---
title: 1. Analysis of Economics Data
execute:
enabled: true
warning: false
---
**metricsAI: An Introduction to Econometrics with Python and AI in the Cloud**
*[Carlos Mendez](https://carlos-mendez.org)*
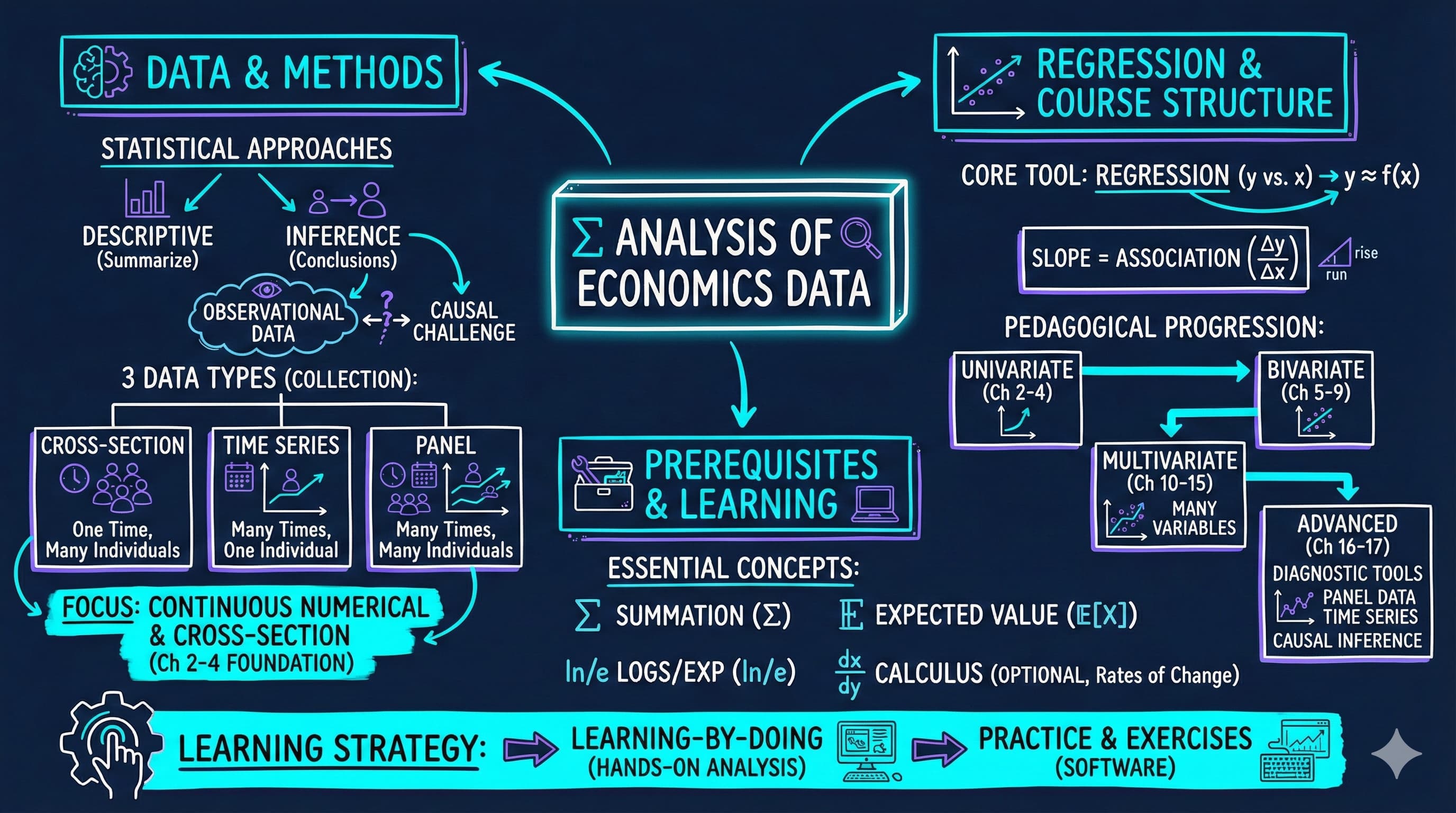
<img src="https://raw.githubusercontent.com/quarcs-lab/metricsai/main/images/ch01_visual_summary.jpg" alt="Chapter 01 Visual Summary" width="100%">
This notebook provides an interactive introduction to regression analysis using Python. You can run all code directly in Google Colab without any local setup required. The data streams directly from GitHub, making this notebook fully self-contained.
[](https://colab.research.google.com/github/quarcs-lab/metricsai/blob/main/notebooks_colab/ch01_Analysis_of_Economics_Data.ipynb)
<div class="chapter-resources">
<a href="https://www.youtube.com/watch?v=RyE01v-zliM" target="_blank" class="resource-btn">🎬 AI Video</a>
<a href="https://carlos-mendez.my.canva.site/s01-analysis-of-economics-data-pdf" target="_blank" class="resource-btn">✨ AI Slides</a>
<a href="https://cameron.econ.ucdavis.edu/aed/traedv1_01" target="_blank" class="resource-btn">📊 Cameron Slides</a>
<a href="https://app.edcafe.ai/quizzes/69715fdb60956f50e60276b9" target="_blank" class="resource-btn">✏️ Quiz</a>
<a href="https://app.edcafe.ai/chatbots/6971625960956f50e6028155" target="_blank" class="resource-btn">🤖 AI Tutor</a>
</div>
## Chapter Overview
This chapter introduces the fundamental concepts of econometrics and regression analysis. We'll explore how economists use statistical methods to understand relationships in economic data, focusing on a practical example of house prices and house sizes.
**What you'll learn:**
- What regression analysis is and why it's the primary tool in econometrics
- How to load and explore economic data using Python (pandas)
- How to visualize relationships between variables using scatter plots
- How to fit a simple linear regression model using Ordinary Least Squares (OLS)
- How to interpret regression coefficients in economic terms
- How to use Python's pyfixest package for regression analysis
**Dataset used:**
- **AED_HOUSE.DTA**: House sale prices for 29 houses in Central Davis, California (1999)
- Variables: price (sale price in dollars), size (house size in square feet), plus 6 other characteristics
**Chapter outline:**
- 1.1 What is Regression Analysis?
- 1.2 Load the Data
- 1.3 Preview the Data
- 1.4 Explore the Data
- 1.5 Visualizing the Relationship
- 1.6 Fitting a Regression Line
- 1.7 Interpreting the Results
- 1.8 Visualizing the Fitted Line
- 1.9 Economic Interpretation and Examples
- Practice Exercises
- Case Studies
## Key Concepts
Six core ideas anchor this chapter. Skim them before you start, and come back when a term feels fuzzy. Each entry pairs a concrete house-price example with a non-technical analogy. Click a panel to expand it.
**Regression Analysis:** A statistical method for quantifying how one variable changes when another variable changes. It produces a "line of best fit" through the data and reports the slope, intercept, and goodness of fit.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
For 29 houses in Davis, CA (1999), regression of `price` on `size` gives `price = 115,017 + 73.77 × size`. The slope says each extra square foot is associated with about \$74 more in sale price.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
Like fitting a single straight road through a scattered village. The road won't pass through every house, but it captures the general direction the houses are arranged in.
:::
::::
:::::
**Dependent and Independent Variables (Y and X):** The dependent variable (Y) is the outcome you want to explain or predict. The independent variable (X) is the input you use to explain it. The regression slope tells you how Y moves when X changes by one unit.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
Here Y = `price` (sale price in dollars) and X = `size` (square feet). We treat price as the thing being explained and size as the explainer — not the other way around. Reversing them would answer a different question ("how much bigger is a more-expensive house?").
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
Like a recipe: the amount of flour (X) helps explain how much bread you get (Y). Bread doesn't cause flour. Choosing which is X and which is Y is a modeling decision, not a fact about the world.
:::
::::
:::::
**Intercept ($\beta_0$) and Slope ($\beta_1$):** The intercept is the predicted value of Y when X = 0 — it anchors the regression line. The slope is the change in Y for a one-unit change in X — it is usually the coefficient you actually care about.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
In our fit, $\beta_0 \approx \$115{,}017$ (the predicted price of a 0-sqft house — not economically meaningful, just an anchor) and $\beta_1 \approx \$73.77$ per sqft (each additional square foot is associated with about \$74 more in price).
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
Like a taxi fare: the intercept is the flag-drop charge you pay just for getting in (\$5), and the slope is the per-mile rate (\$2/mile). The flag-drop alone is rarely the interesting number — the per-mile rate is.
:::
::::
:::::
**Ordinary Least Squares (OLS):** The standard method for choosing the regression line. OLS picks the intercept and slope that make the sum of *squared* vertical distances between the actual Y values and the fitted line as small as possible.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
For each of the 29 houses, the vertical gap between its dot and the fitted line is a residual. OLS chose $\beta_0 = 115{,}017$ and $\beta_1 = 73.77$ because no other line gives a smaller sum of *squared* residuals across those 29 houses.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
Like hanging a clothesline through a row of poles of different heights. You position the line so the total *squared* slack — pulled tight from every pole — is as small as possible. Squaring (rather than just adding) means a few far-off poles get penalized more than many slightly-off ones.
:::
::::
:::::
**R-squared ($R^2$):** The proportion of variation in Y that the regression explains, on a 0-to-1 scale. Higher $R^2$ means the line fits the points more tightly; it does **not** mean the relationship is causal.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
Our model has $R^2 \approx 0.62$. Size alone explains about 62% of the variation in house prices across these 29 houses. The remaining 38% comes from other things we didn't include — location, condition, age, lot size.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
Like a weather forecast that captures roughly 62% of what actually happens. A high $R^2$ means your one explanatory variable does most of the storytelling; a low $R^2$ means most of the story is happening off-stage in variables you haven't measured.
:::
::::
:::::
**Association vs. Causation:** Regression measures *association* — how Y and X move together in your sample. It does **not**, by itself, prove that changing X would change Y. Other variables (omitted, confounding, or reverse-causal) may drive both.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
The slope says larger houses sell for more — but bolting an extra 100 sqft onto your house won't necessarily add \$7,400 of value. Bigger houses also tend to be newer, in better neighborhoods, and more carefully renovated. Size is correlated with quality, and the regression credits size for quality's effect too.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
Ice-cream sales and drowning deaths both rise in summer. They are strongly *associated*. But banning ice cream would not save swimmers — both are caused by hot weather. Regression alone can't tell you which arrows in the causal diagram are real.
:::
::::
:::::
## Setup
Run this cell first to import all required packages and configure the environment. This sets up:
- Data manipulation (pandas, numpy)
- Statistical modeling (pyfixest)
- Visualization (matplotlib)
- Reproducibility (random seeds)
```{python}
#| code-fold: true
#| code-summary: "Setup: Import libraries and configure environment"
# --- Libraries ---
import numpy as np # numerical operations
import pandas as pd # data manipulation
import matplotlib.pyplot as plt # plotting
import pyfixest as pf # OLS regression (Python port of R's fixest)
import random
import os
# --- Reproducibility ---
RANDOM_SEED = 42
random.seed(RANDOM_SEED)
np.random.seed(RANDOM_SEED)
os.environ['PYTHONHASHSEED'] = str(RANDOM_SEED)
# --- Data source ---
GITHUB_DATA_URL = "https://raw.githubusercontent.com/quarcs-lab/data-open/master/AED/"
# --- Output directories (for saving figures/tables locally) ---
IMAGES_DIR = 'images'
TABLES_DIR = 'tables'
os.makedirs(IMAGES_DIR, exist_ok=True)
os.makedirs(TABLES_DIR, exist_ok=True)
# --- Plotting style (dark theme matching book design) ---
plt.style.use('dark_background')
plt.rcParams.update({
'axes.facecolor': '#1a2235',
'figure.facecolor': '#12162c',
'grid.color': '#3a4a6b',
'figure.figsize': (10, 6),
'text.color': 'white',
'axes.labelcolor': 'white',
'xtick.color': 'white',
'ytick.color': 'white',
'axes.edgecolor': '#1a2235',
})
print("✓ Setup complete! All packages imported successfully.")
print(f"✓ Random seed set to {RANDOM_SEED} for reproducibility.")
print(f"✓ Data will stream from: {GITHUB_DATA_URL}")
```
## 1.1 What is Regression Analysis?
Economists use **regression analysis** as their primary tool to understand relationships between variables. At its core, regression answers questions like: "How does Y change when X changes?"
In our example:
- **Y (dependent variable)**: House sale price (in dollars)
- **X (independent variable)**: House size (in square feet)
**The regression line** is the "line of best fit" that minimizes the sum of squared distances between actual prices and predicted prices. The mathematical form is:
$$\text{price} = \beta_0 + \beta_1 \times \text{size} + \varepsilon$$
Where:
- $\beta_0$ = **intercept** (predicted price when size = 0)
- $\beta_1$ = **slope** (change in price for each additional square foot)
- $\varepsilon$ = **error term** (random variation not explained by size)
**Economic Interpretation:**
The slope coefficient $\beta_1$ tells us: "On average, how much more expensive is a house that is 1 square foot larger?" This is a measure of **association**, not necessarily causation.
> **Key Concept 1.1: Descriptive vs. Inferential Analysis**
>
> Descriptive analysis summarizes data using statistics and visualizations, while statistical inference uses sample data to draw conclusions about the broader population. Most econometric analysis involves statistical inference.
## 1.2 Load the Data
Let's load the house price dataset directly from GitHub. This dataset contains information on 29 house sales in Central Davis, California in 1999.
```{python}
# Load the Stata dataset from GitHub
data_house = pd.read_stata(GITHUB_DATA_URL + 'AED_HOUSE.DTA')
print(f"✓ Data loaded successfully!")
print(f" Shape: {data_house.shape[0]} observations, {data_house.shape[1]} variables")
```
## 1.3 Preview the Data
Let's look at the first few rows to understand what variables we have available.
```{python}
# First 5 observations
data_house.head()
```
Each row is one house sale. Alongside our two key variables — `price` (sale price in dollars) and `size` (square feet) — the data include `bedrooms`, `bathrooms`, `lotsize` (lot size category), `age` (years), `monthsold` (month of sale), and the original listing price (`list`).
## 1.4 Explore the Data
Before running any regression, we need to understand our data through **descriptive statistics**. These reveal the scale, variability, and range of our variables—essential context for interpreting regression results later. Let's look at the key statistics for price and size.
```{python}
# Summary statistics for all variables
data_house.describe().round(2)
```
**Key observations:**
- **Mean house price**: Around \$253,910
- **Mean house size**: Around 1,883 square feet
- **Price range**: \$204,000 to \$375,000
- **Size range**: 1,400 to 3,300 square feet
Notice the variation in both variables - this variation is what allows us to estimate a relationship!
> **Key Concept 1.2: Observational Data in Economics**
>
> Economics primarily uses observational data where we observe behavior in uncontrolled settings. Unlike experimental data where conditions can be controlled, observational data requires careful methods to establish relationships and, when possible, causal effects.
*Now that we have explored the data numerically, let's visualize the relationship between house size and price.*
## 1.5 Visualizing the Relationship
**Before running any regression**, it's good practice to visualize the relationship between X and Y. A scatter plot helps us:
1. Check if there appears to be a linear relationship
2. Identify any outliers or unusual observations
3. Get an intuitive sense of the strength of the relationship
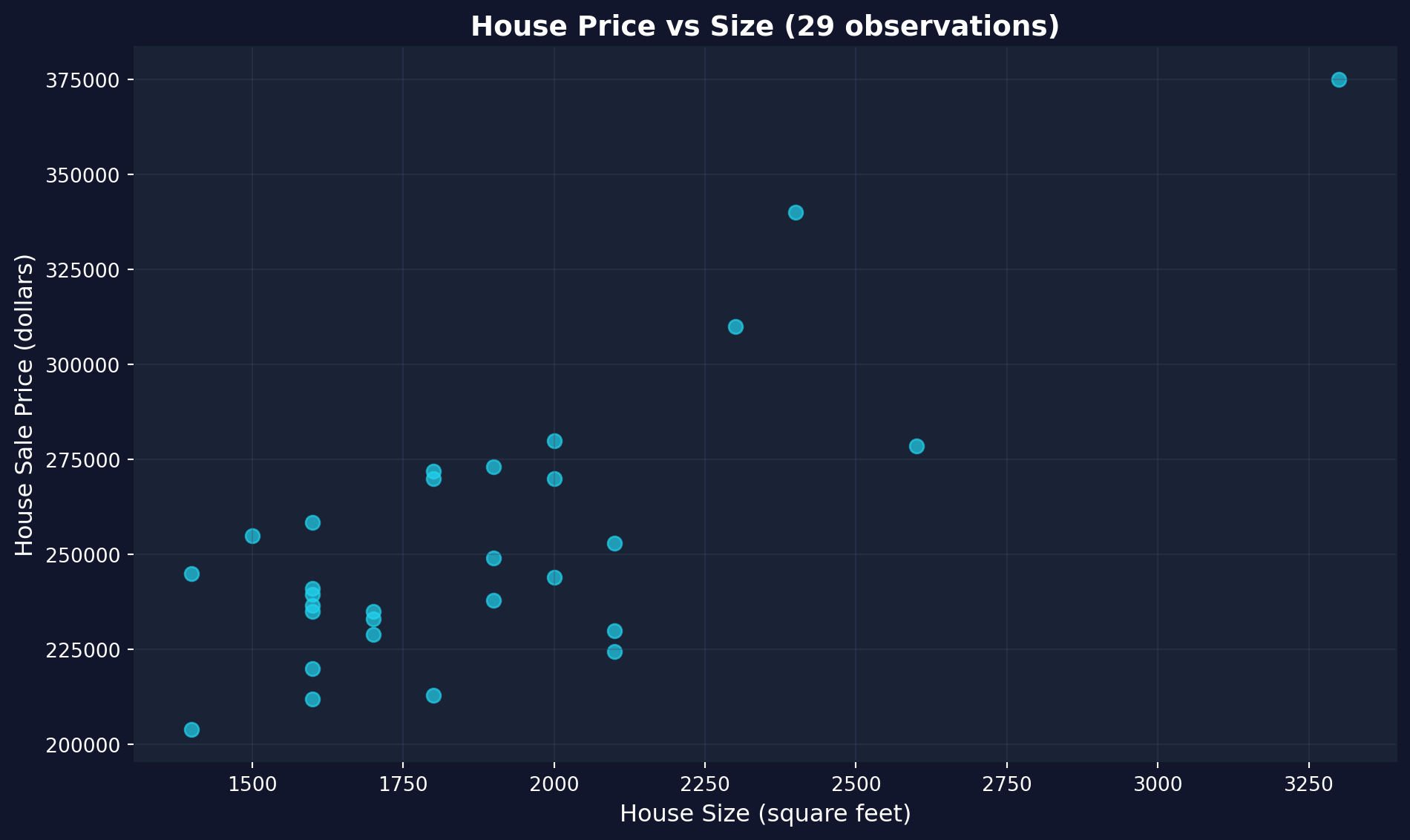
Let's create a scatter plot of house price vs. house size.
```{python}
# Create scatter plot
fig, ax = plt.subplots(figsize=(10, 6))
# Plot the data points
ax.scatter(data_house['size'], data_house['price'],
color='#22d3ee', s=50, alpha=0.7) # s = marker size, alpha = transparency
# Labels and formatting
ax.set_xlabel('House Size (square feet)', fontsize=12)
ax.set_ylabel('House Sale Price (dollars)', fontsize=12)
ax.set_title('House Price vs Size (29 observations)', fontsize=14, fontweight='bold')
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
**What to look for in this scatter plot:**
- **Direction**: Positive — larger houses tend to have higher prices
- **Form**: Roughly linear — the points follow an upward-sloping pattern
- **Scatter**: Not all points lie exactly on a line — this variation is the "error" that regression cannot explain
> **Key Concept 1.3: Visual Exploration Before Regression**
>
> Always plot your data before running a regression. Scatter plots reveal the direction, strength, and form of relationships between variables, and can expose outliers or nonlinearities that summary statistics alone would miss. Visual exploration is the essential first step in any empirical analysis.
## 1.6 Fitting a Regression Line
Now we'll fit an **Ordinary Least Squares (OLS)** regression line to these data. OLS chooses the intercept ($\beta_0$) and slope ($\beta_1$) that **minimize the sum of squared residuals**:
$$\min_{\beta_0, \beta_1} \sum_{i=1}^{n} (\text{price}_i - \beta_0 - \beta_1 \times \text{size}_i)^2$$
In other words, we're finding the line that makes our prediction errors as small as possible (in a squared sense).
We'll use Python's `pyfixest` package, which provides regression output similar to Stata and R.
> **Key Concept 1.4: Introduction to Regression Analysis**
>
> Regression analysis quantifies the relationship between variables. In a bivariate regression, the slope coefficient tells us how much the outcome variable ($y$) changes when the explanatory variable ($x$) increases by one unit.
Let's estimate the model and see what we get. The code below fits the regression and prints the key numbers first, then shows the full output table.
```{python}
# Fit OLS regression: price ~ size
# pf.feols() estimates OLS in one step — same formula syntax as R's fixest
fit = pf.feols('price ~ size', data=data_house)
# Extract key results
intercept = fit.coef()['Intercept']
slope = fit.coef()['size']
r_squared = fit._r2
n_obs = int(fit._N)
print(f"Estimated equation: price = {intercept:,.0f} + {slope:.2f} x size")
print(f"Slope: each additional sq ft is associated with ${slope:,.2f} higher price")
print(f"R-squared: {r_squared:.4f} ({r_squared*100:.1f}% of variation explained)")
print(f"Observations: {n_obs}")
# Full regression output
fit.summary()
```
## 1.7 Interpreting the Results
The regression output contains a lot of information! Let's break down the most important parts:
### Key Statistics to Focus On:
1. **Coefficients table** (middle section):
- **Intercept**: The predicted price when size = 0 (often not economically meaningful)
- **size**: The slope coefficient - our main interest!
- **Std. Error**: Standard error (measures precision of the estimate)
- **t value**: t-statistic (coefficient / standard error)
- **Pr(>|t|)**: p-value (tests if coefficient is significantly different from zero)
2. **R2** (bottom line, after the table):
- Proportion of variation in Y explained by X
- Ranges from 0 to 1 (higher = better fit)
3. **Header block** (top section):
- Reports the estimation method (OLS), the dependent variable, and the number of observations
- **Inference: iid** indicates classical (default) standard errors
4. **RMSE** (bottom line of the output):
- Root mean squared error — the typical size of a prediction error, in the units of Y (dollars here)
- Smaller RMSE means the fitted line predicts prices more accurately
We already extracted the key numbers above. Here's how to read them:
- **Intercept** ($\beta_0$ = \$115,017): The predicted price when size = 0. This is not economically meaningful (no house has zero square feet), but it anchors the regression line.
- **Slope** ($\beta_1$ = \$73.77 per sq ft): Our main result — each additional square foot is associated with a \$73.77 higher price.
- **Statistical significance** (t = 6.60, p < 0.001): The slope estimate is more than six standard errors away from zero — a pattern this strong would be very unlikely if size and price were truly unrelated in the population. Chapter 7 develops these inference tools for regression in detail, building on the inference foundations introduced in Chapters 3 and 4.
- **R-squared** (0.6175): House size explains about 62% of the variation in prices. The remaining 38% is due to other factors.
> **Key Concept 1.5: Reading Regression Output**
>
> The key elements of regression output are: the coefficient estimate (magnitude and direction of the relationship), the standard error (precision of the estimate), the t-statistic and p-value (statistical significance), and R-squared (proportion of variation explained). Together, these tell us whether the relationship is economically meaningful and statistically reliable.
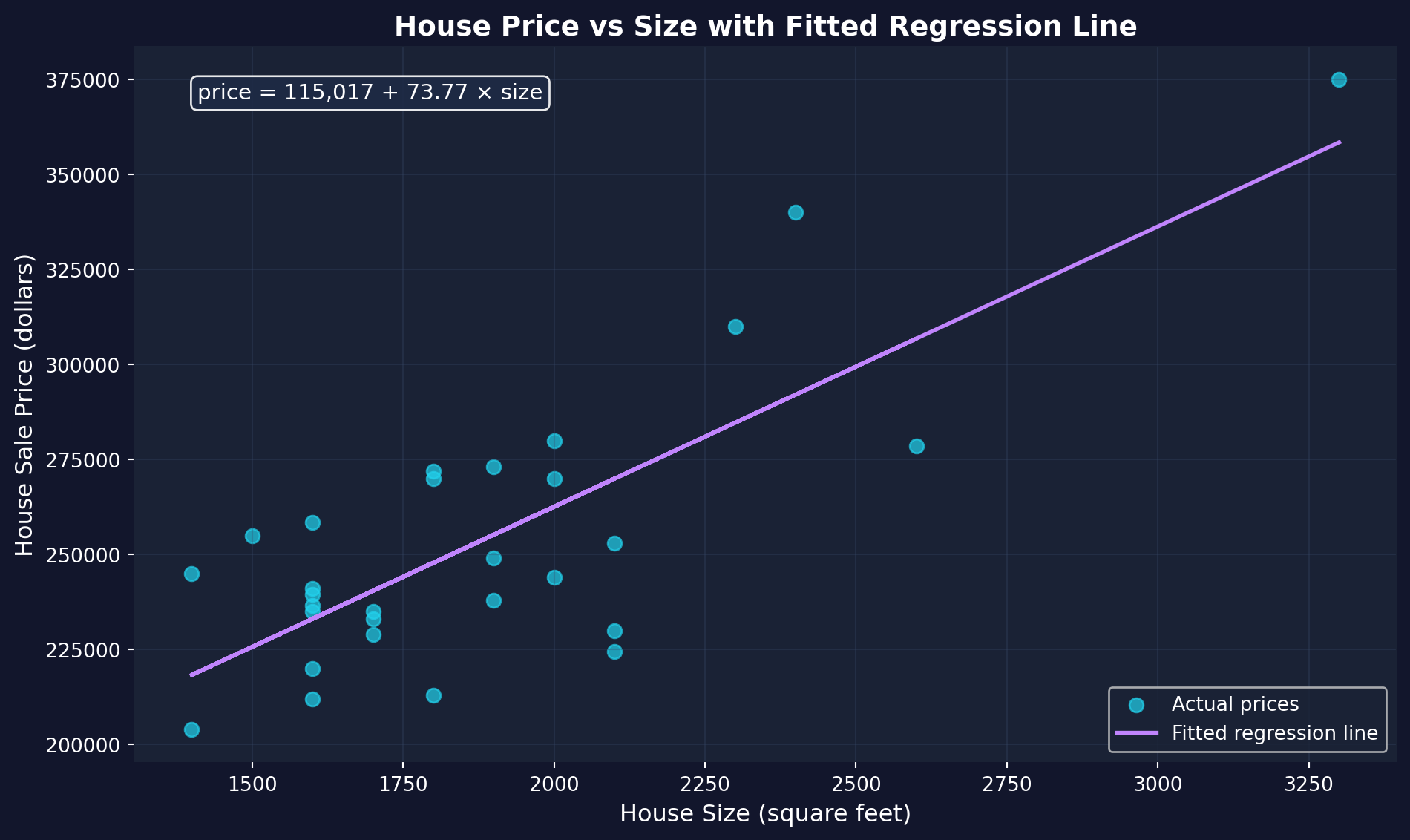
## 1.8 Visualizing the Fitted Line
The **fitted regression line** represents our model's predictions. For any given house size, the line shows the predicted price according to our equation:
$$\hat{\text{price}} = \beta_0 + \beta_1 \times \text{size}$$
Let's overlay this fitted line on our scatter plot to see how well it captures the relationship.
```{python}
# Create scatter plot with fitted regression line
fig, ax = plt.subplots(figsize=(10, 6))
# Plot actual data points
ax.scatter(data_house['size'], data_house['price'],
color='#22d3ee', s=50, label='Actual prices', alpha=0.7)
# Plot fitted regression line
ax.plot(data_house['size'], fit.predict(),
color='#c084fc', linewidth=2, label='Fitted regression line')
# Add equation to plot
equation_text = f'price = {intercept:,.0f} + {slope:.2f} × size'
ax.text(0.05, 0.95, equation_text,
transform=ax.transAxes, fontsize=11,
verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='#1e2a45', alpha=0.9))
# Labels and formatting
ax.set_xlabel('House Size (square feet)', fontsize=12)
ax.set_ylabel('House Sale Price (dollars)', fontsize=12)
ax.set_title('House Price vs Size with Fitted Regression Line',
fontsize=14, fontweight='bold')
ax.legend(loc='lower right', fontsize=10)
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
**What to look for:** The purple line captures the general upward trend. The vertical distance from each point to the line is that house's **residual** — the difference between its actual price and the price our model predicts. OLS chose this particular line because it makes those residuals as small as possible (in a squared sense).
## 1.9 Economic Interpretation and Examples
Statistical output is only meaningful when we translate it into economic insights. Let's think about what our regression results mean in practical terms.
### Practical Implications:
Our estimated slope of approximately **\$74 per square foot** means:
- A house that's 100 sq ft larger is predicted to sell for \$74 × 100 = \$7,400 more
- A house that's 500 sq ft larger is predicted to sell for \$74 × 500 = \$37,000 more
### Making Predictions:
We can use our regression equation to predict prices for houses of different sizes. For example, for a 2,000 sq ft house:
$$\hat{\text{price}} = 115,017 + 73.77 \times 2000 = \$262,557$$
### Important Caveats:
1. **This is association, not causation**: We can't conclude that adding square footage to a house will increase its value by \$74/sq ft. Other factors (like quality of construction) might be correlated with size.
2. **Omitted variables**: Many other factors affect house prices (location, age, condition, amenities). Our simple model ignores these - we'll learn how to include them in later chapters.
3. **Sample-specific**: These results are from 29 houses in Davis, CA in 1999. The relationship might differ in other locations or time periods.
4. **Don't extrapolate too far**: Our data ranges from 1,400 to 3,300 sq ft. Predictions far outside this range (e.g., for a 10,000 sq ft house) may not be reliable.
> **Key Concept 1.6: Interpreting Regression Results**
>
> Regression results must be interpreted with caution. Association does not imply causation, omitted variables can bias estimates, and predictions should not extrapolate beyond the range of the data.
## Key Takeaways
**Statistical Methods and Data Types:**
- Econometrics uses two main approaches: descriptive analysis (summarizing data) and statistical inference (drawing population conclusions from samples)
- Economic data are primarily continuous and numerical, though categorical and discrete data are also important
- Economics relies mainly on observational data, making causal inference more challenging than with experimental data
- The three data collection methods are cross-section (individuals at one time), time series (one individual over time), and panel data (individuals over time)
- Each data type requires different considerations for statistical inference, particularly when computing standard errors
- This textbook focuses on continuous numerical data and cross-section analysis as the foundation for more advanced methods
**Regression Analysis and Interpretation:**
- Regression analysis is the primary tool in econometrics, quantifying how outcome variables (y) vary with explanatory variables (x)
- The simple linear regression model has the form: $y = \beta_0 + \beta_1 x + \varepsilon$, where $\beta_0$ is the intercept and $\beta_1$ is the slope
- The slope coefficient measures association: how much y changes when x increases by one unit
- OLS (Ordinary Least Squares) finds the best-fitting line by minimizing the sum of squared prediction errors
- R-squared measures the proportion of variation in y explained by x, ranging from 0 to 1 (higher = better fit)
- Economic interpretation focuses on magnitude (size of effect), statistical significance, and practical importance
**Practical Application:**
- Our house price example: Each additional square foot is associated with a \$73.77 increase in price (R² = 61.75%)
- Visualization is essential: scatter plots reveal the nature of relationships before fitting regression models
- Regression shows association, not causation—omitted variables and confounding factors require careful consideration
- Predictions should not extrapolate beyond the range of observed data
- Sample-specific results may not generalize to other locations, time periods, or populations
**Python Tools and Workflow:**
- `pandas` handles data loading, manipulation, and descriptive statistics
- `pyfixest.feols()` estimates OLS regression models with R-style formula syntax (Python port of R's fixest)
- `matplotlib` creates publication-quality scatter plots and visualizations
- Standard workflow: load data → explore descriptively → visualize → model → interpret → validate
- Random seeds ensure reproducibility of results across different runs
**Prerequisites and Mathematical Background:**
- Summation notation (Σ) expresses formulas concisely and appears throughout econometrics
- Calculus concepts (derivatives, rates of change) help understand marginal effects but are not essential
- Expected values (E[X]) define population parameters like means and variances
- "Learning-by-doing" is the most effective approach: practice with real data and software is essential for mastery
**Python Libraries and Code:**
This single code block reproduces the core workflow of Chapter 1. It is self-contained — copy it into an empty notebook and run it to review the complete pipeline from data loading to regression interpretation.
```python
# =============================================================================
# CHAPTER 1 CHEAT SHEET: Analysis of Economics Data
# =============================================================================
# --- Libraries ---
# !pip install pyfixest # uncomment if running in Google Colab
import pandas as pd # data loading and manipulation
import matplotlib.pyplot as plt # creating plots and visualizations
import pyfixest as pf # OLS regression (Python port of R's fixest)
# =============================================================================
# STEP 1: Load data directly from a URL
# =============================================================================
# pd.read_stata() reads Stata .dta files (pandas also supports CSV, Excel, etc.)
url = "https://raw.githubusercontent.com/quarcs-lab/data-open/master/AED/AED_HOUSE.DTA"
data_house = pd.read_stata(url)
print(f"Dataset: {data_house.shape[0]} observations, {data_house.shape[1]} variables")
# =============================================================================
# STEP 2: Descriptive statistics — summarize before modeling
# =============================================================================
# .head() shows the first rows; .describe() gives mean, std, min, quartiles, max
print(data_house[['price', 'size']].describe().round(2))
# =============================================================================
# STEP 3: Scatter plot — always visualize before fitting a regression
# =============================================================================
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(data_house['size'], data_house['price'], s=50, alpha=0.7)
ax.set_xlabel('House Size (square feet)')
ax.set_ylabel('House Sale Price (dollars)')
ax.set_title('House Price vs Size')
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# =============================================================================
# STEP 4: OLS regression — fit the model
# =============================================================================
# pf.feols() estimates OLS in one step — same formula syntax as R's fixest
# Formula: 'y ~ x' regresses y on x (intercept included automatically)
fit = pf.feols('price ~ size', data=data_house)
# Extract key results
slope = fit.coef()['size'] # marginal effect: $/sq ft
intercept = fit.coef()['Intercept'] # predicted price when size = 0
r_squared = fit._r2 # proportion of variation explained
print(f"Estimated equation: price = {intercept:,.0f} + {slope:.2f} × size")
print(f"Interpretation: each additional sq ft is associated with ${slope:,.2f} higher price")
print(f"R-squared: {r_squared:.4f} ({r_squared*100:.1f}% of variation explained)")
# Full regression table (coefficients, std errors, t-stats, p-values, R²)
fit.summary()
# =============================================================================
# STEP 5: Scatter plot with fitted regression line and R²
# =============================================================================
# fit.predict() returns the predicted y-values from the estimated equation
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(data_house['size'], data_house['price'], s=50, alpha=0.7, label='Actual prices')
ax.plot(data_house['size'], fit.predict(), color='red', linewidth=2, label='Fitted line')
ax.set_xlabel('House Size (square feet)')
ax.set_ylabel('House Sale Price (dollars)')
ax.set_title(f'OLS Regression: price = {intercept:,.0f} + {slope:.2f} × size (R² = {r_squared:.2%})')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# =============================================================================
# STEP 6: Compare predictors — association is NOT causation
# =============================================================================
# Running separate regressions with different x-variables shows that each tells
# a different story. High R² does not prove causation — omitted variables
# (location, condition, school district) can bias any single-variable slope.
predictors = {
'size': 'Size (sq ft)',
'bedrooms': 'Bedrooms',
'bathrooms': 'Bathrooms',
'lotsize': 'Lot size',
'age': 'Age (years)',
}
print(f"{'Predictor':<18} {'Slope':>10} {'R²':>8}")
print("-" * 38)
for var, label in predictors.items():
m = pf.feols(f'price ~ {var}', data=data_house)
print(f"{label:<18} {m.coef()[var]:>10.2f} {m._r2:>8.4f}")
```
**Try it yourself!** Copy this code into an empty Google Colab notebook and run it: [Open Colab](https://colab.research.google.com/notebooks/empty.ipynb)
---
**Next Steps:**
- **Chapter 2**: Univariate data summary (describing single variables)
- **Chapter 3**: The sample mean and sampling distributions
- **Chapter 4**: Statistical inference for the mean (confidence intervals, hypothesis tests)
- **Chapters 5-7**: Deep dive into bivariate regression (extending what we learned here)
**You have now mastered:**
- Loading and exploring economic data in Python
- Creating scatter plots to visualize relationships
- Estimating simple linear regression models with OLS
- Interpreting regression coefficients economically
- Understanding the limitations of regression analysis
These foundational concepts are the building blocks for all of econometrics. Everything that follows builds on this introduction!
> **Common Mistakes to Avoid**
>
> - **Missing `pf.feols()`**: Use `pf.feols('y ~ x', data=df)` to estimate the model in one step
> - **Confusing correlation with causation**: Regression shows association, not cause-and-effect
> - **Extrapolating beyond the data range**: Predictions outside observed values are unreliable
## Practice Exercises
Test your understanding of regression analysis with these exercises:
**Exercise 1:** Conceptual understanding
- (a) What is the difference between descriptive analysis and statistical inference?
- (b) Why do economists primarily use observational data rather than experimental data?
- (c) Name the three main types of data collection methods and give an example of each.
**Exercise 2:** Data types
- Classify each of the following as continuous numerical, discrete numerical, or categorical:
- (a) Annual household income
- (b) Number of children in a family
- (c) Employment status (employed, unemployed, not in labor force)
- (d) Temperature in degrees Celsius
**Exercise 3:** Regression interpretation
- Suppose you estimate: earnings = 20,000 + 5,000 × education
- (a) Interpret the intercept coefficient
- (b) Interpret the slope coefficient
- (c) Predict earnings for someone with 16 years of education
- (d) What is the predicted difference in earnings between someone with 12 vs. 16 years of education?
**Exercise 4:** Using our house price model
- Using the regression equation: price = 115,017 + 73.77 × size
- (a) Predict the price for a 1,800 sq ft house
- (b) Predict the price for a 2,500 sq ft house
- (c) What is the predicted price difference between these two houses?
- (d) Is the intercept economically meaningful in this context? Why or why not?
**Exercise 5:** Critical thinking about causation
- Our regression shows larger houses have higher prices. Does this mean:
- (a) Adding square footage to a house will increase its value by $73.77 per sq ft?
- (b) What other factors might be correlated with both house size and price?
- (c) How would you design a study to establish a causal relationship?
**Exercise 6:** R-squared interpretation
- Our model has R² = 0.6175 (61.75%)
- (a) What does this number tell us about our model?
- (b) What factors might explain the remaining 38.25% of variation in prices?
- (c) Would R² = 1.0 be realistic for real-world economic data? Why or why not?
**Exercise 7:** Summation notation
- Calculate: $\sum_{i=1}^{4} (3 + 2i)$
- Show all steps in your calculation
**Exercise 8:** Python practice
- Load the house dataset and:
- (a) Calculate the correlation between price and bedrooms
- (b) Create a scatter plot of price vs. bedrooms
- (c) Estimate the regression: price ~ bedrooms
- (d) Compare the R² to our size regression. Which predictor is better?
---
## Case Studies
Now let's apply what you've learned to real economic research! In this section, you'll explore data from actual published studies, using the same tools and techniques from this chapter.
**Why case studies matter:**
- See how regression analysis is used in real research
- Practice applying Chapter 1 tools to authentic data
- Develop intuition for economic relationships
- Bridge the gap between textbook examples and research practice
### Case Study 1: Economic Convergence Clubs
**Research Question**: Do countries converge toward similar levels of economic development, or do they form distinct "convergence clubs" with different trajectories?
**Background**: Traditional economic theory suggests that poor countries should grow faster than rich countries, eventually "catching up" in terms of income and productivity. This is called the convergence hypothesis. However, empirical evidence shows a more complex picture: countries may form distinct groups (clubs) that converge toward different long-run equilibrium levels rather than a single global level.
**This Research** ([Mendez, 2020](https://github.com/quarcs-lab/mendez2020-convergence-clubs-code-data)): Uses modern econometric methods to identify convergence clubs in labor productivity across countries. The analysis examines whether countries follow one common development path or multiple distinct paths, and what factors (capital accumulation, technology, institutions) drive these patterns.
**The Data**: Panel dataset tracking multiple countries over several years, with 27 variables including:
- **Output measures**: GDP, GDP per capita
- **Productivity**: Labor productivity, total factor productivity (TFP)
- **Capital**: Physical capital stock, capital per worker
- **Human capital**: Years of schooling, human capital index
- **Classifications**: Country codes, regions, income groups
**Your Task**: Use the descriptive analysis and regression tools from Chapter 1 to explore patterns in the convergence clubs data. You'll investigate productivity gaps, visualize relationships, and begin to understand why some countries develop differently than others.
> **Key Concept 1.7: Economic Convergence and Productivity Drivers**
>
> **Beta convergence** refers to the hypothesis that poor countries will grow faster than rich countries, eventually "catching up" in terms of income and productivity. However, evidence suggests countries may form distinct **convergence clubs**—groups that converge toward different long-run equilibrium levels rather than a single global level.
>
> Labor productivity (output per worker) depends on **capital accumulation** (capital per worker) and **aggregate efficiency** (total factor productivity or TFP). The regression of productivity on capital captures this association, allowing us to quantify how much of cross-country productivity differences are explained by capital versus efficiency factors.
#### Load the Convergence Clubs Data
Let's load two datasets:
1. **Main dataset** (`dat.csv`): Country-year panel data with economic variables
2. **Data dictionary** (`dat-definitions.csv`): Explains what each variable means
The data uses a **multi-index** structure with (country, year) pairs, allowing us to track each country over time.
```{python}
# Import data with sorted multi-index
df1 = pd.read_csv(
"https://raw.githubusercontent.com/quarcs-lab/mendez2020-convergence-clubs-code-data/master/assets/dat.csv",
index_col=["country", "year"]
).sort_index()
# Import data dictionary
df2 = pd.read_csv(
"https://raw.githubusercontent.com/quarcs-lab/mendez2020-convergence-clubs-code-data/master/assets/dat-definitions.csv"
)
# Convergence clubs dataset
print(f"Dataset shape: {df1.shape[0]} observations (country-year pairs), {df1.shape[1]} variables")
print(f"Countries: {len(df1.index.get_level_values('country').unique())} unique countries")
print(f"Years: {df1.index.get_level_values('year').min()} to {df1.index.get_level_values('year').max()}")
# First 5 observations
df1.head(5)
```
The second dataset is the data dictionary. The cell below displays it in full — use it to find the exact variable names you will need in the tasks that follow.
```{python}
# Variable definitions
df2
```
#### Task 1: Data Exploration (Guided)
**Objective**: Understand the dataset structure and available variables.
**Instructions**:
1. Examine the output above to understand the multi-index (country, year) structure
2. Review the data dictionary to identify key productivity variables
3. Check for missing values in key variables
4. Identify the variable names you'll use for subsequent analyses
**Key variables to focus on** (check exact names in the data dictionary):
- Labor productivity variables
- Capital per worker variables
- GDP per capita measures
- Country classification variables (region, income group)
Run the code above and study the output. What patterns do you notice? How many time periods does each country have?
```{python}
# Your code here: Explore the dataset structure
#
# Suggested explorations:
# 1. Check column names: df1.columns.tolist()
# 2. Check for missing values: df1.isnull().sum()
# 3. Examine a specific country's data
# 4. Count observations per country
# Example: Examine the United States' data (the index uses full country names)
# df1.loc['United States']
```
#### Task 2: Descriptive Statistics (Semi-guided)
**Objective**: Generate summary statistics for key productivity variables.
**Instructions**:
1. Select 3-4 key variables related to productivity and capital
2. Generate descriptive statistics (mean, median, std, min, max)
3. Identify countries with highest and lowest productivity levels
4. Calculate the productivity gap between top and bottom performers
**Apply what you learned in sections 1.4**: Use `.describe()` method like we did with the house price data.
**Hint**: You'll need to identify the exact variable names from the data dictionary. Look for variables measuring labor productivity, GDP per capita, or capital per worker.
```{python}
# Your code here: Generate descriptive statistics
#
# Steps:
# 1. Identify variable names from data dictionary (check df2)
# 2. Select key variables from df1
# 3. Generate summary statistics using .describe()
# 4. Find countries with max/min values using .idxmax() and .idxmin()
# 5. Calculate gaps between high and low performers
# Example structure:
# key_vars = ['variable1', 'variable2', 'variable3'] # Replace with actual names
# df1[key_vars].describe()
```
> **Key Concept 1.8: Panel Data Structure**
>
> Panel data combines cross-section and time series dimensions, tracking multiple entities (countries) over multiple time periods (years). This structure allows us to study both differences between countries (cross-sectional variation) and changes within countries over time (time series variation). The data is indexed by (country, year) pairs.
#### Task 3: Visualizing Productivity Patterns (Semi-guided)
**Objective**: Create scatter plots to visualize productivity relationships.
**Instructions**:
1. Create a scatter plot comparing two productivity-related variables
2. Add appropriate axis labels and a descriptive title
3. Optionally: Color-code points by region or income group
4. Interpret the pattern you observe
**Apply what you learned in section 1.5**: Use matplotlib to create scatter plots like the house price visualization.
**Suggested relationships to explore**:
- GDP per capita vs. labor productivity
- Capital per worker vs. labor productivity
- Human capital vs. GDP per capita
```{python}
# Your code here: Create scatter plot
#
# Steps:
# 1. Prepare data (select variables, remove missing values)
# 2. Create figure and axis: fig, ax = plt.subplots(figsize=(10, 6))
# 3. Create scatter plot: ax.scatter(x, y, ...)
# 4. Add labels, title, and formatting
# 5. Display and interpret
# Example structure:
# plot_data = df1[['var_x', 'var_y']].dropna()
# fig, ax = plt.subplots(figsize=(10, 6))
# ax.scatter(plot_data['var_x'], plot_data['var_y'], alpha=0.6)
# ax.set_xlabel('Variable X')
# ax.set_ylabel('Variable Y')
# plt.show()
# What pattern do you observe? Positive or negative relationship?
```
#### Task 4: Time Series Exploration (More Independent)
**Objective**: Examine productivity trends over time for specific countries.
**Instructions**:
1. Select 2-3 countries of interest (e.g., USA, China, India, Japan, or countries from your region)
2. Plot labor productivity over time for each country
3. Compare their trajectories: Which countries are growing faster?
4. Calculate the average annual growth rate (optional: percentage change per year)
**Hint**: Remember that panel data is indexed by (country, year). Use `.loc[country]` to filter data for a specific country.
**Questions to answer**:
- Are productivity levels converging (getting closer) or diverging (spreading apart)?
- Which country experienced the fastest productivity growth?
- Do you see evidence of convergence clubs (groups following similar paths)?
```{python}
# Your code here: Time series plots
#
# Steps:
# 1. Select countries (e.g., countries = ['United States', 'China', 'Japan'])
# 2. For each country, extract time series data
# 3. Create line plot over time
# 4. Compare trajectories
# Example structure:
# countries = ['United States', 'China', 'India'] # index uses full country names, not ISO codes
# fig, ax = plt.subplots(figsize=(10, 6))
#
# for country in countries:
# country_data = df1.loc[country]
# ax.plot(country_data.index, country_data['productivity_var'], label=country)
#
# ax.set_xlabel('Year')
# ax.set_ylabel('Labor Productivity')
# ax.legend()
# plt.show()
```
#### Task 5: Simple Regression Analysis (Independent)
**Objective**: Estimate the relationship between capital and productivity.
**Research Question**: Does higher capital per worker lead to higher labor productivity?
**Instructions**:
1. Prepare regression data (select variables, remove missing values)
2. Estimate OLS regression: `labor_productivity ~ capital_per_worker`
3. Display the regression summary
4. Interpret the slope coefficient economically
5. Report the R-squared value
6. **Critical thinking**: Discuss whether this is association or causation
**Apply what you learned in sections 1.6-1.7**: Use `pf.feols()` from pyfixest and interpret coefficients.
**Important questions**:
- What does the slope coefficient tell us?
- Could there be omitted variables affecting both capital and productivity?
- Could reverse causality be a concern (does higher productivity lead to more capital accumulation)?
```{python}
# Your code here: Regression analysis
#
# Steps:
# 1. Prepare data: reg_data = df1[['productivity_var', 'capital_var']].dropna()
# 2. Reset index if needed: reg_data = reg_data.reset_index()
# 3. Estimate regression: fit = pf.feols('productivity_var ~ capital_var', data=reg_data)
# 4. Display summary: fit.summary()
# 5. Extract and interpret coefficients
# Example structure:
# reg_data = df1[['var_y', 'var_x']].dropna().reset_index()
# fit = pf.feols('var_y ~ var_x', data=reg_data)
# fit.summary()
#
# Interpretation:
# Slope = ___: For every unit increase in capital per worker,
# labor productivity is ___ units higher (association, not causation)
# R² = ___: Capital explains ___% of variation in productivity
```
#### Task 6: Comparative Analysis (Independent)
**Objective**: Compare productivity patterns between country groups.
**Research Question**: Does the capital-productivity relationship differ between high-income and developing countries?
**Instructions**:
1. If the data has an income group variable, group countries by income level
2. Calculate average productivity and capital for each group
3. Create comparative scatter plots (one color per group)
4. (Advanced) Run separate regressions for each group
5. Compare the slope coefficients: Is the relationship stronger in one group?
**This extends Chapter 1 concepts**: You're using grouping and comparative analysis to see if relationships vary across subsamples.
**Questions to explore**:
- Do high-income countries have uniformly higher productivity?
- Is the capital-productivity relationship steeper in developing countries?
- What might explain differences between groups?
```{python}
# Your code here: Comparative analysis
#
# Steps:
# 1. Identify grouping variable (income level, region, etc.)
# 2. Group data: df1.groupby('group_var').mean()
# 3. Create comparative visualizations
# 4. Run regressions by group (optional)
# Example structure for comparative scatter plot:
# fig, ax = plt.subplots(figsize=(10, 6))
#
# for group in df1['group_var'].unique():
# group_data = df1[df1['group_var'] == group]
# ax.scatter(group_data['var_x'], group_data['var_y'], label=group, alpha=0.6)
#
# ax.set_xlabel('Capital per Worker')
# ax.set_ylabel('Labor Productivity')
# ax.legend()
# plt.show()
# Advanced: Separate regressions
# for group in groups:
# group_data = df1[df1['group_var'] == group].dropna()
# fit_g = pf.feols('var_y ~ var_x', data=group_data)
# print(f"\n{group}: Slope = {fit_g.coef()['var_x']:.4f}, R² = {fit_g._r2:.4f}")
```
#### What You've Learned from This Case Study
Through this hands-on exploration of economic convergence data, you've applied all the core Chapter 1 tools:
- **Data loading and exploration**: Worked with real panel data from research
- **Descriptive statistics**: Summarized productivity patterns across countries
- **Visualization**: Created scatter plots and time series to reveal relationships
- **Regression analysis**: Quantified the capital-productivity relationship
- **Critical thinking**: Distinguished association from causation
- **Comparative analysis**: Explored differences between country groups
**Connection to the research**: The patterns you've discovered—productivity gaps, the role of capital, differences between country groups—are the empirical motivation for the convergence clubs analysis in Mendez (2020). The full research uses advanced methods (covered in later chapters) to formally identify clubs and test convergence hypotheses.
**Looking ahead**:
- **Chapter 2** will teach you more sophisticated descriptive analysis for univariate data
- **Chapter 3-4** cover statistical inference, allowing you to test hypotheses formally
- **Chapter 5-9** extend regression analysis to multiple predictors and transformations
- **Chapter 10-17** introduce advanced methods like panel data regression—perfect for convergence clubs!
---
**Great work!** You've completed Chapter 1 and applied your new skills to real economic research. Continue to Chapter 2 to learn more about data summary and distributions.
### Case Study 2: Can Satellites See Poverty? Predicting Local Development in Bolivia
**Research Question**: Can satellite data—nighttime lights and satellite image embeddings—predict local economic development across Bolivia's municipalities?
**Background**: Monitoring progress toward the United Nations Sustainable Development Goals (SDGs) requires timely, granular data on economic conditions. However, many developing countries lack comprehensive municipality-level statistics. Recent advances in remote sensing and machine learning offer a promising alternative: using satellite data to *predict* local development outcomes.
Two types of satellite data have proven particularly useful:
1. **Nighttime lights (NTL)**: Satellite images of Earth at night reveal the intensity of artificial lighting. Brighter areas typically correspond to greater economic activity, electrification, and urbanization. NTL data is available globally and annually, making it a powerful proxy for economic development in data-scarce regions ([Henderson et al., 2012](https://doi.org/10.1257/aer.102.2.994)).
2. **Satellite image embeddings**: Deep learning models trained on daytime satellite imagery (Sentinel-2, Landsat) can extract 64-dimensional feature vectors that capture visual patterns—road networks, building density, vegetation cover, agricultural activity—without requiring manual labeling. These abstract features often correlate strongly with socioeconomic outcomes ([Jean et al., 2016](https://doi.org/10.1126/science.aaf7894)).
**This Research** ([DS4Bolivia Project](https://github.com/quarcs-lab/ds4bolivia)): A comprehensive data science initiative that integrates satellite data with Bolivia's Municipal SDG Atlas ([Andersen et al., 2020](https://atlas.sdsnbolivia.org)) to study geospatial development patterns across all **339 municipalities**. The project demonstrates how machine learning models can predict SDG indicators from satellite features, achieving meaningful predictive accuracy for poverty and energy access indicators.
**The Data**: Cross-sectional dataset covering 339 Bolivian municipalities with over 350 variables, including:
- **Development outcomes**: Municipal Sustainable Development Index (IMDS, 0-100 composite), individual SDG indices (SDG 1-17)
- **Satellite data**: Log nighttime lights per capita (2012-2020), 64 satellite embedding dimensions (2017)
- **Demographics**: Population (2001-2020), municipality and department names
- **Socioeconomic indicators**: Unsatisfied basic needs, literacy rates, electricity coverage, health outcomes
**Your Task**: Use the descriptive analysis and regression tools from Chapter 1 to explore the DS4Bolivia dataset. You'll investigate whether nighttime lights predict municipal development, visualize satellite-development relationships, and begin to assess how useful remote sensing data is for SDG monitoring. This case study introduces a dataset that we will revisit throughout the textbook, applying increasingly sophisticated econometric methods in each chapter.
> **Key Concept 1.9: Satellite Data as Economic Proxy**
>
> **Nighttime lights (NTL)** captured by satellites measure the intensity of artificial illumination on Earth's surface. Because lighting requires electricity and economic activity, NTL intensity strongly correlates with GDP, income levels, and urbanization. The log of NTL per capita transforms the highly skewed raw luminosity into a more symmetric variable suitable for regression analysis.
>
> **Satellite embeddings** are 64-dimensional feature vectors extracted by deep learning models from daytime satellite imagery. Each dimension captures abstract visual patterns (building density, road networks, vegetation) that correlate with socioeconomic conditions. Together, NTL and embeddings provide complementary information: NTL captures *nighttime economic activity* while embeddings capture *daytime physical infrastructure*.
#### Load the DS4Bolivia Data
Let's load the comprehensive DS4Bolivia dataset directly from GitHub. This dataset integrates satellite data, SDG indicators, and demographic information for all 339 Bolivian municipalities.
```{python}
# Load the DS4Bolivia dataset
url_bol = "https://raw.githubusercontent.com/quarcs-lab/ds4bolivia/master/ds4bolivia_v20250523.csv"
bol = pd.read_csv(url_bol)
# DS4Bolivia dataset
print(f"Dataset shape: {bol.shape[0]} municipalities, {bol.shape[1]} variables")
print(f"Departments: {bol['dep'].nunique()} unique departments")
# Select key variables for this case study
key_vars = ['mun', 'dep', 'imds', 'ln_NTLpc2017', 'pop2017',
'index_sdg1', 'index_sdg4', 'index_sdg8', 'sdg1_1_ubn']
bol_key = bol[key_vars].copy()
# First 10 municipalities
bol_key.head(10)
```
Before starting the tasks, run the cell below to print a one-line description of each selected variable. Refer back to this list whenever a variable name is unclear.
```{python}
# Key variable descriptions
descriptions = {
'mun': 'Municipality name',
'dep': 'Department (administrative region, 9 total)',
'imds': 'Municipal Sustainable Development Index (0-100, composite of all SDGs)',
'ln_NTLpc2017': 'Log of nighttime lights per capita (2017, satellite-based)',
'pop2017': 'Population in 2017',
'index_sdg1': 'SDG 1 Index: No Poverty (0-100)',
'index_sdg4': 'SDG 4 Index: Quality Education (0-100)',
'index_sdg8': 'SDG 8 Index: Decent Work and Economic Growth (0-100)',
'sdg1_1_ubn': 'Unsatisfied Basic Needs (% of population, 2012)',
}
for var, desc in descriptions.items():
print(f" {var:20s} — {desc}")
```
#### Task 1: Data Exploration (Guided)
**Objective**: Understand the DS4Bolivia dataset structure and key variables.
**Instructions**:
1. Examine the output above: How many municipalities? How many departments?
2. Check for missing values in the key variables
3. Identify the range of the IMDS index (development measure)
4. Explore the distribution of departments (how many municipalities per department?)
**Key variables to focus on**:
- `imds`: Overall development index (our main dependent variable)
- `ln_NTLpc2017`: Log nighttime lights per capita (our main predictor)
- `dep`: Department (for regional comparisons)
- `pop2017`: Population (for context)
Run the code below to explore the data structure.
```{python}
# Your code here: Explore the DS4Bolivia dataset
#
# Suggested explorations:
# 1. Check for missing values: bol_key.isnull().sum()
# 2. Municipalities per department: bol_key['dep'].value_counts()
# 3. Range of IMDS: bol_key['imds'].describe()
# 4. Largest/smallest municipalities: bol_key.nlargest(5, 'pop2017')
# Check missing values
print(f"Total municipalities: {len(bol_key)}")
print(f"Complete cases (no missing): {bol_key.dropna().shape[0]}")
bol_key.isnull().sum()
```
#### Task 2: Descriptive Statistics (Guided)
**Objective**: Generate summary statistics for key development and satellite variables.
**Instructions**:
1. Calculate descriptive statistics for `imds`, `ln_NTLpc2017`, and `pop2017`
2. Identify the municipality with the highest and lowest IMDS
3. Compare average IMDS across departments
4. Discuss what the summary statistics reveal about inequality across municipalities
**Apply what you learned in section 1.4**: Use `.describe()` and `.groupby()` methods like we did with the house price data.
```{python}
# Your code here: Descriptive statistics for DS4Bolivia
#
# Steps:
# 1. Summary statistics for key variables
# 2. Identify top/bottom municipalities
# 3. Compare departments
# Descriptive statistics for key variables
bol_key[['imds', 'ln_NTLpc2017', 'pop2017', 'sdg1_1_ubn']].describe().round(2)
```
> **Key Concept 1.10: Subnational Development Analysis**
>
> National-level statistics can mask enormous variation in development outcomes within a country. Bolivia's 339 municipalities span a wide range of development levels—from highly urbanized departmental capitals with strong infrastructure to remote rural communities with limited services. Municipality-level analysis reveals this **within-country inequality** and helps identify specific areas where SDG progress lags behind. Satellite data is particularly valuable for subnational analysis because it provides spatially granular measurements even where traditional surveys are scarce or infrequent.
#### Task 3: Visualize the NTL-Development Relationship (Semi-guided)
**Objective**: Create scatter plots to visualize the relationship between nighttime lights and development.
**Instructions**:
1. Create a scatter plot of `ln_NTLpc2017` (x-axis) vs `imds` (y-axis)
2. Add appropriate axis labels and title
3. Optionally: Color-code points by department
4. Interpret the pattern: Is there a positive relationship? How strong does it look?
**Apply what you learned in section 1.5**: Use matplotlib to create scatter plots like the house price visualization.
**Hint**: Drop missing values before plotting with `.dropna()`
```{python}
# Your code here: Scatter plot of NTL vs Development
#
# Steps:
# 1. Prepare data (drop missing values)
# 2. Create scatter plot
# 3. Add labels and formatting
# 4. Interpret the pattern
# Example structure:
# plot_data = bol_key[['ln_NTLpc2017', 'imds']].dropna()
# fig, ax = plt.subplots(figsize=(10, 6))
# ax.scatter(plot_data['ln_NTLpc2017'], plot_data['imds'], alpha=0.5, color='navy')
# ax.set_xlabel('Log Nighttime Lights per Capita (2017)')
# ax.set_ylabel('Municipal Development Index (IMDS)')
# ax.set_title('Can Satellites See Development? NTL vs IMDS in Bolivia')
# plt.show()
```
#### Task 4: Simple Regression Analysis (Semi-guided)
**Objective**: Estimate the relationship between nighttime lights and development using OLS.
**Research Question**: How much does nighttime light intensity predict municipal development levels?
**Instructions**:
1. Prepare regression data (drop missing values in key variables)
2. Estimate OLS regression: `imds ~ ln_NTLpc2017`
3. Display the regression summary
4. Interpret the slope coefficient: What does a 1-unit increase in log NTL mean for IMDS?
5. Report and interpret R-squared: How much variation in development does NTL explain?
**Apply what you learned in sections 1.6-1.7**: Use `pf.feols()` from pyfixest.
```{python}
# Your code here: OLS regression of IMDS on NTL
#
# Steps:
# 1. Prepare data
# 2. Estimate regression
# 3. Display and interpret results
# Example structure:
# reg_data = bol_key[['imds', 'ln_NTLpc2017']].dropna()
# fit_bol = pf.feols('imds ~ ln_NTLpc2017', data=reg_data)
# fit_bol.summary()
#
# # Extract key statistics
# print(f"\nSlope: {fit_bol.coef()['ln_NTLpc2017']:.4f}")
# print(f"R-squared: {fit_bol._r2:.4f}")
# print(f"\nInterpretation: A 1-unit increase in log NTL per capita")
# print(f"is associated with a {fit_bol.coef()['ln_NTLpc2017']:.2f}-point increase in IMDS")
```
#### Task 5: Regional Comparison (Independent)
**Objective**: Compare development and NTL patterns across Bolivia's nine departments.
**Research Question**: Do satellite-development patterns vary across Bolivia's regions?
**Instructions**:
1. Calculate mean IMDS and mean NTL by department
2. Create a bar chart or dot plot comparing department averages
3. Identify which departments are the most and least developed
4. Create scatter plots colored by department to see if the NTL-IMDS relationship differs by region
5. Discuss what might explain regional differences (geography, urbanization, economic structure)
**This extends Chapter 1 concepts**: You're using grouping and comparative analysis to explore heterogeneity.
```{python}
# Your code here: Regional comparison
#
# Steps:
# 1. Group by department: bol_key.groupby('dep')[['imds', 'ln_NTLpc2017']].mean()
# 2. Create comparative bar chart
# 3. Create scatter plot colored by department
# 4. Identify top/bottom departments
# Example structure:
# dept_means = bol_key.groupby('dep')[['imds', 'ln_NTLpc2017']].mean().sort_values('imds')
# print(dept_means.round(2))
#
# fig, ax = plt.subplots(figsize=(10, 6))
# dept_means['imds'].plot(kind='barh', ax=ax, color='purple', alpha=0.7)
# ax.set_xlabel('Mean IMDS')
# ax.set_title('Average Municipal Development by Department')
# plt.tight_layout()
# plt.show()
```
#### Task 6: Policy Brief on Satellite Data for SDG Monitoring (Independent)
**Objective**: Write a 200-300 word policy brief summarizing your findings.
**Your brief should address**:
1. **Key finding**: What is the relationship between nighttime lights and municipal development in Bolivia?
2. **Magnitude**: How strong is the association? What does the R-squared tell us about predictive power?
3. **Regional variation**: Do some departments show higher development levels? Is there a geographic pattern?
4. **Policy implications**: How could satellite data be used for SDG monitoring in Bolivia?
5. **Limitations**: What can satellite data *not* tell us about development? What other data sources are needed?
**Connection to Research**: The DS4Bolivia project uses machine learning (Random Forest, XGBoost) to predict SDG indicators from satellite embeddings, achieving R² up to 0.57 for extreme energy poverty. Your simple OLS regression provides a baseline for understanding how much satellite data captures about development outcomes.
**Looking ahead**: In subsequent chapters, we will revisit this dataset to:
- Summarize the distribution of development indicators (Chapter 2)
- Test whether development differences are statistically significant (Chapter 4)
- Explore bivariate relationships between NTL and specific SDG outcomes (Chapter 5)
- Add multiple satellite features as predictors (Chapters 10-12)
- Test for regional structural differences (Chapter 14)
- Check model assumptions and diagnostics (Chapter 16)
- Analyze NTL panel data over time (Chapter 17)
```{python}
# Your code here: Additional analysis for the policy brief
#
# You might want to:
# 1. Create a summary table of key results
# 2. Generate a visualization that tells a compelling story
# 3. Calculate specific statistics to cite in your brief
# Example: Summary of key results
# print("KEY RESULTS FOR POLICY BRIEF")
# print(f"Sample: {len(reg_data)} municipalities")
# print(f"NTL coefficient: {fit_bol.coef()['ln_NTLpc2017']:.2f}")
# print(f"R-squared: {fit_bol._r2:.2%}")
# print(f"Most developed department: {dept_means['imds'].idxmax()}")
# print(f"Least developed department: {dept_means['imds'].idxmin()}")
```
#### What You've Learned from This Case Study
Through this exploration of satellite data and municipal development in Bolivia, you've applied the Chapter 1 toolkit to a cutting-edge research application:
- **Data loading and exploration**: Worked with a real geospatial dataset covering 339 municipalities
- **Descriptive statistics**: Summarized development indicators and identified high/low performers
- **Visualization**: Created scatter plots revealing the satellite-development relationship
- **Regression analysis**: Quantified how nighttime lights predict development outcomes
- **Regional comparison**: Explored how the relationship varies across Bolivia's departments
- **Critical thinking**: Assessed the potential and limitations of satellite data for SDG monitoring
**Connection to the research**: The DS4Bolivia project extends this simple analysis by incorporating 64-dimensional satellite embeddings and advanced machine learning methods. Your OLS baseline provides the foundation for understanding what these more complex models improve upon.
**This dataset returns throughout the textbook**: Each subsequent chapter applies its specific econometric tools to the DS4Bolivia data, building progressively from univariate summaries (Chapter 2) through panel data analysis (Chapter 17). By the end of the book, you'll have a comprehensive econometric analysis of satellite-based development prediction.
---
**Well done!** You've now explored two real-world datasets—cross-country convergence and Bolivian municipal development—using the fundamental tools of econometrics.