highly urbanized departments (like La Paz or Cochabamba), additional nighttime lights may signal commercial activity, while in rural highland departments (like Potosi), lights primarily reflect basic electrification. A significant interaction indicates that the economic meaning of satellite signals varies by geographic context.
Task 5: Joint F-Test for Department Effects (Independent)
Objective: Test the joint significance of all department indicators and all interaction terms.
Instructions:
Test joint significance of all department indicators using an F-test
Also test joint significance of all interaction terms
Are regional differences significant? Do NTL effects significantly vary across regions?
Hints:
Use model.f_test() or compare restricted vs. unrestricted models
For interaction terms, compare the model with interactions to the model without
Report F-statistics and p-values for both tests
# Your code here: Joint F-tests for department effects## Steps:# 1. F-test for joint significance of department indicators# 2. F-test for joint significance of interaction terms# 3. Compare models with and without regional effects## Approach: Compare nested models using ANOVA# from statsmodels.stats.anova import anova_lm## model_base = ols('imds ~ ln_NTLpc2017', data=bol_key).fit()# model_dep_only = ols('imds ~ C(dep) + ln_NTLpc2017', data=bol_key).fit()# model_full = ols('imds ~ C(dep) * ln_NTLpc2017', data=bol_key).fit()## print("F-test: Department indicators (comparing base vs dep_only)")# print(anova_lm(model_base, model_dep_only))## print("\nF-test: Interaction terms (comparing dep_only vs full)")# print(anova_lm(model_dep_only, model_full))
Task 6: Regional Disparities Brief (Independent)
Objective: Write a 200–300 word brief on regional development disparities in Bolivia.
Your brief should address:
What are the main regional divides in Bolivian development?
How much do department indicators explain beyond NTL?
Does the satellite-development relationship differ across regions?
What are the policy implications for targeted regional interventions?
Use evidence from your analysis: Cite specific coefficients, R-squared values, and F-test results to support your arguments.
# Your code here: Additional analysis for the policy brief## You might want to:# 1. Create a summary table comparing R-squared across models# 2. Visualize department means with confidence intervals# 3. Plot separate NTL-IMDS regression lines by department# 4. Calculate specific statistics to cite in your brief## Example: Compare model fit# print("MODEL COMPARISON")# print(f" NTL only: R² = {model_base.rsquared:.4f}")# print(f" + Dept dummies: R² = {model_dep_only.rsquared:.4f}")# print(f" + Interactions: R² = {model_full.rsquared:.4f}")
What You’ve Learned from This Case Study
Through this analysis of regional development disparities in Bolivia, you have applied Chapter 14’s indicator variable techniques to a real geospatial dataset:
Indicator variable creation: Used pd.get_dummies() and C() to create department dummies
Department dummies in regression: Quantified development differences across Bolivia’s nine departments
Controlling for regional effects: Compared models with and without department indicators to assess how much of the NTL-development relationship reflects regional composition
Interaction terms: Tested whether the satellite-development slope differs across departments
Joint F-tests: Evaluated the overall significance of department effects and interaction terms
Policy interpretation: Connected statistical findings to regional development policy
Connection to next chapter: In Chapter 15, we explore nonlinear satellite-development relationships using log transformations, polynomials, and elasticities.
Well done! You’ve now analyzed both cross-country productivity data and Bolivian municipal development data using indicator variable techniques, demonstrating how geographic dummies capture systematic regional differences and how interactions reveal heterogeneous effects.