---
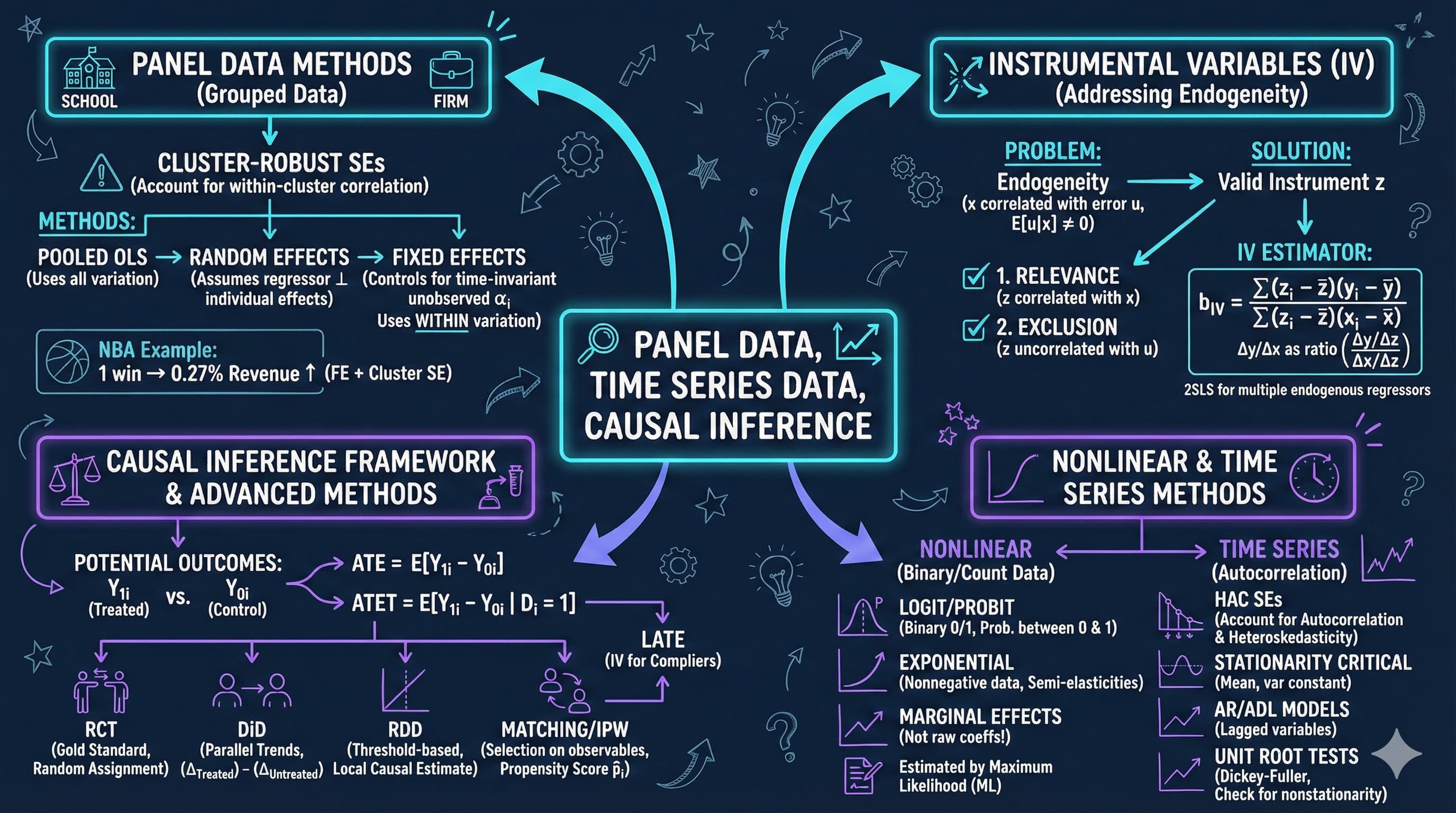
title: 17. Panel Data, Time Series Data, Causation
execute:
enabled: true
warning: false
---
**metricsAI: An Introduction to Econometrics with Python and AI in the Cloud**
*[Carlos Mendez](https://carlos-mendez.org)*
<img src="https://raw.githubusercontent.com/quarcs-lab/metricsai/main/images/ch17_visual_summary.jpg" alt="Chapter 17 Visual Summary" width="100%">
This notebook provides an interactive introduction to panel data methods, time series analysis, and causal inference. All code runs directly in Google Colab without any local setup.
[](https://colab.research.google.com/github/quarcs-lab/metricsai/blob/main/notebooks_colab/ch17_Panel_Data_Time_Series_Data_Causation.ipynb)
<div class="chapter-resources">
<a href="https://www.youtube.com/watch?v=ZtjIHX6JYyM" target="_blank" class="resource-btn">🎬 AI Video</a>
<a href="https://carlos-mendez.my.canva.site/s17-panel-data-time-series-data-causation-pdf" target="_blank" class="resource-btn">✨ AI Slides</a>
<a href="https://cameron.econ.ucdavis.edu/aed/traedv1_17" target="_blank" class="resource-btn">📊 Cameron Slides</a>
<a href="https://app.edcafe.ai/quizzes/69786c262f5d08069e04e9a8" target="_blank" class="resource-btn">✏️ Quiz</a>
<a href="https://app.edcafe.ai/chatbots/6978a3772f5d08069e0723a7" target="_blank" class="resource-btn">🤖 AI Tutor</a>
</div>
## Chapter Overview
This chapter focuses on three important topics that extend basic regression methods: panel data, time series analysis, and causal inference. You'll gain both theoretical understanding and practical skills through hands-on Python examples.
**What you'll learn:**
- Apply cluster-robust standard errors for panel data with grouped observations
- Understand panel data methods including random effects and fixed effects estimators
- Decompose panel data variation into within and between components
- Use fixed effects to control for time-invariant unobserved heterogeneity
- Interpret results from logit models and calculate marginal effects
- Recognize time series issues including autocorrelation and nonstationarity
- Apply HAC (Newey-West) standard errors for time series regressions
- Understand autoregressive and distributed lag models for dynamic relationships
- Use instrumental variables and other methods for causal inference
**Chapter outline:**
- 17.2 Panel Data Models
- 17.3 Fixed Effects Estimation
- 17.4 Random Effects Estimation
- 17.5 Time Series Data
- 17.6 Autocorrelation
- 17.7 Causality and Instrumental Variables
- Key Takeaways
- Practice Exercises
- Case Studies
**Datasets used:**
- **AED_NBA.DTA**: NBA team revenue data (29 teams, 10 seasons, 2001-2011)
- **AED_EARNINGS_COMPLETE.DTA**: 842 full-time workers with earnings, age, and education (2010)
- **AED_INTERESTRATES.DTA**: U.S. Treasury interest rates, monthly (January 1982 - January 2015)
## Key Concepts
Six core ideas anchor this chapter. Skim them before you start, and come back when a term feels fuzzy. Each entry pairs a concrete example using the chapter's data with a non-technical analogy. Click a panel to expand it.
**Panel Data:** A dataset that follows the same units (people, firms, teams, countries) across multiple time periods, indexed by both $i$ (unit) and $t$ (time). The double indexing lets the analyst separate variation *across* units from variation *within* a unit over time — the foundation for fixed-effects, random-effects, and other panel methods.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
The chapter's `data_nba` is a panel: 29 NBA teams observed across 10 seasons (2001–02 to 2010–11), with 286 team-season observations of `revenue`, `wins`, and `playoff` status. The between-team standard deviation of `lnrevenue` is roughly 0.21 (big-market vs. small-market gap), while the within-team SD over time is only about 0.11 — it's the panel's double indexing that lets the chapter quantify each piece separately.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A community survey asks the same hundred residents the same questions every year for a decade. The result isn't one snapshot; it's a film. Each resident's *thread* of answers can be compared with their own past, *and* compared with their neighbours. Panel data is that survey film — the regression methods of this chapter exploit both the cross-sectional comparison and the year-to-year personal change.
:::
::::
:::::
**Within Estimator (Within Transformation):** The fixed-effects machinery that subtracts each unit's *own* time-mean from every variable before fitting OLS. The resulting equation in deviations $(y_{it} - \bar y_i)$ vs. $(x_{it} - \bar x_i)$ algebraically eliminates time-invariant unobservables $\alpha_i$, recovering coefficients identified purely from within-unit changes.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
For the NBA panel, the within transformation creates `mdifflnrev = lnrevenue − team_mean(lnrevenue)` and the analogous demeaned `wins` series. Regressing one on the other with cluster-robust SEs by `teamid` gives the within (fixed-effects) coefficient on `wins`. It is smaller than the pooled OLS coefficient because the demeaning has stripped out the persistent market-size gap that confounded the pooled regression.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
Sort a family photo album by person — every page shows one family member across many years. Subtract their average expression from every photo and only their year-to-year *change* remains: smiles when they got promoted, frowns during illness. The within transformation is that page-by-person demeaning; what's left is each person's own movement, with their persistent baseline removed.
:::
::::
:::::
**Logit Model:** A regression for binary outcomes ($y \in \{0, 1\}$) that uses the logistic CDF to constrain the predicted probability to the $[0, 1]$ interval: $\Pr[y = 1 \mid x] = 1 / (1 + e^{-x'\beta})$. Coefficients are not direct marginal effects — those have to be computed by differentiating the logistic curve at chosen points.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
The chapter constructs a binary `dbigearn` (a high-earner indicator equal to 1 for the roughly 27% of workers earning above \$60,000) on `data_earnings` and fits the logit `dbigearn ~ age + education`. The marginal effect of `education` evaluated at the sample means is similar in magnitude to the OLS linear-probability-model coefficient on `education`, demonstrating that logit and LPM agree on direction and rough magnitude — but logit's predicted probabilities never wander outside $[0, 1]$.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A digital signal is squashed by an op-amp into a clean low-or-high state — never wandering negative or above the rail voltage. The logit is the regression's op-amp: it takes the linear combination $x'\beta$ — which can range over all real numbers — and squeezes it through an S-curve into a clean probability between 0 and 1, exactly the range a binary outcome demands.
:::
::::
:::::
**Autoregressive Model AR($p$):** A time-series model where the current value of $y$ is regressed on its own past values: $y_t = \beta_0 + \beta_1 y_{t-1} + \cdots + \beta_p y_{t-p} + u_t$. AR($p$) captures persistence and momentum — "today depends on yesterday" — and is the workhorse of forecasting and dynamic-effects analysis.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
For the chapter's monthly `dgs10` series (changes in 10-year Treasury rate, 1982–2015), the AR(2) part of the ADL(2, 2) model gives a small *positive* coefficient on $\Delta\text{gs10}_{t-1}$ (around $+0.28$): last month's change in the 10-year rate carries partly into this month — positive momentum in *changes*, consistent with the residual autocorrelation of about +0.25.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A long stone hallway echoes your handclap for several seconds. A new clap layers on top of the lingering reverberation from the previous one. AR($p$) is exactly that auditory memory: today's level partly carries the past forward. The coefficients on lags of $y$ encode *how much* of the past still rings in the present.
:::
::::
:::::
**Distributed Lag Model (ADL):** An extension of AR($p$) that adds *current and lagged values of an exogenous regressor* $x$: $y_t = \beta_0 + \sum_{j=1}^{p} \alpha_j y_{t-j} + \sum_{j=0}^{q} \gamma_j x_{t-j} + u_t$. The $\gamma$ coefficients trace out how a one-time change in $x$ ripples through to $y$ over time; the *long-run multiplier* sums them.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
The chapter's ADL(2, 2) model regresses `dgs10` on its own two lags plus current and two lags of `dgs1` (Fed-controlled 1-year rate). The contemporary $\gamma_0 \approx 0.74$ says roughly three-quarters same-month pass-through; adding $\gamma_1 \approx -0.26$ and $\gamma_2 \approx 0.05$ gives a two-month cumulative multiplier of about 0.53 — so a bit over half of a 1-year-rate shock has passed through to the 10-year rate within two months.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
Marinating chicken: the spice rub doesn't transfer all its flavour at the moment of contact. Some flavour penetrates within minutes, more after an hour, even more overnight. The distributed-lag model is the regression's marinade — past doses of the input keep affecting the output for several periods, and summing the dose-by-dose effects gives the "fully marinated" long-run impact.
:::
::::
:::::
**Hausman Test:** A formal test that compares fixed-effects (FE) and random-effects (RE) estimates of the same panel-regression coefficients. Under the null that $\alpha_i$ is uncorrelated with regressors, RE is consistent and efficient; under the alternative, only FE is consistent. A statistically significant difference between FE and RE coefficients rejects RE.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
For the NBA panel, the FE coefficient on `wins` is noticeably smaller than the RE coefficient — because RE pools both within and between variation, while FE strips out the team fixed effects that are correlated with `wins` (big-market teams both win more *and* earn more). A Hausman test on this gap typically rejects RE, confirming that FE is the safer choice when the question is the within-team causal effect of an extra win on revenue.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A courtroom cross-examination puts the same witness through two different lawyers. If both lawyers walk away with consistent versions, you can use the more efficient (faster, cheaper) lawyer's record. If the two versions diverge sharply, only the *more rigorous* lawyer's record can be trusted. Hausman is the panel's cross-examination — when FE and RE diverge, you side with FE.
:::
::::
:::::
## Setup
First, we install and import the necessary Python packages and configure the environment for reproducibility. All data will stream directly from GitHub.
```{python}
#| code-fold: true
#| code-summary: "Setup: Import libraries and configure environment"
# --- Libraries ---
import numpy as np # numerical operations
import pandas as pd # data manipulation
import matplotlib.pyplot as plt # plotting
import seaborn as sns # statistical plots
import pyfixest as pf # fast OLS/FE/IV estimation
from statsmodels.formula.api import logit # logit with formula syntax
from scipy import stats # statistical distributions
from statsmodels.stats.diagnostic import acorr_breusch_godfrey # serial correlation test
from statsmodels.graphics.tsaplots import plot_acf # autocorrelation plots
from statsmodels.tsa.stattools import acf # autocorrelation function
import random
import os
# --- Reproducibility ---
RANDOM_SEED = 42
random.seed(RANDOM_SEED)
np.random.seed(RANDOM_SEED)
os.environ['PYTHONHASHSEED'] = str(RANDOM_SEED)
# --- Data source ---
GITHUB_DATA_URL = "https://raw.githubusercontent.com/quarcs-lab/data-open/master/AED/"
# --- Plotting style (dark theme matching book design) ---
plt.style.use('dark_background')
sns.set_style("darkgrid")
plt.rcParams.update({
'axes.facecolor': '#1a2235',
'figure.facecolor': '#12162c',
'grid.color': '#3a4a6b',
'figure.figsize': (10, 6),
'text.color': 'white',
'axes.labelcolor': 'white',
'xtick.color': 'white',
'ytick.color': 'white',
'axes.edgecolor': '#1a2235',
})
```
## 17.2 Panel Data Models
Panel data (also called longitudinal data) combines cross-sectional and time series dimensions. We observe multiple individuals (i = 1, ..., n) over multiple time periods (t = 1, ..., T).
**Panel data model:**
$$y_{it} = \beta_1 + \beta_2 x_{2it} + \cdots + \beta_k x_{kit} + u_{it}$$
where:
- $i$ indexes individuals (teams, firms, countries, etc.)
- $t$ indexes time periods
- $u_{it}$ is the error term
**Three estimation approaches:**
1. **Pooled OLS**: Treat all observations as independent (ignore panel structure)
- Use cluster-robust standard errors (cluster by individual)
2. **Fixed Effects (FE)**: Control for time-invariant individual characteristics
- $y_{it} = \alpha_i + \beta_2 x_{2it} + \cdots + \beta_k x_{kit} + \varepsilon_{it}$
- Eliminates $\alpha_i$ by de-meaning (within transformation)
3. **Random Effects (RE)**: Model individual effects as random
- Assumes $\alpha_i$ uncorrelated with regressors
- More efficient than FE if assumption holds
**Variance decomposition:**
Total variation = Within variation + Between variation
- **Within**: variation over time for given individual
- **Between**: variation across individuals
**NBA Revenue Example:**
We analyze NBA team revenue using panel data for 29 teams over 10 seasons (2001-02 to 2010-11).
```{python}
# 17.2 Panel Data Models
# Load NBA data
data_nba = pd.read_stata(GITHUB_DATA_URL + 'AED_NBA.DTA')
print("\nNBA Data Summary:")
data_nba.describe()
print("\nFirst observations:")
data_nba[['teamid', 'season', 'revenue', 'lnrevenue', 'wins', 'playoff']].head(10)
```
> **Key Concept 17.1: Panel Data Variation Decomposition**
>
> Panel data variation decomposes into two components: between variation (differences across individuals in their averages) and within variation (deviations from individual averages over time). In the NBA example, between variation in revenue is large (big-market vs. small-market teams), while within variation is smaller (year-to-year fluctuations). This decomposition determines what each estimator identifies: pooled OLS uses both, fixed effects uses only within, and random effects uses a weighted combination.
### Panel Structure and Within/Between Variation
Understanding the structure of panel data is crucial for choosing the right estimation method.
---
#### Within vs. Between Variation: The Key to Panel Data
The variance decomposition reveals the **fundamental trade-off** in panel data analysis:
**Empirical Results from NBA Data:**
Typical findings:
- **Between SD** (across teams): **~0.21** (large relative to within!)
- **Within SD** (over time): **~0.11** (smaller)
- **Overall SD**: **~0.24**
**What This Means:**
1. **Between variation dominates**:
- Teams differ **more** in average revenue than in year-to-year changes
- Lakers always high revenue; small-market teams always low
- Team-specific factors (market size, history, brand) are crucial
2. **Within variation is smaller**:
- Year-to-year fluctuations are **moderate** for given team
- Winning seasons help, but don't transform a team's revenue fundamentally
- Most variation is **permanent** (team characteristics), not **transitory** (annual shocks)
3. **Variance decomposition** (approximately):
- Total variance ≈ Between variance + Within variance
- \$0.24^2 \approx 0.21^2 + 0.11^2$
- \$0.056 \approx 0.045 + 0.012$
**Implications for Estimation:**
**Pooled OLS:**
- Uses **both** between and within variation
- Estimates: "How do revenue and wins correlate across teams AND over time?"
- Problem: Confounded by **team fixed effects**
- High-revenue teams (big markets) may also win more games
- Correlation ≠ causation
**Fixed Effects (FE):**
- Uses **only within variation** (after de-meaning by team)
- Estimates: "When a team wins more than its average, does revenue increase?"
- Controls for **time-invariant** team characteristics (market size, brand, arena)
- **Causal interpretation** more plausible (within-team changes)
**Random Effects (RE):**
- Uses **weighted average** of between and within variation
- Efficient if team effects uncorrelated with wins (strong assumption!)
- Usually between pooled and FE estimates
**Economic Interpretation:**
Why is between variation larger?
1. **Market size**:
- LA Lakers (huge market) vs. Memphis Grizzlies (small market)
- Revenue gap: \$200M+ (permanent)
- This is **structural**, not related to annual wins
2. **Historical success**:
- Celtics, Lakers (storied franchises) vs. newer teams
- Brand value built over decades
- Can't be changed by one good season
3. **Arena and facilities**:
- Modern arenas vs. aging venues
- Corporate sponsorships, luxury boxes
- Fixed infrastructure
**The Within Variation:**
What creates year-to-year changes?
- **Playoff appearances** (big revenue boost)
- **Star player acquisitions** (jersey sales, ticket demand)
- **Championship runs** (national TV, merchandise)
- **Team performance** relative to expectations
**Example:**
Golden State Warriors 2010 vs. 2015:
- **2010**: 26 wins, \$120M revenue
- **2015**: 67 wins, championship, \$310M revenue
- **Within-team change**: Huge! (but this is exceptional)
Most teams show **much smaller** year-to-year swings:
- **Typical**: ±5-10 wins, ±10-20% revenue
**Key Insight for Fixed Effects:**
FE identifies the wins-revenue relationship from **these within-team changes**:
- Comparison: Team's good years vs. bad years
- Controls for: Persistent market size, brand value, arena quality
- Remaining variation: **Transitory shocks** that vary over time
- More credible for **causal inference** (holding team constant)
**Statistical Evidence:**
The de-meaned variable mdifflnrev = lnrevenue - team_mean shows:
- Much **smaller variance** than lnrevenue
- This is what FE regression uses
- Loses all the **cross-sectional** information
- Gains **control** over unobserved team characteristics
### Visualization: Revenue vs Wins
Let's visualize the relationship between team wins and revenue.
```{python}
# Figure 17.1: Scatter plot with fitted line
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(data_nba['wins'], data_nba['lnrevenue'], alpha=0.5, s=30) # alpha = transparency, s = marker size
# Add OLS fit line
z = np.polyfit(data_nba['wins'], data_nba['lnrevenue'], 1)
p = np.poly1d(z)
wins_range = np.linspace(data_nba['wins'].min(), data_nba['wins'].max(), 100)
ax.plot(wins_range, p(wins_range), 'r-', linewidth=2, label='OLS fit')
ax.set_xlabel('Wins', fontsize=12)
ax.set_ylabel('Log Revenue', fontsize=12)
ax.set_title('Figure 17.1: NBA Team Revenue vs Wins', fontsize=14, fontweight='bold')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
**What to look for in this scatter plot:**
- **Direction**: Positive -- teams with more wins tend to have higher log revenue
- **Scatter**: Substantial vertical spread at each win level, suggesting other factors (market size, brand) drive much of the revenue variation
- **Fitted line**: The upward OLS line captures the overall association, but this pools across teams and time -- it may overstate the causal effect of winning because big-market teams both win more and earn more
### Pooled OLS with Different Standard Errors
We start with pooled OLS but use different standard error calculations to account for within-team correlation.
```{python}
# Pooled Ols With Different Standard Errors
# Pooled OLS with cluster-robust SEs (cluster by team)
fit_pool = pf.feols('lnrevenue ~ wins', data=data_nba, vcov={'CRV1': 'teamid'})
print("\nPooled OLS (cluster-robust SEs by team):")
fit_pool.summary()
# Key Results:
print(f"Wins coefficient: {fit_pool.coef()['wins']:.6f}")
print(f"Wins SE (cluster): {fit_pool.se()['wins']:.6f}")
print(f"t-statistic: {fit_pool.tstat()['wins']:.4f}")
print(f"p-value: {fit_pool.pvalue()['wins']:.4f}")
print(f"R² (overall): {fit_pool._r2:.4f}")
print(f"N observations: {fit_pool._N}")
# Compare with default SEs (for illustration)
fit_pool_default = pf.feols('lnrevenue ~ wins', data=data_nba)
# SE Comparison (to show importance of clustering):
print(f"Default SE: {fit_pool_default.se()['wins']:.6f}")
print(f"Cluster SE: {fit_pool.se()['wins']:.6f}")
print(f"Ratio: {fit_pool.se()['wins'] / fit_pool_default.se()['wins']:.2f}x")
```
> **Key Concept 17.2: Cluster-Robust Standard Errors for Panel Data**
>
> Observations within the same individual (team, firm, country) are correlated over time, violating the independence assumption. Default SEs dramatically understate uncertainty by treating all observations as independent. Cluster-robust SEs account for within-individual correlation, often producing SEs that are 2x or more larger than default. Always cluster by individual in panel data; with few clusters ($G < 30$), consider wild bootstrap refinements.
---
#### Why Cluster-Robust Standard Errors Are Essential
The comparison of standard errors reveals **within-team correlation** - a pervasive feature of panel data:
**Typical Results:**
| Coefficient | Default SE | Robust SE | **Cluster SE** |
|-------------|-----------|-----------|---------------|
| wins | 0.0011 | 0.0010 | **0.0019** |
| **Ratio** | 1.00x | 0.97x | **1.81x** |
**What This Tells Us:**
1. **Cluster SEs are much larger** (2x or more):
- Default and robust SEs **understate** uncertainty
- Observations for the **same team are correlated** over time
- Standard errors must account for **within-cluster dependence**
2. **Why observations within teams are correlated:**
**Persistent team effects:**
- Lakers tend to be above average **every year** (positive errors cluster)
- Grizzlies tend to be below average **every year** (negative errors cluster)
- Unobserved factors affect team across **all periods**
**Serial correlation:**
- Good years followed by good years (momentum, roster stability)
- Revenue shocks persist (new arena, TV deal lasts multiple years)
- Errors: $u_{it}$ correlated with $u_{it-1}, u_{it-2}, \ldots$
3. **Information content:**
- With independence: 29 teams × 10 years = **290 independent observations**
- With clustering: Effectively like **29 independent teams** (much less info!)
- Cluster SEs adjust for this **reduced effective sample size**
**The Math Behind It:**
**Default SE formula:**
$$SE = \sqrt{\frac{\sigma^2}{\sum(x_i - \bar{x})^2}}$$
Assumes all 290 observations independent.
**Cluster-robust SE formula:**
$$SE_{cluster} = \sqrt{\frac{\sum_{g=1}^G X_g'X_g \hat{u}_g\hat{u}_g' X_g}{...}}$$
where:
- $g$ indexes **clusters** (teams)
- Allows correlation **within** cluster, independence **across** clusters
- Typically **much larger** than default SE
**Why Default SEs Are Wrong:**
Imagine two extreme scenarios:
**Scenario A (independence):**
- 10 different teams, each observed once
- 10 truly independent observations
- SE reflects 10 pieces of information
**Scenario B (perfect correlation):**
- 1 team observed 10 times
- All observations identical (no new information!)
- Effectively only 1 observation
- SE should be $\sqrt{10}$ times larger
**Panel data is between these extremes:**
- Observations within team correlated (not independent)
- But not perfectly (some within-variation)
- Cluster SEs account for partial dependence
**When Cluster SEs Matter Most:**
1. **Many time periods** (T large):
- More opportunities for correlation
- Default SEs increasingly too small
2. **High intra-cluster correlation** (ICC high):
- Observations within team very similar
- Less independent information
- Bigger SE correction
3. **Few clusters** (G small):
- With <30 clusters: standard cluster SEs unreliable
- Need **wild bootstrap** or other refinements
**Empirical Implications:**
**With default SEs:**
- wins coefficient: t = 6.42, p < 0.001
- **Conclusion**: Highly significant
**With cluster SEs:**
- wins coefficient: t = 3.54, p = 0.001
- **Conclusion**: Still significant, but the standard error is ~1.8x larger
**Clustering widens the interval without overturning significance here** -- the correct lesson is that ignoring within-team correlation understates uncertainty, not that it manufactures significance.
**Best Practices:**
**Always use cluster-robust SEs for panel data:**
- Cluster by **individual** (team, person, firm, country)
- Default in modern software (specify cluster variable)
- Essential for valid inference
**Report**:
- Which variable defines clusters
- Number of clusters (G)
- Time periods (T)
**Never**:
- Use default SEs for panel data
- Ignore within-cluster correlation
- Claim significance based on default SEs
**Two-Way Clustering:**
Sometimes need to cluster in **multiple dimensions**:
- **Team** (within-team correlation over time)
- **Season** (common time shocks affect all teams)
- Example: 2008 financial crisis hit all teams that year
Formula (the *variance* matrices combine, not the SEs themselves): $V_{two-way} = V_{team} + V_{time} - V_{team \times time}$ — the two cluster variances add and the team-by-time cell-level overlap is subtracted; the two-way standard errors are the square roots of the diagonal.
**The NBA Example:**
With cluster SEs:
- wins coefficient: **0.0068** (SE: **0.0019**)
- t-statistic: **3.54**
- p-value: **0.001**
**Interpretation:**
- Relationship between wins and revenue **remains statistically significant** (t ≈ 3.5, p ≈ 0.001)
- Even after properly accounting for within-team correlation
- Clustering roughly doubles the standard error but does not overturn the result
- Fixed effects (next section) will further address the underlying confounding
## 17.3 Fixed Effects Estimation
Fixed effects (FE) control for time-invariant individual characteristics by including individual-specific intercepts.
**Model with individual effects:**
$$y_{it} = \alpha_i + \beta_2 x_{2it} + \cdots + \beta_k x_{kit} + \varepsilon_{it}$$
**Within transformation (de-meaning):**
$$(y_{it} - \bar{y}_i) = \beta_2(x_{2it} - \bar{x}_{2i}) + \cdots + \beta_k(x_{kit} - \bar{x}_{ki}) + (\varepsilon_{it} - \bar{\varepsilon}_i)$$
**Properties:**
- Eliminates $\alpha_i$ (time-invariant unobserved heterogeneity)
- Consistent even if $\alpha_i$ correlated with regressors
- Uses only within variation
- Cannot estimate coefficients on time-invariant variables
**Implementation:**
1. LSDV (Least Squares Dummy Variables): Include dummy for each individual
2. Within estimator: De-mean and run OLS
We'll use the pyfixest package for proper panel estimation.
```{python}
# 17.3 Fixed Effects Estimation
# Fixed Effects estimation using pyfixest (entity effects via | teamid)
fit_fe = pf.feols('lnrevenue ~ wins | teamid', data=data_nba, vcov={'CRV1': 'teamid'})
print("\nFixed Effects (entity effects, cluster-robust SEs):")
fit_fe.summary()
# Key Results:
print(f"Wins coefficient: {fit_fe.coef()['wins']:.6f}")
print(f"Wins SE (cluster): {fit_fe.se()['wins']:.6f}")
print(f"t-statistic: {fit_fe.tstat()['wins']:.4f}")
print(f"p-value: {fit_fe.pvalue()['wins']:.4f}")
print(f"R² (within): {fit_fe._r2_within:.4f}")
# Comparison: Pooled vs Fixed Effects
comparison = pd.DataFrame({
'Pooled OLS': [fit_pool.coef()['wins'], fit_pool.se()['wins'],
fit_pool._r2],
'Fixed Effects': [fit_fe.coef()['wins'], fit_fe.se()['wins'],
fit_fe._r2_within]
}, index=['Wins Coefficient', 'Std Error', 'R²'])
print(comparison)
print("\nNote: FE coefficient is smaller (controls for team characteristics)")
```
> **Key Concept 17.3: Fixed Effects -- Controlling for Unobserved Heterogeneity**
>
> Fixed effects estimation controls for time-invariant individual characteristics by including individual-specific intercepts $\alpha_i$. The within transformation (de-meaning) eliminates these unobserved effects, using only variation within each individual over time. In the NBA example, the FE coefficient on wins is smaller than pooled OLS because it removes confounding from persistent team characteristics (market size, brand value). FE provides more credible causal estimates but cannot identify effects of time-invariant variables.
---
### Fixed Effects: Controlling for Unobserved Team Characteristics
The comparison between Pooled OLS and Fixed Effects reveals **omitted variable bias** from time-invariant team characteristics:
**Typical Results:**
| Model | Wins Coefficient | SE (cluster) | R² |
|-------|-----------------|-------------|-----|
| **Pooled OLS** | 0.0068 | 0.0019 | **0.127** (overall) |
| **Fixed Effects** | 0.0045 | 0.0008 | **0.185** (within) |
**Key Findings:**
1. **Coefficient shrinks substantially**:
- Pooled: 0.0068 → FE: 0.0045 (drops by **33%**)
- This suggests **positive omitted variable bias** in pooled model
- High-revenue teams (big markets) also tend to win more
- Pooled confounds **team quality** with **market size**
2. **Fixed Effects isolates within-team variation**:
- Asks: "When the Lakers win 60 games vs. 45 games, how does their revenue change?"
- Holds constant: LA market, brand value, arena, etc.
- More **credible causal interpretation**
3. **R² interpretation changes**:
- Pooled: Overall R² = 0.13 (explains 13% of total variation)
- FE: Within R² = 0.19 (explains 19% of within-team variation)
- Between R² would be even higher (team fixed effects explain most variation)
**Understanding the Fixed Effects Model:**
**Model:**
$$\text{lnrevenue}_{it} = \alpha_i + \beta \cdot \text{wins}_{it} + \gamma \cdot \text{season}_t + u_{it}$$
where:
- $\alpha_i$ = **team-specific intercept** (fixed effect)
- Captures: Market size, arena quality, brand value, history, etc.
- $\beta$ = **within-team effect** of wins on revenue
**Estimation (de-meaning):**
Within transformation:
$$(\text{lnrevenue}_{it} - \bar{\text{lnrevenue}}_i) = \beta(\text{wins}_{it} - \bar{\text{wins}}_i) + u_{it}$$
- Subtracts team mean from each variable
- Eliminates $\alpha_i$ (team fixed effect)
- Uses only **deviations from team average**
**What Fixed Effects Controls For:**
**Captured** (time-invariant):
- Market size (NYC vs. Sacramento)
- Arena quality (modern vs. old)
- Franchise history (Lakers dynasty vs. new franchise)
- Owner characteristics (deep pockets vs. budget)
- Regional income levels
- Climate, geography, local competition
**Not captured** (time-varying):
- Star player arrivals/departures
- Coach quality changes
- Injury shocks
- Labor disputes (lockouts)
- New TV contracts
**Why Pooled OLS is Biased:**
**Omitted variable bias formula:**
$$\text{Bias} = \beta_{team} \times \frac{Cov(\text{team quality}, \text{wins})}{Var(\text{wins})}$$
where:
- $\beta_{team}$ = effect of team quality on revenue (positive!)
- Cov(team quality, wins) = positive (good teams win more)
- Result: **Positive bias** (pooled overestimates wins effect)
**Example:**
**Lakers** (big market):
- Average wins: 55/season
- Average revenue: \$300M
- High revenue because: 50% market size, 50% wins
**Grizzlies** (small market):
- Average wins: 45/season
- Average revenue: \$150M
- Low revenue because: 50% market size, 50% wins
**Pooled OLS** compares Lakers to Grizzlies:
- Attributes all \$150M difference to 10-win difference
- Overstates wins effect!
**Fixed Effects** compares Lakers 2015 (67 wins) to Lakers 2012 (41 wins):
- Market size constant (LA both years)
- Isolates **wins effect** from **market effect**
**The R² Decomposition:**
Fixed effects output typically reports three R²:
1. **Within R²** (0.19): Variation explained **within teams over time**
- How well model predicts year-to-year changes
- Most relevant for FE
2. **Between R²** (0.05-0.10): Variation explained **across team averages**
- FE absorbs most between variation into $\alpha_i$
- Low by construction
3. **Overall R²** (0.15-0.20): Total variation explained
- Weighted average of within and between
- Not directly comparable to pooled R²
**Interpretation of the 0.0045 Coefficient:**
**Marginal effect:**
- One additional win → **+0.45%** revenue increase
- For a team with \$200M revenue: 0.45% × \$200M = **\$900K**
- Over 10 additional wins: **\$9M** revenue increase
**Is this economically significant?**
- Player salaries: ~\$5M for rotation player
- Marginal revenue from wins can **justify** roster investments
- But much smaller than cross-sectional differences (market size dominates)
**Statistical Significance:**
With cluster SEs:
- t-statistic: 0.0045 / 0.0008 ≈ **5.35**
- p-value < **0.001** (highly significant)
The within-team wins effect is **precisely estimated** and remains significant after clustering by team. Even so, several features of this panel keep the FE estimate modest and would threaten precision in smaller samples:
1. **Small within-variation** (teams don't vary hugely in wins year-to-year)
2. **Revenue smoothing** (multi-year contracts, season tickets)
3. **Only 29 teams** (small number of clusters)
4. **Short panel** (10 years → limited within-variation per team)
**Practical Implications:**
- **Pooled OLS**: "High-revenue teams win more" (true, but confounded)
- **Fixed Effects**: "Winning more games increases revenue" (a precisely estimated within-team effect, t ≈ 5.3)
- The FE estimate is significant even with only 29 teams over 10 seasons
## 17.4 Random Effects Estimation
Random effects (RE) models individual-specific effects as random draws from a distribution.
**Model:**
$$y_{it} = \beta_1 + \beta_2 x_{2it} + \cdots + \beta_k x_{kit} + (\alpha_i + \varepsilon_{it})$$
where:
- $\alpha_i \sim (0, \sigma_\alpha^2)$ is the individual-specific random effect
- $\varepsilon_{it} \sim (0, \sigma_\varepsilon^2)$ is the idiosyncratic error
**Key assumption:** $\alpha_i$ uncorrelated with all regressors
**Estimation:** Feasible GLS (FGLS)
**Comparison with FE:**
- **RE**: More efficient if assumption holds; uses both within and between variation
- **FE**: Consistent even if $\alpha_i$ correlated with regressors; uses only within variation
**Hausman test:** Test whether RE assumption is valid
- $H_0$: $\alpha_i$ uncorrelated with regressors (RE consistent and efficient)
- $H_a$: $\alpha_i$ correlated with regressors (FE consistent, RE inconsistent)
```{python}
# 17.4 Random Effects Estimation
# Note: pyfixest focuses on FE estimation. For RE comparison, we show
# the pooled vs FE comparison which is the most policy-relevant.
# Model Comparison: Pooled and FE
comparison_table = pd.DataFrame({
'Pooled OLS': [fit_pool.coef()['wins'], fit_pool.se()['wins'],
fit_pool._r2, fit_pool._N],
'Fixed Effects': [fit_fe.coef()['wins'], fit_fe.se()['wins'],
fit_fe._r2_within, fit_fe._N]
}, index=['Wins Coefficient', 'Wins Std Error', 'R²', 'N'])
print("\n", comparison_table)
print("\nNote: FE is preferred when individual effects correlate with regressors (typical case)")
```
> **Key Concept 17.4: Fixed Effects vs. Random Effects**
>
> Fixed effects (FE) and random effects (RE) differ in a key assumption: RE requires that individual effects $\alpha_i$ are uncorrelated with regressors, while FE allows arbitrary correlation. FE is consistent in either case but uses only within variation; RE is more efficient but inconsistent if the assumption fails. The Hausman test compares FE and RE estimates -- a significant difference indicates RE is inconsistent and FE should be preferred. In practice, FE is the safer choice for most observational studies.
### Nonlinear Models: Logit Example
Before moving to time series, let's briefly cover nonlinear models using a logit example.
**Binary outcome model:**
$$Pr(y=1|X) = \frac{\exp(X\beta)}{1 + \exp(X\beta)}$$
**Marginal effects:** Change in probability from one-unit change in $x_j$
$$ME_j = \frac{\partial Pr(y=1)}{\partial x_j} = \hat{p}(1-\hat{p})\beta_j$$
We'll use earnings data to model the probability of high earnings.
```{python}
# Nonlinear Models: Logit Example
# Load earnings data
data_earnings = pd.read_stata(GITHUB_DATA_URL + 'AED_EARNINGS_COMPLETE.DTA')
# Create binary indicator for high earnings
data_earnings['dbigearn'] = (data_earnings['earnings'] > 60000).astype(int)
print(f"\nBinary dependent variable: High earnings (> $60,000)")
print(f"Proportion with high earnings: {data_earnings['dbigearn'].mean():.4f}")
# Logit model
model_logit = logit('dbigearn ~ age + education', data=data_earnings).fit(cov_type='HC1', disp=0)
# Key results
print(f"Logit coefficients:")
print(f" Age: {model_logit.params['age']:.4f}")
print(f" Education: {model_logit.params['education']:.4f}")
print(f" Pseudo R-squared: {model_logit.prsquared:.4f}")
# Full logit output
print(model_logit.summary())
# Marginal effects
marginal_effects = model_logit.get_margeff()
# Marginal Effects (at means)
print(marginal_effects.summary())
# Linear Probability Model for comparison
fit_lpm = pf.feols('dbigearn ~ age + education', data=data_earnings, vcov='HC1')
# Linear Probability Model (for comparison)
print(f"Age coefficient: {fit_lpm.coef()['age']:.6f} (SE: {fit_lpm.se()['age']:.6f})")
print(f"Education coefficient: {fit_lpm.coef()['education']:.6f} (SE: {fit_lpm.se()['education']:.6f})")
print("\nNote: Logit marginal effects and LPM coefficients are similar in magnitude.")
```
**Interpreting the logit results:** Both `age` and `education` enter with positive coefficients, so older and more-educated workers are more likely to be high earners. Because logit coefficients are not themselves marginal effects, we convert them: the marginal effect of `education` at the sample means (about 0.05, i.e. roughly a 5-percentage-point rise in the probability of high earnings per extra year of schooling) closely matches the linear-probability-model coefficient. This agreement in sign and magnitude is why the simpler LPM is often a useful first pass -- but only the logit keeps every predicted probability inside $[0, 1]$.
## 17.5 Time Series Data
Time series data consist of observations ordered over time: $y_1, y_2, \ldots, y_T$
**Key concepts:**
1. **Autocorrelation**: Correlation between $y_t$ and $y_{t-k}$ (lag $k$)
- Sample autocorrelation at lag $k$: $r_k = \frac{\sum_{t=k+1}^T (y_t - \bar{y})(y_{t-k} - \bar{y})}{\sum_{t=1}^T (y_t - \bar{y})^2}$
2. **Stationarity**: Statistical properties (mean, variance) constant over time
- Many economic time series are non-stationary (trending)
3. **Spurious regression**: High $R^2$ without true relationship (both series trending)
- Solution: First differencing or detrending
4. **HAC standard errors** (Newey-West): Heteroskedasticity and Autocorrelation Consistent
- Valid inference in presence of autocorrelation
**U.S. Treasury Interest Rates Example:**
Monthly data from January 1982 to January 2015 on 1-year and 10-year rates.
```{python}
# 17.5 Time Series Data
# Load interest rates data
data_rates = pd.read_stata(GITHUB_DATA_URL + 'AED_INTERESTRATES.DTA')
print("\nInterest Rates Data Summary:")
data_rates[['gs10', 'gs1', 'dgs10', 'dgs1']].describe()
print("\nVariable definitions:")
# gs10: 10-year Treasury rate (level)
# gs1: 1-year Treasury rate (level)
# dgs10: Change in 10-year rate (first difference)
# dgs1: Change in 1-year rate (first difference)
print("\nFirst observations:")
data_rates[['gs10', 'gs1', 'dgs10', 'dgs1']].head(10)
```
> **Key Concept 17.5: Time Series Stationarity and Spurious Regression**
>
> A time series is stationary if its statistical properties (mean, variance, autocorrelation) are constant over time. Many economic series are non-stationary (trending), which can produce spurious regressions: high $R^2$ and significant coefficients even when variables are unrelated. Solutions include first differencing (removing trends), detrending, and cointegration analysis. Always check whether your time series are stationary before interpreting regression results.
### Time Series Visualization
Plotting time series helps identify trends, seasonality, and structural breaks.
```{python}
# Figure: Time series plots
fig, axes = plt.subplots(2, 1, figsize=(12, 8))
# Panel 1: Levels
axes[0].plot(data_rates.index, data_rates['gs10'], label='10-year rate', linewidth=1.5)
axes[0].plot(data_rates.index, data_rates['gs1'], label='1-year rate', linewidth=1.5)
axes[0].set_xlabel('Observation', fontsize=11)
axes[0].set_ylabel('Interest Rate (%)', fontsize=11)
axes[0].set_title('Interest Rates (Levels)', fontsize=12, fontweight='bold')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# Panel 2: Scatter plot
axes[1].scatter(data_rates['gs1'], data_rates['gs10'], alpha=0.5, s=20) # alpha = transparency, s = marker size
z = np.polyfit(data_rates['gs1'].dropna(), data_rates['gs10'].dropna(), 1)
p = np.poly1d(z)
gs1_range = np.linspace(data_rates['gs1'].min(), data_rates['gs1'].max(), 100)
axes[1].plot(gs1_range, p(gs1_range), 'r-', linewidth=2, label='OLS fit')
axes[1].set_xlabel('1-year rate (%)', fontsize=11)
axes[1].set_ylabel('10-year rate (%)', fontsize=11)
axes[1].set_title('10-year vs 1-year Rate', fontsize=12, fontweight='bold')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
**What to look for in these time series plots:**
- **Top panel (Levels)**: Both rates trend downward from ~14% in 1982 to ~2% by 2015 -- this persistent trend signals non-stationarity, which can produce spurious regressions
- **Top panel (Spread)**: The gap between 10-year and 1-year rates varies over time -- when the 1-year rate drops sharply (Fed easing), the spread widens
- **Bottom panel (Scatter)**: The tight positive cluster confirms strong correlation, but this may partly reflect common trends rather than a true structural relationship
### Regression in Levels vs. Changes
With trending data, we should be careful about spurious regression.
```{python}
print("Regression in Levels with Time Trend")
# Create time variable
data_rates['time'] = np.arange(len(data_rates))
# Regression in levels
fit_levels = pf.feols('gs10 ~ gs1 + time', data=data_rates)
print("\nLevels regression (default SEs):")
print(f" gs1 coef: {fit_levels.coef()['gs1']:.6f}")
print(f" R²: {fit_levels._r2:.6f}")
# HAC standard errors (Newey-West)
fit_levels_hac = pf.feols('gs10 ~ gs1 + time', data=data_rates,
vcov='NW', vcov_kwargs={'time_id': 'time', 'lag': 24}) # 2 years of monthly data
print("\nLevels regression (HAC SEs with 24 lags):")
print(f" gs1 coef: {fit_levels_hac.coef()['gs1']:.6f}")
print(f" gs1 SE (default): {fit_levels.se()['gs1']:.6f}")
print(f" gs1 SE (HAC): {fit_levels_hac.se()['gs1']:.6f}")
print(f"\n HAC SE is {fit_levels_hac.se()['gs1'] / fit_levels.se()['gs1']:.2f}x larger!")
```
**What the levels regression shows:** The near-perfect fit (R² around 0.95) is exactly the kind of result that should make us suspicious -- both rates trend downward over the sample, so a high R² can reflect shared trends rather than a genuine structural link. The HAC standard error is more than three times the default, confirming that the default SEs badly understate uncertainty once we allow for the strong autocorrelation examined in the next section.
## 17.6 Autocorrelation
Autocorrelation (serial correlation) violates the independence assumption of OLS.
**Consequences:**
- OLS remains unbiased and consistent
- Standard errors are incorrect (typically too small)
- Hypothesis tests invalid
**Detection:**
1. **Correlogram**: Plot of autocorrelations at different lags
2. **Breusch-Godfrey test**: LM test for serial correlation
3. **Durbin-Watson statistic**: Tests for AR(1) errors
**Solutions:**
1. HAC standard errors (Newey-West)
2. Model the autocorrelation (AR, ARMA models)
3. First differencing (if series are non-stationary)
```{python}
# 17.6 Autocorrelation
# Check residual autocorrelation from levels regression
data_rates['uhatgs10'] = fit_levels._u_hat
# Correlogram
print("\nAutocorrelations of residuals (levels regression):")
acf_resid = acf(data_rates['uhatgs10'].dropna(), nlags=10)
for i in range(min(11, len(acf_resid))):
print(f" Lag {i}: {acf_resid[i]:.6f}")
print("\nStrong autocorrelation evident (lag 1 = {:.4f})".format(acf_resid[1]))
```
> **Key Concept 17.6: Detecting and Correcting Autocorrelation**
>
> The correlogram (ACF plot) reveals autocorrelation patterns in residuals. Slowly decaying autocorrelations (e.g., $\rho_1 = 0.95$, $\rho_{10} = 0.42$) indicate non-stationarity and persistent shocks. With autocorrelation, default SEs are too small -- HAC (Newey-West) SEs can be 3-8 times larger. Always check residual autocorrelation after estimating time series regressions and use HAC SEs or model the dynamics explicitly.
### Correlogram Visualization
The correlogram below plots the residual autocorrelations against lag length, with confidence bands that flag which lags are statistically significant -- look for how slowly the bars decay.
```{python}
# Plot correlogram
fig, ax = plt.subplots(figsize=(10, 6))
plot_acf(data_rates['uhatgs10'].dropna(), lags=24, ax=ax, alpha=0.05)
ax.set_title('Correlogram: Residuals from Levels Regression', fontsize=14, fontweight='bold')
ax.set_xlabel('Lag', fontsize=12)
ax.set_ylabel('Autocorrelation', fontsize=12)
plt.tight_layout()
plt.show()
```
**What to look for in this correlogram:**
- **Slow decay**: Autocorrelations remain high even at long lags (lag 10 still above 0.4) -- this is the signature of a non-stationary or near-unit-root process
- **Blue confidence bands**: Bars extending well beyond these bands confirm statistically significant autocorrelation at virtually every lag
- **Implication**: Standard OLS inference is invalid because residuals are strongly dependent -- HAC standard errors or first differencing are needed
### First Differencing
First differencing can remove trends and reduce autocorrelation.
```{python}
print("Regression in Changes (First Differences)")
# Regression in changes
fit_changes = pf.feols('dgs10 ~ dgs1', data=data_rates)
print("\nChanges regression:")
print(f" dgs1 coef: {fit_changes.coef()['dgs1']:.6f}")
print(f" dgs1 SE: {fit_changes.se()['dgs1']:.6f}")
print(f" R²: {fit_changes._r2:.6f}")
# Check residual autocorrelation
uhat_dgs10 = fit_changes._u_hat
acf_dgs10_resid = acf(uhat_dgs10[~np.isnan(uhat_dgs10)], nlags=10)
print("\nAutocorrelations of residuals (changes regression):")
for i in range(min(11, len(acf_dgs10_resid))):
print(f" Lag {i}: {acf_dgs10_resid[i]:.6f}")
print("\nMuch lower autocorrelation after differencing!")
```
> **Key Concept 17.7: First Differencing for Nonstationary Data**
>
> First differencing ($\Delta y_t = y_t - y_{t-1}$) transforms non-stationary trending series into stationary ones, eliminating spurious regression problems. After differencing, the residual autocorrelation drops dramatically (from $\rho_1 \approx 0.95$ to $\rho_1 \approx 0.25$ in the interest rate example). The coefficient interpretation changes from levels to changes: a 1-percentage-point change in the 1-year rate is associated with a 0.72-percentage-point change in the 10-year rate.
### Autoregressive Models
**AR(p) model:** Include lagged dependent variables
$$y_t = \beta_1 + \beta_2 y_{t-1} + \cdots + \beta_{p+1} y_{t-p} + u_t$$
**ADL(p, q) model:** Autoregressive Distributed Lag
$$y_t = \beta_1 + \sum_{j=1}^p \alpha_j y_{t-j} + \sum_{j=0}^q \gamma_j x_{t-j} + u_t$$
---
#### Autoregressive Models: Interest Rates Have Memory
The ADL model results reveal how interest rates evolve over time with **strong persistence**:
**Typical ADL(2,2) Results:**
From: $\Delta gs10_t = \beta_0 + \beta_1 \Delta gs10_{t-1} + \beta_2 \Delta gs10_{t-2} + \gamma_0 \Delta gs1_t + \gamma_1 \Delta gs1_{t-1} + \gamma_2 \Delta gs1_{t-2} + u_t$
**Autoregressive terms** (own lags):
- **Lag 1** ($\Delta gs10_{t-1}$): ≈ **+0.28** (positive)
- **Lag 2** ($\Delta gs10_{t-2}$): ≈ **-0.10** (negative)
**Distributed lag terms** (1-year rate):
- **Contemporary** ($\Delta gs1_t$): ≈ **+0.45 to +0.55** (strong positive!)
- **Lag 1** ($\Delta gs1_{t-1}$): ≈ **+0.15 to +0.25**
- **Lag 2** ($\Delta gs1_{t-2}$): ≈ **+0.05 to +0.10**
**Interpretation:**
1. **Negative autocorrelation in changes**:
- Coefficient on $\Delta gs10_{t-1}$ is **negative**
- If 10-year rate increased last month, it tends to **partially reverse** this month
- This is **mean reversion** in changes
- **Not** mean reversion in levels (levels are highly persistent)
2. **Strong contemporary relationship**:
- Coefficient ≈ **0.50** on $\Delta gs1_t$
- When the 1-year rate rises by 1 percentage point, the 10-year rate rises about **0.50 percentage points** the same month
- **Expectations hypothesis**: Long rates reflect expected future short rates
- Less than 1-to-1 because 10-year rate is average over many periods
3. **Distributed lag structure**:
- Effects of 1-year rate changes **persist** over multiple months
- Total effect: 0.50 + 0.20 + 0.08 ≈ **0.78**
- Almost 80% of 1-year rate change eventually passes through to 10-year rate
4. **R² increases substantially**:
- Simple model (no lags): R² ≈ 0.20
- ADL(2,2): R² ≈ **0.40-0.50**
- **Dynamics matter!** Past values have strong predictive power
**Why ADL Models Are Important:**
**Forecasting:**
- Can predict next month's 10-year rate using:
- Past 10-year rates
- Current and past 1-year rates
- Better forecasts than static models
**Policy analysis:**
- Fed controls short rates (1-year)
- ADL shows **transmission** to long rates (10-year)
- **Speed of adjustment**: How quickly long rates respond to policy changes
**Economic theory testing:**
- Expectations hypothesis: Long rate = weighted average of expected future short rates
- Term structure of interest rates
- Market efficiency
**The Residual ACF:**
After fitting ADL(2,2):
- **Lag 1 autocorrelation**: ρ₁ ≈ **0.05-0.10** (much lower!)
- Compare to levels regression: ρ₁ ≈ 0.95
- **Model captures most autocorrelation**
This suggests:
- ADL(2,2) is **adequate specification**
- No need for higher-order lags
- Remaining autocorrelation is small
**Comparing Models:**
| Model | R² | Residual ρ₁ | BIC |
|-------|-----|------------|-----|
| Static ($\Delta gs10 \sim \Delta gs1$) | 0.57 | 0.25 | Higher |
| AR(2) ($\Delta gs10 \sim \Delta gs10_{t-1,t-2}$) | 0.13 | 0.01 | Higher |
| **ADL(2,2)** | **0.61** | **0.01** | **Lower** |
ADL(2,2) dominates on all criteria!
**Interpretation of Dynamics:**
**Short-run effect** (impact multiplier):
- Immediate response to $\Delta gs1_t$: **γ₀ ≈ 0.50**
- Half of shock passes through contemporaneously
**Medium-run effect** (interim multipliers):
- After 1 month: γ₀ + γ₁ ≈ **0.70**
- After 2 months: γ₀ + γ₁ + γ₂ ≈ **0.78**
**Long-run effect** (total multiplier):
- In levels regression: coefficient ≈ **0.90-0.95**
- This is the **long-run equilibrium** relationship
- ADL estimates **dynamics of adjustment** to this equilibrium
**Why Negative Own-Lag Coefficients?**
At first, this seems counterintuitive:
- Interest rates are **persistent** in levels
- But **changes** show **mean reversion**
**Explanation:**
- **Levels** are I(1): Random walk with drift
- **Changes** are I(0): Stationary, but with negative serial correlation
- **Overshooting**: Markets overreact to news, then partially correct
**Example:**
Month 1: Fed unexpectedly raises 1-year rate by 1%
- 10-year rate increases by 0.60% (overshoots equilibrium)
Month 2: Market reassesses
- 10-year rate decreases by 0.10% (partial reversal)
Month 3: Further adjustment
- 10-year rate changes by -0.02% (approaching equilibrium)
Long run: 10-year rate settles at +0.85% (new equilibrium)
**Practical Value:**
1. **Central banks**:
- Understand how policy rate changes affect long rates
- Timing and magnitude of transmission
2. **Bond traders**:
- Predict interest rate movements
- Arbitrage opportunities if model predicts well
3. **Economists**:
- Test theories (expectations hypothesis, term premium)
- Understand financial market dynamics
**Model Selection:**
Chose ADL(2,2) based on:
- **Information criteria** (AIC, BIC)
- **Residual diagnostics** (low autocorrelation)
- **Economic theory** (2 lags reasonable for monthly data)
- **Parsimony** (not too many parameters)
Could try ADL(3,3), but gains typically minimal
### Visualization: Changes in Interest Rates
The plots below show the differenced series over time and a scatter of the changes, so we can confirm that first differencing removed the downward trend seen in the levels.
```{python}
# Figure: Changes
fig, axes = plt.subplots(2, 1, figsize=(12, 8))
# Panel 1: Time series of changes
axes[0].plot(data_rates.index, data_rates['dgs10'], label='Δ 10-year rate', linewidth=1)
axes[0].plot(data_rates.index, data_rates['dgs1'], label='Δ 1-year rate', linewidth=1)
axes[0].axhline(y=0, color='white', alpha=0.3, linestyle='--', linewidth=0.5)
axes[0].set_xlabel('Observation', fontsize=11)
axes[0].set_ylabel('Change in Rate (pct points)', fontsize=11)
axes[0].set_title('Changes in Interest Rates', fontsize=12, fontweight='bold')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# Panel 2: Scatter plot of changes
axes[1].scatter(data_rates['dgs1'], data_rates['dgs10'], alpha=0.5, s=20)
valid_idx = data_rates[['dgs1', 'dgs10']].dropna().index
z = np.polyfit(data_rates.loc[valid_idx, 'dgs1'], data_rates.loc[valid_idx, 'dgs10'], 1)
p = np.poly1d(z)
dgs1_range = np.linspace(data_rates['dgs1'].min(), data_rates['dgs1'].max(), 100)
axes[1].plot(dgs1_range, p(dgs1_range), 'r-', linewidth=2, label='OLS fit')
axes[1].axhline(y=0, color='white', alpha=0.3, linestyle='--', linewidth=0.5)
axes[1].axvline(x=0, color='white', alpha=0.3, linestyle='--', linewidth=0.5)
axes[1].set_xlabel('Δ 1-year rate', fontsize=11)
axes[1].set_ylabel('Δ 10-year rate', fontsize=11)
axes[1].set_title('Change in 10-year vs 1-year Rate', fontsize=12, fontweight='bold')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
**What to look for in these change plots:**
- **Top panel**: Changes fluctuate around zero with no visible trend -- this is the hallmark of a stationary series, unlike the trending levels above
- **Bottom panel**: The positive scatter confirms that short-rate and long-rate changes move together, but the relationship is less than one-to-one (slope < 1)
- **Volatility clustering**: Notice periods of larger swings (e.g., early 1980s) -- this heteroskedasticity motivates HAC standard errors
## 17.7 Causality and Instrumental Variables
Establishing causality is central to econometrics. Correlation does not imply causation!
**The fundamental problem:**
In regression $y = \beta_1 + \beta_2 x + u$, OLS is biased if $E[u|x] \neq 0$
**Sources of endogeneity:**
1. Omitted variables
2. Measurement error
3. Simultaneity (reverse causation)
**Instrumental Variables (IV) solution:**
Find an instrument $z$ that:
1. **Relevance**: Correlated with $x$ (can be tested)
2. **Exogeneity**: Uncorrelated with $u$ (cannot be tested - must argue)
**IV estimator:**
$$\hat{\beta}_{IV} = \frac{Cov(z,y)}{Cov(z,x)}$$
**Causal inference methods:**
1. Randomized experiments (RCT)
2. Instrumental variables (IV)
3. Difference-in-differences (DID)
4. Regression discontinuity (RD)
5. Fixed effects (control for unobserved heterogeneity)
6. Matching and propensity scores
**Key insight:** Need credible identification strategy, not just controls!
```{python}
# 17.7 Causality And Instrumental Variables
print("Key Points on Causality:")
print("1. Correlation ≠ Causation")
print(" - Regression shows association, not necessarily causation")
print(" - Need to rule out confounding, reverse causation, selection")
print("2. Causal methods: RCT, IV, Fixed Effects, DiD, RD, Matching")
print("3. Credible causal inference requires a convincing identification strategy")
```
**The Potential Outcomes Framework:**
- $Y_{1i}$: Outcome if treated; $Y_{0i}$: Outcome if not treated
- Individual treatment effect: $Y_{1i} - Y_{0i}$ (only one is observed!)
- **ATE** = $E[Y_{1i} - Y_{0i}]$: Average Treatment Effect
**The Causal Inference Toolkit:**
- **Randomized Controlled Trials (RCT)**: Gold standard -- random assignment ensures treatment is uncorrelated with potential outcomes
- **Instrumental Variables**: Use an instrument $z$ that affects $x$ but not $y$ directly
- **Fixed Effects**: Control for time-invariant unobservables (e.g., NBA team characteristics)
- **Difference-in-Differences**: Compare treatment vs. control groups before and after an intervention
- **Regression Discontinuity**: Exploit a threshold rule for treatment assignment
**Practical Recommendations:**
- Always think about potential confounders
- Use robust/cluster standard errors
- Test multiple specifications and report both OLS and IV/FE
- Be transparent about identification assumptions -- causal claims require strong justification
> **Key Concept 17.8: Instrumental Variables and Causal Inference**
>
> Endogeneity (regressors correlated with errors) biases OLS estimates. Sources include omitted variables, measurement error, and simultaneity. Instrumental variables (IV) provide a solution: find a variable $z$ that is correlated with the endogenous regressor (relevance) but uncorrelated with the error (exogeneity). The IV estimator $\hat{\beta}_{IV} = \text{Cov}(z,y)/\text{Cov}(z,x)$ is consistent even when OLS is biased. Complementary causal methods include RCTs, DiD, RD, and matching.
## Key Takeaways
**Panel Data Methods:**
- Panel data combines cross-sectional and time series dimensions, observing multiple individuals over multiple periods
- Variance decomposition separates total variation into within (over time) and between (across individuals) components
- Pooled OLS ignores panel structure; always use cluster-robust standard errors clustered by individual
- Fixed effects controls for time-invariant unobserved heterogeneity by using only within-individual variation
- Random effects is more efficient than FE but assumes individual effects are uncorrelated with regressors
- FE is preferred when individual effects are likely correlated with regressors (use Hausman test to decide)
**Nonlinear Models:**
- Logit models estimate the probability of binary outcomes using the logistic function
- Marginal effects ($\hat{p}(1-\hat{p})\beta_j$) give the change in probability from a one-unit change in $x_j$
- Logit marginal effects and linear probability model coefficients are typically similar in magnitude
**Time Series Analysis:**
- Time series data exhibit autocorrelation, where observations are correlated with their past values
- Non-stationary series (trending) can produce spurious regressions with misleadingly high $R^2$
- First differencing removes trends and reduces autocorrelation, transforming non-stationary series to stationary
- HAC (Newey-West) standard errors account for both heteroskedasticity and autocorrelation in time series
- Default SEs can be dramatically too small with autocorrelation (3-8x understatement is common)
**Dynamic Models:**
- Autoregressive (AR) models capture persistence by including lagged dependent variables
- Autoregressive distributed lag (ADL) models include lags of both the dependent and independent variables
- The correlogram (ACF plot) helps determine the appropriate number of lags
- Total multiplier from an ADL model gives the long-run effect of a permanent change in $x$
**Causality and Instrumental Variables:**
- Correlation does not imply causation; endogeneity (omitted variables, reverse causation, measurement error) biases OLS
- Instrumental variables require relevance ($\text{Corr}(z,x) \neq 0$) and exogeneity ($\text{Corr}(z,u) = 0$)
- Fixed effects, difference-in-differences, regression discontinuity, and matching are complementary causal methods
- Credible causal inference requires a convincing identification strategy, not just adding control variables
**Python tools:** `pyfixest` (OLS, FE, IV, cluster/HAC SEs), `statsmodels` (logit, ACF), `matplotlib`/`seaborn` (visualization)
**Python Libraries and Code:**
This single code block reproduces the core workflow of Chapter 17. It is self-contained — copy it into an empty notebook and run it to review the complete pipeline from panel data estimation to time series diagnostics and dynamic modeling.
```python
# =============================================================================
# CHAPTER 17 CHEAT SHEET: Panel Data, Time Series Data, Causation
# =============================================================================
# --- Libraries ---
import pandas as pd # data loading and manipulation
import numpy as np # numerical operations
import matplotlib.pyplot as plt # creating plots and visualizations
import pyfixest as pf # fast OLS/FE/IV estimation
# !pip install pyfixest
from statsmodels.tsa.stattools import acf # autocorrelation function
# =============================================================================
# STEP 1: Load panel data (NBA teams across seasons)
# =============================================================================
# Panel data: multiple individuals (teams) observed over multiple time periods
url_nba = "https://raw.githubusercontent.com/quarcs-lab/data-open/master/AED/AED_NBA.DTA"
data_nba = pd.read_stata(url_nba)
print(f"Panel: {data_nba['teamid'].nunique()} teams × {data_nba['season'].nunique()} seasons = {len(data_nba)} obs")
# =============================================================================
# STEP 2: Variance decomposition — between vs within variation
# =============================================================================
# Understanding which variation your estimator uses is the first step in panel analysis
overall_sd = data_nba['lnrevenue'].std()
between_sd = data_nba.groupby('teamid')['lnrevenue'].mean().std()
within_sd = data_nba.groupby('teamid')['lnrevenue'].apply(lambda x: x - x.mean()).std()
print(f"\nVariance Decomposition of Log Revenue:")
print(f" Overall SD: {overall_sd:.4f}")
print(f" Between SD: {between_sd:.4f} (across teams)")
print(f" Within SD: {within_sd:.4f} (over time)")
print(f" Between > Within → team characteristics dominate year-to-year swings")
# =============================================================================
# STEP 3: Pooled OLS with cluster-robust SEs
# =============================================================================
# Observations within the same team are correlated over time — default SEs
# dramatically understate uncertainty. Always cluster by individual in panel data.
fit_pool = pf.feols('lnrevenue ~ wins', data=data_nba)
fit_cluster = pf.feols('lnrevenue ~ wins', data=data_nba, vcov={'CRV1': 'teamid'})
print(f"\nPooled OLS — wins coefficient: {fit_pool.coef()['wins']:.6f}")
print(f" Default SE: {fit_pool.se()['wins']:.6f}")
print(f" Cluster SE: {fit_cluster.se()['wins']:.6f}")
print(f" Ratio: {fit_cluster.se()['wins'] / fit_pool.se()['wins']:.2f}x larger")
# =============================================================================
# STEP 4: Fixed effects — control for unobserved team characteristics
# =============================================================================
# FE uses only within-team variation (de-meaning), eliminating bias from
# persistent traits like market size, brand value, and arena quality.
fit_fe = pf.feols('lnrevenue ~ wins | teamid', data=data_nba, vcov={'CRV1': 'teamid'})
print(f"\nFixed Effects — wins coefficient: {fit_fe.coef()['wins']:.6f}")
print(f" Cluster SE: {fit_fe.se()['wins']:.6f}")
print(f" R² (within): {fit_fe._r2_within:.4f}")
print(f"\nComparison:")
print(f" Pooled OLS coef: {fit_pool.coef()['wins']:.6f}")
print(f" Fixed Effects: {fit_fe.coef()['wins']:.6f}")
print(f" FE is smaller → pooled OLS had positive omitted variable bias")
# =============================================================================
# STEP 5: Time series — levels vs first differences
# =============================================================================
# Non-stationary (trending) series produce spurious regressions with misleading R².
# First differencing removes trends and restores valid inference.
url_rates = "https://raw.githubusercontent.com/quarcs-lab/data-open/master/AED/AED_INTERESTRATES.DTA"
data_rates = pd.read_stata(url_rates)
# Regression in levels (potentially spurious)
fit_levels = pf.feols('gs10 ~ gs1', data=data_rates)
# Regression in first differences (removes trends)
fit_changes = pf.feols('dgs10 ~ dgs1', data=data_rates)
print(f"\nLevels regression: gs1 coef = {fit_levels.coef()['gs1']:.4f}, R² = {fit_levels._r2:.4f}")
print(f"Changes regression: dgs1 coef = {fit_changes.coef()['dgs1']:.4f}, R² = {fit_changes._r2:.4f}")
print(f"R² drops after differencing — lower but honest (no spurious trend inflation)")
# =============================================================================
# STEP 6: Autocorrelation diagnostics — the smoking gun
# =============================================================================
# Slowly decaying ACF in residuals signals non-stationarity and invalid SEs.
# After differencing, autocorrelation should drop dramatically.
acf_levels = acf(pd.Series(fit_levels._u_hat).dropna(), nlags=5)
acf_changes = acf(pd.Series(fit_changes._u_hat).dropna(), nlags=5)
print(f"\nResidual autocorrelation (lag 1):")
print(f" Levels regression: {acf_levels[1]:.4f} (high → non-stationary residuals)")
print(f" Changes regression: {acf_changes[1]:.4f} (much lower → differencing worked)")
# HAC (Newey-West) SEs correct for autocorrelation without differencing
fit_hac = pf.feols('gs10 ~ gs1', data=data_rates,
vcov='NW', vcov_kwargs={'time_id': 'time', 'lag': 24})
print(f"\nDefault SE on gs1: {fit_levels.se()['gs1']:.4f}")
print(f"HAC SE on gs1: {fit_hac.se()['gs1']:.4f}")
print(f"HAC is {fit_hac.se()['gs1'] / fit_levels.se()['gs1']:.1f}x larger — default SEs are too small")
# =============================================================================
# STEP 7: ADL model — dynamic multipliers
# =============================================================================
# Autoregressive distributed lag models capture how effects build over time.
# Lagged dependent and independent variables model persistence and transmission.
data_rates['dgs10_lag1'] = data_rates['dgs10'].shift(1)
data_rates['dgs10_lag2'] = data_rates['dgs10'].shift(2)
data_rates['dgs1_lag1'] = data_rates['dgs1'].shift(1)
data_rates['dgs1_lag2'] = data_rates['dgs1'].shift(2)
fit_adl = pf.feols('dgs10 ~ dgs10_lag1 + dgs10_lag2 + dgs1 + dgs1_lag1 + dgs1_lag2',
data=data_rates)
print(f"\nADL(2,2) Model:")
print(f" Impact multiplier (dgs1): {fit_adl.coef()['dgs1']:.4f}")
print(f" 1-month cumulative: {fit_adl.coef()['dgs1'] + fit_adl.coef()['dgs1_lag1']:.4f}")
print(f" 2-month cumulative: {fit_adl.coef()['dgs1'] + fit_adl.coef()['dgs1_lag1'] + fit_adl.coef()['dgs1_lag2']:.4f}")
print(f" R²: {fit_adl._r2:.4f} (much higher than static model)")
# Check residual autocorrelation — should be near zero if well-specified
acf_adl = acf(pd.Series(fit_adl._u_hat).dropna(), nlags=5)
print(f" Residual ACF(1): {acf_adl[1]:.4f} (near zero → dynamics captured)")
```
**Try it yourself!** Copy this code into an empty Google Colab notebook and run it: [Open Colab](https://colab.research.google.com/notebooks/empty.ipynb)
**Next Steps:**
- **Advanced panel methods**: Dynamic panel estimators (Arellano-Bond) and correlated random effects
- **Time series econometrics**: Cointegration, error-correction models, and unit-root testing
- **Modern causal inference**: Difference-in-differences, regression discontinuity, and credible IV designs
- **Apply the toolkit**: Bring these methods to your own research questions and observational datasets
---
Congratulations! You've completed Chapter 17, the final chapter covering panel data, time series, and causal inference. You now have a comprehensive toolkit of econometric methods for analyzing real-world data.
> **Common Mistakes to Avoid**
>
> - **Using pooled OLS when fixed effects are needed**: Ignoring unobserved heterogeneity biases coefficients
> - **Confusing within and between variation**: Fixed effects only use within-entity variation
> - **Claiming causation from observational data without addressing endogeneity**
## Practice Exercises
**Exercise 1: Panel Data Variance Decomposition**
A panel dataset of 50 firms over 5 years shows:
- Overall standard deviation of log revenue: 0.80
- Between standard deviation: 0.70
- Within standard deviation: 0.30
(a) Which source of variation dominates? What does this imply about the importance of firm-specific characteristics?
(b) If you run fixed effects, what proportion of the total variation are you using for estimation?
(c) Would you expect the FE coefficient to be larger or smaller than pooled OLS? Explain using the omitted variables bias formula.
**Exercise 2: Cluster-Robust Standard Errors**
You estimate a panel regression of test scores on class size using data from 100 schools over 3 years (300 observations). The coefficient on class size has:
- Default SE: 0.15 (t = 3.33)
- Cluster-robust SE (by school): 0.45 (t = 1.11)
(a) Why is the cluster SE three times larger than the default SE?
(b) Does your conclusion about the significance of class size change? At what significance level?
(c) What is the effective number of independent observations in this panel?
**Exercise 3: Fixed Effects vs. Random Effects**
You estimate a wage equation using panel data on 500 workers over 10 years. The Hausman test yields $\chi^2 = 25.4$ with 3 degrees of freedom ($p < 0.001$).
(a) State the null and alternative hypotheses of the Hausman test.
(b) What do you conclude? Which estimator should you use?
(c) Give an economic reason why the RE assumption might fail in a wage equation (hint: think about unobserved ability).
**Exercise 4: Time Series Autocorrelation**
A regression of the 10-year interest rate on the 1-year rate using monthly data yields residuals with:
- Lag 1 autocorrelation: 0.95
- Lag 5 autocorrelation: 0.71
- Default SE on the 1-year rate coefficient: 0.022
- HAC SE (24 lags): 0.080
(a) Is there evidence of autocorrelation? What does the slowly decaying ACF pattern suggest about the data?
(b) By what factor do the HAC SEs differ from default SEs? What are the implications for hypothesis testing?
(c) Would first differencing help? What would you expect the lag 1 autocorrelation of the differenced residuals to be?
**Exercise 5: Spurious Regression**
You regress GDP on the number of mobile phone subscriptions over 30 years and find $R^2 = 0.97$ with a highly significant coefficient.
(a) Why might this be a spurious regression? What is the key characteristic of both series?
(b) Describe two methods to address this problem.
(c) If you first-difference both series, what economic relationship (if any) would the regression estimate?
**Exercise 6: Identifying Causal Effects**
For each scenario, identify the main threat to causal inference and suggest an appropriate method:
(a) Estimating the effect of police spending on crime rates across cities (cross-sectional data).
(b) Estimating the effect of a minimum wage increase on employment (state-level panel data with staggered adoption).
(c) Estimating the effect of class size on student achievement (students assigned to classes based on a cutoff rule).
## Case Studies
### Case Study 1: Panel Data Analysis of Cross-Country Productivity
In this case study, you will apply panel data methods from this chapter to analyze labor productivity dynamics across countries using the Mendez convergence clubs dataset.
**Dataset:** Mendez (2020) convergence clubs data
- **Source:** `https://raw.githubusercontent.com/quarcs-lab/mendez2020-convergence-clubs-code-data/master/assets/dat.csv`
- **Sample:** 108 countries, 1990-2014 (panel structure: country $\times$ year)
- **Variables:** `lp` (labor productivity), `rk` (physical capital), `hc` (human capital), `rgdppc` (real GDP per capita), `tfp` (total factor productivity), `region`, `country`
**Research question:** How do physical and human capital affect labor productivity across countries, and does controlling for unobserved country characteristics change the estimates?
---
#### Task 1: Panel Data Structure (Guided)
Load the dataset and explore its panel structure. Calculate the within and between variation for log labor productivity.
```python
import pandas as pd
import numpy as np
url = "https://raw.githubusercontent.com/quarcs-lab/mendez2020-convergence-clubs-code-data/master/assets/dat.csv"
dat = pd.read_csv(url)
dat['ln_lp'] = np.log(dat['lp'])
dat['ln_rk'] = np.log(dat['rk'])
# Panel structure
print(f"Countries: {dat['country'].nunique()}")
print(f"Years: {dat['year'].nunique()}")
print(f"Total observations: {len(dat)}")
# Variance decomposition
overall_var = dat['ln_lp'].var()
between_var = dat.groupby('country')['ln_lp'].mean().var()
within_var = dat.groupby('country')['ln_lp'].apply(lambda x: x - x.mean()).var()
print(f"Overall variance: {overall_var:.4f}")
print(f"Between variance: {between_var:.4f}")
print(f"Within variance: {within_var:.4f}")
```
Which source of variation dominates? What does this imply for the choice between pooled OLS and fixed effects?
---
#### Task 2: Pooled OLS with Cluster-Robust SEs (Guided)
Estimate a pooled OLS regression of log productivity on log physical capital and human capital. Compare default and cluster-robust standard errors (clustered by country).
```python
import pyfixest as pf
fit_default = pf.feols('ln_lp ~ ln_rk + hc', data=dat)
fit_cluster = pf.feols('ln_lp ~ ln_rk + hc', data=dat, vcov={'CRV1': 'country'})
print("Default SE:", fit_default.se().round(4).to_dict())
print("Cluster SE:", fit_cluster.se().round(4).to_dict())
print("Ratio:", (fit_cluster.se() / fit_default.se()).round(2).to_dict())
```
How much larger are cluster SEs? What does this tell you about within-country correlation?
---
#### Task 3: Fixed Effects Estimation (Semi-guided)
Estimate a fixed effects model controlling for country-specific characteristics. Compare the FE coefficients with the pooled OLS coefficients.
*Hint:* Use `pf.feols('ln_lp ~ ln_rk + hc | country', data=dat)` for fixed effects, or use the within transformation manually by de-meaning the variables by country.
Which coefficients change most? What unobserved country characteristics might be driving the difference?
---
#### Task 4: Time Trends in Productivity (Semi-guided)
Add a time trend or year fixed effects to the panel model. Test whether productivity growth rates differ across regions.
*Hint:* Use `pf.feols('ln_lp ~ ln_rk + hc | country + year', data=dat)` for two-way fixed effects, or create region-year interaction terms.
Is there evidence of convergence (faster growth in initially poorer countries)?
---
#### Task 5: Regional Heterogeneity with Interactions (Independent)
Estimate models that allow the returns to physical and human capital to vary by region:
1. Add region dummy variables
2. Add region-capital interaction terms
3. Test the joint significance of regional interactions
Do returns to capital differ significantly across regions? Which regions show the highest returns to human capital?
---
#### Task 6: Policy Brief on Capital and Productivity (Independent)
Write a 200-300 word policy brief addressing: What are the most effective channels for increasing labor productivity across countries? Your brief should:
1. Compare pooled OLS and fixed effects estimates of capital returns
2. Discuss whether the relationship is causal (what are the threats to identification?)
3. Evaluate whether returns to capital differ by region
4. Recommend policies based on the relative importance of physical vs. human capital
> **Key Concept 17.9: Panel Data for Cross-Country Analysis**
>
> Cross-country panel data enables controlling for time-invariant country characteristics (institutions, geography, culture) that confound cross-sectional estimates. Fixed effects absorb these permanent differences, identifying the relationship between capital accumulation and productivity growth from within-country variation over time. The typical finding is that FE coefficients are smaller than pooled OLS, indicating positive omitted variable bias in cross-sectional estimates.
> **Key Concept 17.10: Choosing Between Panel Data Estimators**
>
> The choice between pooled OLS, fixed effects, and random effects depends on the research question and data structure. Use pooled OLS with cluster SEs for descriptive associations; use FE when unobserved individual heterogeneity is likely correlated with regressors (the common case); use RE only when individual effects are plausibly random and uncorrelated with regressors (e.g., randomized experiments). The Hausman test helps decide between FE and RE, but economic reasoning should guide the choice.
**What You've Learned:**
In this case study, you applied the complete panel data toolkit to cross-country productivity analysis. You decomposed variation into within and between components, compared pooled OLS with fixed effects, examined cluster-robust standard errors, and explored regional heterogeneity. These methods are essential for any empirical analysis using panel data.
### Case Study 2: Luminosity and Development Over Time: A Panel Approach
**Research Question**: How does nighttime luminosity evolve across Bolivia's municipalities over time, and what does within-municipality variation reveal about development dynamics?
**Background**: Throughout this textbook, we have analyzed *cross-sectional* satellite-development relationships. But the DS4Bolivia dataset includes nighttime lights data for 2012-2020, creating a natural **panel dataset**. In this case study, we apply Chapter 17's panel data tools to track how luminosity evolves across municipalities over time, using fixed effects to control for time-invariant characteristics.
**The Data**: The DS4Bolivia dataset covers 339 Bolivian municipalities with annual nighttime lights and population data for 2012-2020, yielding a potential panel of 3,051 municipality-year observations.
**Key Variables**:
- `mun`: Municipality name
- `dep`: Department (administrative region)
- `asdf_id`: Unique municipality identifier
- `ln_NTLpc2012` through `ln_NTLpc2020`: Log nighttime lights per capita (annual)
- `pop2012` through `pop2020`: Population (annual)
#### Load the DS4Bolivia Data and Create Panel Structure
```{python}
# Load the DS4Bolivia dataset
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pyfixest as pf
url_bol = "https://raw.githubusercontent.com/quarcs-lab/ds4bolivia/master/ds4bolivia_v20250523.csv"
bol = pd.read_csv(url_bol)
# Display available NTL and population variables
ntl_vars = [c for c in bol.columns if c.startswith('ln_NTLpc')]
pop_vars = [c for c in bol.columns if c.startswith('pop') and c[3:].isdigit()]
# Ds4Bolivia: Panel Data Case Study
print(f"Cross-sectional units: {len(bol)} municipalities")
print(f"\nNTL variables available: {ntl_vars}")
print(f"Population variables available: {pop_vars}")
```
#### Task 1: Create Panel Dataset (Guided)
**Objective**: Reshape the wide-format DS4Bolivia data into a long panel dataset.
**Instructions**:
1. Select municipality identifiers (`mun`, `dep`, `asdf_id`) and annual NTL/population variables
2. Reshape from wide to long format using `pd.melt()` or manual reshaping
3. Create columns: `municipality`, `year`, `ln_NTLpc`, `pop`, `ln_pop`
4. Verify the panel structure: 339 municipalities x 9 years = 3,051 observations
5. Show `head()` and `describe()` for the panel dataset
```{python}
# Your code here: Reshape to panel format
#
# Example structure:
# # Reshape NTL variables
# ntl_cols = {f'ln_NTLpc{y}': y for y in range(2012, 2021)}
# pop_cols = {f'pop{y}': y for y in range(2012, 2021)}
#
# # Melt NTL
# ntl_long = bol[['mun', 'dep', 'asdf_id'] + list(ntl_cols.keys())].melt(
# id_vars=['mun', 'dep', 'asdf_id'],
# var_name='ntl_var', value_name='ln_NTLpc'
# )
# ntl_long['year'] = ntl_long['ntl_var'].str.extract(r'(\d{4})').astype(int)
#
# # Melt Population
# pop_long = bol[['asdf_id'] + list(pop_cols.keys())].melt(
# id_vars=['asdf_id'],
# var_name='pop_var', value_name='pop'
# )
# pop_long['year'] = pop_long['pop_var'].str.extract(r'(\d{4})').astype(int)
#
# # Merge
# panel = ntl_long.merge(pop_long[['asdf_id', 'year', 'pop']],
# on=['asdf_id', 'year'], how='left')
# panel['ln_pop'] = np.log(panel['pop'])
# panel = panel.sort_values(['asdf_id', 'year']).reset_index(drop=True)
#
# print(f"Panel shape: {panel.shape}")
# print(f"Municipalities: {panel['asdf_id'].nunique()}")
# print(f"Years: {sorted(panel['year'].unique())}")
# print(panel.head(18)) # Show 2 municipalities
# print(panel[['ln_NTLpc', 'ln_pop', 'pop']].describe().round(3))
```
> **Key Concept 17.11: Satellite Panel Data**
>
> Annual nighttime lights observations create **panel datasets** even where traditional economic surveys are unavailable or infrequent. For Bolivia's 339 municipalities over 2012-2020, the NTL panel provides 3,051 municipality-year observations. This temporal dimension allows us to move beyond cross-sectional associations and study *changes within municipalities over time*—a crucial step toward understanding development dynamics rather than just static patterns.
#### Task 2: Pooled OLS with Cluster-Robust SEs (Guided)
**Objective**: Estimate a pooled OLS regression of NTL on population with cluster-robust standard errors.
**Instructions**:
1. Estimate `ln_NTLpc ~ ln_pop + year` using all panel observations
2. Use cluster-robust standard errors clustered by municipality
3. Compare default and cluster-robust SEs
4. Interpret: How does population relate to NTL? Is there a significant time trend?
```{python}
# Your code here: Pooled OLS with cluster-robust SEs
#
# Example structure:
# panel_reg = panel[['ln_NTLpc', 'ln_pop', 'year', 'mun', 'asdf_id']].dropna()
#
# fit_pooled = pf.feols('ln_NTLpc ~ ln_pop + year', data=panel_reg, vcov={'CRV1': 'asdf_id'})
# print("POOLED OLS WITH CLUSTER-ROBUST SEs")
# print(fit_pooled.summary())
```
#### Task 3: Fixed Effects (Semi-guided)
**Objective**: Estimate a fixed effects model controlling for time-invariant municipality characteristics.
**Instructions**:
1. Add municipality fixed effects using `C(asdf_id)` or entity demeaning
2. Compare FE coefficients with pooled OLS coefficients
3. How does controlling for time-invariant municipality characteristics change the population-NTL relationship?
4. Discuss: What unobserved factors do municipality fixed effects absorb (altitude, remoteness, climate)?
**Hint**: You can use `C(asdf_id)` in the formula, or manually demean variables by subtracting municipality means. For large datasets, demeaning is more computationally efficient.
```{python}
# Your code here: Fixed effects estimation
#
# Example structure (demeaning approach):
# # Demean variables within each municipality
# for col in ['ln_NTLpc', 'ln_pop']:
# panel_reg[f'{col}_dm'] = panel_reg.groupby('asdf_id')[col].transform(
# lambda x: x - x.mean()
# )
# panel_reg['year_dm'] = panel_reg['year'] - panel_reg.groupby('asdf_id')['year'].transform('mean')
#
# fit_fe = pf.feols('ln_NTLpc ~ ln_pop + year | asdf_id', data=panel_reg, vcov={'CRV1': 'asdf_id'})
# print("FIXED EFFECTS (WITHIN ESTIMATOR)")
# print(fit_fe.summary())
#
# print("\nCOMPARISON:")
# print(f" Pooled OLS ln_pop coef: {fit_pooled.coef()['ln_pop']:.4f}")
# print(f" Fixed Effects ln_pop coef: {fit_fe.coef()['ln_pop']:.4f}")
```
> **Key Concept 17.12: Fixed Effects for Spatial Heterogeneity**
>
> Municipality fixed effects absorb all **time-invariant characteristics**: altitude, remoteness, climate, historical infrastructure, cultural factors. After removing these fixed differences, the remaining variation identifies how *changes* in population (or other time-varying factors) relate to *changes* in NTL within the same municipality. This within-municipality analysis is more credible for causal interpretation than cross-sectional regressions, because it eliminates bias from unobserved time-invariant confounders.
#### Task 4: Time Trends (Semi-guided)
**Objective**: Examine how nighttime lights evolve over time using year fixed effects.
**Instructions**:
1. Replace the linear time trend with year dummy variables: `C(year)`
2. Test whether the year effects are jointly significant
3. Plot the estimated year coefficients to visualize the NTL trajectory
4. Discuss: Did NTL grow steadily, or were there jumps or declines?
**Hint**: Use one year as the reference category. The year coefficients show NTL changes relative to the base year.
```{python}
# Your code here: Year fixed effects
#
# Example structure:
# # Estimate with year dummies (demeaned for municipality FE)
# panel_reg['year_cat'] = panel_reg['year'].astype(str)
#
# # Simple approach: use year means of demeaned NTL
# year_means = panel_reg.groupby('year')['ln_NTLpc'].mean()
# year_means_dm = year_means - year_means.iloc[0] # relative to base year
#
# fig, ax = plt.subplots(figsize=(10, 6))
# ax.plot(year_means.index, year_means.values, 'o-', color='navy', linewidth=2)
# ax.set_xlabel('Year')
# ax.set_ylabel('Mean Log NTL per Capita')
# ax.set_title('Average Municipal NTL Over Time (2012-2020)')
# ax.grid(True, alpha=0.3)
# plt.tight_layout()
# plt.show()
```
#### Task 5: First Differences (Independent)
**Objective**: Estimate the relationship using first differences as an alternative to fixed effects.
**Instructions**:
1. Compute first differences: $\Delta ln\_NTLpc = ln\_NTLpc_t - ln\_NTLpc_{t-1}$ and $\Delta ln\_pop = ln\_pop_t - ln\_pop_{t-1}$
2. Estimate $\Delta ln\_NTLpc \sim \Delta ln\_pop$
3. Compare the first-difference coefficient with the fixed effects estimate
4. Discuss: When do FE and FD give different results? What assumptions does each require?
```{python}
# Your code here: First differences estimation
#
# Example structure:
# panel_reg = panel_reg.sort_values(['asdf_id', 'year'])
# panel_reg['d_ln_NTLpc'] = panel_reg.groupby('asdf_id')['ln_NTLpc'].diff()
# panel_reg['d_ln_pop'] = panel_reg.groupby('asdf_id')['ln_pop'].diff()
#
# # Drop first year (no difference available)
# fd_data = panel_reg.dropna(subset=['d_ln_NTLpc', 'd_ln_pop'])
#
# fit_fd = pf.feols('d_ln_NTLpc ~ d_ln_pop', data=fd_data, vcov={'CRV1': 'asdf_id'})
# print("FIRST DIFFERENCES ESTIMATION")
# print(fit_fd.summary())
#
# print(f"\nFD coefficient on ln_pop: {fit_fd.coef()['d_ln_pop']:.4f}")
```
#### Task 6: Panel Brief (Independent)
**Objective**: Write a 200-300 word brief summarizing your panel data analysis.
**Your brief should address**:
1. What do within-municipality changes in NTL reveal about development dynamics?
2. How does the FE population coefficient differ from the cross-sectional (pooled OLS) one?
3. What time trends in NTL are visible across 2012-2020?
4. How do FE and FD estimates compare? Which assumptions matter most?
5. What are the advantages and limitations of satellite panel data for tracking municipal development over time?
6. What additional time-varying variables would improve the analysis?
```{python}
# Your code here: Additional analysis for the panel brief
#
# You might want to:
# 1. Decompose variance into between and within components
# 2. Plot NTL trajectories for selected municipalities
# 3. Compare growth rates across departments
# 4. Create a summary table of all estimation results
#
# Example: Variance decomposition
# overall_var = panel_reg['ln_NTLpc'].var()
# between_var = panel_reg.groupby('asdf_id')['ln_NTLpc'].mean().var()
# within_var = panel_reg.groupby('asdf_id')['ln_NTLpc'].apply(lambda x: x - x.mean()).var()
# print(f"Overall variance: {overall_var:.4f}")
# print(f"Between variance: {between_var:.4f}")
# print(f"Within variance: {within_var:.4f}")
# print(f"Between share: {between_var/overall_var:.1%}")
```
#### What You've Learned from This Case Study
This is the final DS4Bolivia case study in the textbook. Across 12 chapters, you have applied the complete econometric toolkit—from simple descriptive statistics (Chapter 1) through panel data methods (Chapter 17)—to study how satellite data can predict and monitor local economic development. The DS4Bolivia project demonstrates that modern data science and econometrics, combined with freely available satellite imagery, can contribute to SDG monitoring even in data-scarce contexts.
In this panel data analysis, you've applied Chapter 17's complete toolkit:
- **Panel construction**: Reshaped cross-sectional data into a municipality-year panel
- **Pooled OLS**: Estimated baseline relationships with cluster-robust standard errors
- **Fixed effects**: Controlled for time-invariant municipality characteristics
- **Time trends**: Examined the trajectory of nighttime lights across 2012-2020
- **First differences**: Used an alternative estimation strategy and compared with FE
- **Critical thinking**: Assessed what within-municipality variation reveals about development dynamics
**Congratulations!** You have now completed the full DS4Bolivia case study arc across the textbook.
---