---
title: 9. Models with Natural Logarithms
execute:
enabled: true
warning: false
---
**metricsAI: An Introduction to Econometrics with Python and AI in the Cloud**
*[Carlos Mendez](https://carlos-mendez.org)*
<img src="https://raw.githubusercontent.com/quarcs-lab/metricsai/main/images/ch09_visual_summary.jpg" alt="Chapter 09 Visual Summary" width="100%">
This notebook teaches you how to use natural logarithms in regression analysis to measure elasticities, semi-elasticities, and percentage changes—essential tools for empirical economics.
[](https://colab.research.google.com/github/quarcs-lab/metricsai/blob/main/notebooks_colab/ch09_Models_with_Natural_Logarithms.ipynb)
<div class="chapter-resources">
<a href="https://www.youtube.com/watch?v=rPy6m8_Wg4c" target="_blank" class="resource-btn">🎬 AI Video</a>
<a href="https://carlos-mendez.my.canva.site/s09-models-with-natural-logarithms-pdf" target="_blank" class="resource-btn">✨ AI Slides</a>
<a href="https://cameron.econ.ucdavis.edu/aed/traedv1_09" target="_blank" class="resource-btn">📊 Cameron Slides</a>
<a href="https://app.edcafe.ai/quizzes/697867a22f5d08069e04a411" target="_blank" class="resource-btn">✏️ Quiz</a>
<a href="https://app.edcafe.ai/chatbots/6978a07f2f5d08069e0713c6" target="_blank" class="resource-btn">🤖 AI Tutor</a>
</div>
## Chapter Overview
**Why logarithms in economics?**
Economists care about **proportionate changes** more than absolute changes:
- A \$10,000 salary increase means different things at \$30,000 vs \$300,000 income
- A \$1 price change matters differently for a \$2 item vs a \$100 item
- Economic theory often predicts **percentage** responses (e.g., price elasticity of demand)
**Natural logarithms** let us work with proportionate changes easily in regression models.
**What you'll learn:**
- Understand the natural logarithm function and its basic properties
- Use logarithmic transformations to approximate proportionate and percentage changes
- Distinguish between semi-elasticity and elasticity
- Interpret coefficients in log-linear, log-log, and linear-log regression models
- Apply logarithmic models to analyze the relationship between earnings and education
- Linearize exponential growth patterns using natural logarithms
- Apply the Rule of 72 to calculate doubling times for compound growth
- Choose the appropriate model specification for different economic questions
**Datasets used:**
- **AED_EARNINGS.DTA**: Annual earnings and education for 171 full-time workers aged 30 (2010)
- **AED_SP500INDEX.DTA**: S&P 500 stock market index, annual data 1927-2019 (93 years)
**Chapter outline:**
- 9.1 Natural Logarithm Function
- 9.2 Semi-Elasticities and Elasticities
- 9.3 Example: Earnings and Education
- 9.4 Further Uses: Exponential Growth
- Key Takeaways
- Practice Exercises
- Case Studies
## Key Concepts
Five core ideas anchor this chapter. Skim them before you start, and come back when a term feels fuzzy. Each entry pairs a concrete example using the chapter's data with a non-technical analogy. Click a panel to expand it.
**Natural Logarithm ($\ln$):** The inverse of the exponential function $e^x$, satisfying $\ln(ab) = \ln(a) + \ln(b)$ and $\ln(a^k) = k \ln(a)$. Two properties make it the workhorse of econometrics: small log-differences approximate proportionate changes ($\Delta \ln(x) \approx \Delta x / x$), and exponential time paths become straight lines after a log transformation.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
For the 171 women in `data_earnings`, transforming `earnings` to `lnearn` lets the chapter regress $\ln(\text{earnings})$ on `education`. The slope of $0.131$ becomes "13.1% more earnings per extra year of education" — the very same data with a much sharper economic interpretation than dollars per year.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A currency converter takes prices from many countries and reports them in one common unit. The natural log does the same for *change*: it converts multiplicative differences (10× larger) into additive ones ($\ln(10) \approx 2.30$ extra units). Once the data are on a "log scale", percentage moves of any size are directly comparable in the same currency.
:::
::::
:::::
**Linear-Log Model:** A regression of the form $y = \beta_0 + \beta_1 \ln(x) + u$, where $y$ is in its original units but $x$ enters as a logarithm. The slope $\beta_1/100$ is the change in $y$ associated with a 1% increase in $x$, so this model captures *diminishing returns*: each percentage gain in $x$ adds the same dollar amount to $y$.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
The linear-log fit of `earnings` on `lneduc` for the 171 working women gives $\beta_1 \approx 54{,}433$, so $\beta_1/100 \approx 544$: a 1% increase in years of education is associated with about \$544 more in annual earnings. This specification has the lowest $R^2$ of the four functional forms ch09 considers, but is useful when economic theory predicts dollar effects from percentage changes.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A staircase whose risers shrink with every step — the first stair lifts you a foot, the next 9 inches, then 6, then 4. The linear-log model is shaped just like that: in dollars, every 1% of extra schooling lifts earnings by the same amount, but because each 1% requires a *larger* absolute jump in years, the upward dollar gain shrinks per added year.
:::
::::
:::::
**Diminishing Returns:** The economic phenomenon in which each additional unit of an input produces a smaller increment in the outcome. Log transformations capture this directly: $\ln(x)$ rises quickly at small $x$ and slowly at large $x$, so $\beta_1 \ln(x)$ in a linear-log model — or a log-log model with $\beta_1 < 1$ — bends the fitted curve into the classic "diminishing-returns" shape.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
The earnings–education comparison in ch09 shows it concretely: in the linear model, every extra year of `education` is associated with a constant \$5{,}021 — implausible at the high end. The log-log fit, with elasticity $\approx 1.48$, implies the percentage return to an extra year of schooling ($100 \times 1.48/\text{education}$) falls from roughly 12% at 12 years of education to 8% at 18 years, matching the chapter's intuition that "each extra year of school still helps, but a bit less than the previous year."
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
The first slice of cake is sublime; the second is good; by the fifth, you are starting to feel ill. The marginal pleasure of each slice is positive but shrinking — diminishing returns to cake. Logarithmic specifications encode this same idea into a regression: more is still better, but each additional unit contributes a little less than the last.
:::
::::
:::::
**Compound Growth Rate:** The constant rate $r$ at which a series multiplies itself each period: $x_t = x_0 (1+r)^t$. Taking natural logs linearises this into $\ln(x_t) \approx \ln(x_0) + r \cdot t$, so an OLS regression of $\ln(x_t)$ on $t$ recovers $r$ as the slope.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
For the 93 annual observations on the S&P 500 (`data_sp500`, 1927–2019), the regression of `lnsp500` on `year` gives a slope of $0.065$ — i.e. the S&P 500 has compounded at roughly $6.5\%$ per year over the 1927–2019 period. Every year, on average, the index multiplied itself by $1.065$.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A savings account with monthly interest doesn't add the same dollar amount each month — it adds a fixed *percentage* of whatever is currently in the account. So the balance accelerates: \$1{,}000 grows to \$1{,}050, then \$1{,}102, then \$1{,}158. The compound growth rate is the steady percentage gear that quietly drives this acceleration.
:::
::::
:::::
**Right-Skewed Distribution:** A distribution with a long tail of large values — a few extreme observations sit far above the bulk of the data. Earnings, prices, firm sizes, and city populations are textbook examples; modelling them in levels squashes most of the action into a small range, while taking logs spreads the data out evenly and stabilises variance.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
The 171 women in `data_earnings` have a mean of \$41{,}412.69 but a maximum of \$172{,}000 and a minimum of \$1{,}050 — a classic right-skewed picture (skewness $\approx 1.71$ from ch02). After applying the natural log to give `lnearn`, the long upper tail is pulled in, the distribution looks roughly bell-shaped, and OLS on `lnearn` produces tighter, more interpretable inference.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A neighbourhood of houses where most cost \$200k–\$400k but a single waterfront mansion lists at \$15M. On a linear price chart that mansion stretches the axis off the page; on a *log* chart all houses fit comfortably side by side, and one can see relative differences without one outlier dominating the picture.
:::
::::
:::::
## Setup
Run this cell first to import all required packages and configure the environment.
```{python}
#| code-fold: true
#| code-summary: "Setup: Import libraries and configure environment"
# --- Libraries ---
import numpy as np # numerical operations
import pandas as pd # data manipulation
import matplotlib.pyplot as plt # plotting
import seaborn as sns # statistical visualizations
import pyfixest as pf # fast estimation with robust SEs
from scipy import stats # statistical distributions
import random
import os
# --- Reproducibility ---
RANDOM_SEED = 42
random.seed(RANDOM_SEED)
np.random.seed(RANDOM_SEED)
os.environ['PYTHONHASHSEED'] = str(RANDOM_SEED)
# --- Data source ---
GITHUB_DATA_URL = "https://raw.githubusercontent.com/quarcs-lab/data-open/master/AED/"
# --- Output directories ---
IMAGES_DIR = 'images'
TABLES_DIR = 'tables'
os.makedirs(IMAGES_DIR, exist_ok=True)
os.makedirs(TABLES_DIR, exist_ok=True)
# --- Plotting style (dark theme matching book design) ---
plt.style.use('dark_background')
sns.set_style("darkgrid")
plt.rcParams.update({
'axes.facecolor': '#1a2235',
'figure.facecolor': '#12162c',
'grid.color': '#3a4a6b',
'figure.figsize': (10, 6),
'text.color': 'white',
'axes.labelcolor': 'white',
'xtick.color': 'white',
'ytick.color': 'white',
'axes.edgecolor': '#1a2235',
})
print("✓ Setup complete! All packages imported successfully.")
print(f"✓ Random seed set to {RANDOM_SEED} for reproducibility.")
print(f"✓ Data will stream from: {GITHUB_DATA_URL}")
```
## 9.1 Natural Logarithm Function
The **natural logarithm** ln(x) is the logarithm to base **e** ≈ 2.71828...
**Definition:**
$$\ln(x) = \log_e(x), \quad x > 0$$
**Key properties:**
1. ln(1) = 0
2. ln(e) = 1
3. ln(ab) = ln(a) + ln(b) (product rule)
4. ln(a/b) = ln(a) - ln(b) (quotient rule)
5. ln(aᵇ) = b·ln(a) (power rule)
6. exp(ln(x)) = x (inverse function)
**Most important property for economics:**
$$\Delta \ln(x) \approx \frac{\Delta x}{x} \quad \text{(for small changes)}$$
This means: **Change in ln(x) ≈ proportionate change in x**
Multiplying by 100: **100 × Δln(x) ≈ percentage change in x**
**Example:** If x increases from 40 to 40.4:
- Exact proportionate change: (40.4 - 40)/40 = 0.01 (1%)
- Log approximation: ln(40.4) - ln(40) = 0.00995 ≈ 0.01
```{python}
# Demonstrate logarithm properties
# PROPERTIES OF NATURAL LOGARITHM
x_values = np.array([0.5, 1, 2, 5, 10, 20, 100])
ln_values = np.log(x_values)
log_table = pd.DataFrame({
'x': x_values,
'ln(x)': ln_values,
'exp(ln(x))': np.exp(ln_values)
})
print(log_table.to_string(index=False))
# KEY PROPERTIES DEMONSTRATED
print(f"1. ln(1) = {np.log(1):.4f}")
print(f"2. ln(e) = {np.log(np.e):.4f}")
print(f"3. ln(2×5) = ln(2) + ln(5): {np.log(2*5):.4f} = {np.log(2) + np.log(5):.4f} ✓")
print(f"4. ln(10/2) = ln(10) - ln(2): {np.log(10/2):.4f} = {np.log(10) - np.log(2):.4f} ✓")
# APPROXIMATING PROPORTIONATE CHANGES
x0, x1 = 40, 40.4
exact_prop_change = (x1 - x0) / x0
log_approx = np.log(x1) - np.log(x0)
print(f"Change from {x0} to {x1}:")
print(f" Exact proportionate change: {exact_prop_change:.6f} ({exact_prop_change*100:.2f}%)")
print(f" Log approximation Δln(x): {log_approx:.6f} ({log_approx*100:.2f}%)")
print(f" Difference: {abs(exact_prop_change - log_approx):.6f}")
# The approximation is excellent for small changes
```
> **Key Concept 9.1: Logarithmic Approximation of Proportionate Change**
>
> The most important property of the natural logarithm for economics is:
>
> $$\Delta \ln(x) \approx \frac{\Delta x}{x} \quad \text{(proportionate change)}$$
>
> Multiplying by 100 gives the **percentage change**: 100 × Δln(x) ≈ %Δx.
>
> **Why this matters:** This approximation allows us to interpret regression coefficients involving logged variables as **proportionate or percentage changes** — exactly what economists care about when analyzing earnings, prices, GDP, and other economic variables.
>
> **Accuracy:** The approximation is excellent for changes under 10%. For larger changes, use the exact formula: %Δx = 100 × (e^Δln(x) - 1).
## 9.2 Semi-Elasticities and Elasticities
Two key concepts in economics:
### Semi-Elasticity
**Definition:** Proportionate change in y for a **unit change** in x
$$\text{Semi-elasticity}_{yx} = \frac{\Delta y / y}{\Delta x}$$
Multiplied by 100: **percentage change in y when x increases by 1 unit**
**Example:** Semi-elasticity of earnings with respect to education = 0.08
- One more year of schooling → 8% increase in earnings
### Elasticity
**Definition:** Proportionate change in y for a **proportionate change** in x
$$\text{Elasticity}_{yx} = \frac{\Delta y / y}{\Delta x / x}$$
**Example:** Price elasticity of demand = -2
- 1% increase in price → 2% decrease in demand
### Approximations Using Logarithms
Since Δy/y ≈ Δln(y) and Δx/x ≈ Δln(x):
$$\text{Semi-elasticity} \approx \frac{\Delta \ln(y)}{\Delta x}$$
$$\text{Elasticity} \approx \frac{\Delta \ln(y)}{\Delta \ln(x)}$$
**This is why we use logarithms in regression!** The slope coefficient directly estimates the semi-elasticity or elasticity.
**The four model interpretations at a glance:**
1. **Linear:** y = β₀ + β₁x → Δy = β₁Δx
2. **Log-linear:** ln(y) = β₀ + β₁x → %Δy ≈ 100β₁Δx (semi-elasticity)
3. **Log-log:** ln(y) = β₀ + β₁ln(x) → %Δy ≈ β₁%Δx (elasticity)
4. **Linear-log:** y = β₀ + β₁ln(x) → Δy ≈ (β₁/100)%Δx
> **Key Concept 9.2: Semi-Elasticity vs. Elasticity**
>
> These two concepts measure how y responds to changes in x, but in different ways:
>
> - **Semi-elasticity** = (Δy/y) / Δx — proportionate change in y per **unit** change in x
> - **Elasticity** = (Δy/y) / (Δx/x) — proportionate change in y per **proportionate** change in x
>
> **In regression models:**
>
> - Semi-elasticity ≈ Δln(y)/Δx → estimated by the slope in a **log-linear** model
> - Elasticity ≈ Δln(y)/Δln(x) → estimated by the slope in a **log-log** model
>
> **When to use each:**
>
> - **Semi-elasticity:** When x is measured in natural units (years of education, age)
> - **Elasticity:** When both variables are measured in proportions (price and quantity, GDP and investment)
## 9.3 Example: Earnings and Education
**Research Question:** How do earnings vary with years of education?
We'll estimate **four different models** and compare their interpretations:
1. **Linear:** earnings = β₀ + β₁(education)
2. **Log-linear:** ln(earnings) = β₀ + β₁(education)
3. **Log-log:** ln(earnings) = β₀ + β₁ln(education)
4. **Linear-log:** earnings = β₀ + β₁ln(education)
**Dataset:** 171 full-time workers aged 30 in 2010
- earnings: Annual earnings in dollars
- education: Years of completed schooling
Each model answers a slightly different question and has different economic interpretation.
```{python}
# Load and explore the data
data_earnings = pd.read_stata(GITHUB_DATA_URL + 'AED_EARNINGS.DTA')
# DATA SUMMARY: EARNINGS AND EDUCATION
print(data_earnings[['earnings', 'education']].describe())
print("\nFirst 5 observations:")
data_earnings[['earnings', 'education']].head()
```
The summary statistics show a right-skewed earnings distribution: the mean (about \$41,413) sits well above the median (\$36,000), with a maximum of \$172,000. The next cell creates log-transformed versions of both variables — watch how the log scale pulls in that long upper tail.
```{python}
# Create log-transformed variables
data_earnings['lnearn'] = np.log(data_earnings['earnings'])
data_earnings['lneduc'] = np.log(data_earnings['education'])
# VARIABLES (ORIGINAL AND LOG-TRANSFORMED)
table_vars = ['earnings', 'lnearn', 'education', 'lneduc']
data_earnings[table_vars].describe()
```
### Model 1: Linear Model
**Specification:** earnings = β₀ + β₁(education) + ε
**Interpretation:** β₁ = change in earnings (in dollars) for one additional year of education
```{python}
# Model 1: Linear
# MODEL 1: LINEAR - earnings = β₀ + β₁(education)
model_linear = pf.feols('earnings ~ education', data=data_earnings)
# Key results
intercept_1 = model_linear.coef()['Intercept']
slope_1 = model_linear.coef()['education']
r2_1 = model_linear._r2
print(f"Estimated equation: earnings = {intercept_1:,.0f} + {slope_1:,.2f} x education")
print(f"Slope: each additional year of education is associated with ${slope_1:,.2f} higher annual earnings")
print(f"R-squared: {r2_1:.4f} ({r2_1*100:.1f}% of variation explained)")
# Full regression output
model_linear.summary()
```
### Model 2: Log-Linear Model
**Specification:** ln(earnings) = β₀ + β₁(education) + ε
**Interpretation:** β₁ = **semi-elasticity** = proportionate change in earnings for one more year of education
**Practical interpretation:** 100β₁ = **percentage change** in earnings for one more year of education
This is the **most common** specification for earnings equations!
```{python}
# Model 2: Log-linear
# MODEL 2: LOG-LINEAR - ln(earnings) = β₀ + β₁(education)
model_loglin = pf.feols('lnearn ~ education', data=data_earnings)
# Key results
intercept_2 = model_loglin.coef()['Intercept']
semi_elast = model_loglin.coef()['education']
r2_2 = model_loglin._r2
print(f"Estimated equation: ln(earnings) = {intercept_2:.4f} + {semi_elast:.4f} x education")
print(f"Each additional year of education is associated with a {100*semi_elast:.2f}% increase in earnings")
print(f"R-squared: {r2_2:.4f} ({r2_2*100:.1f}% of variation explained)")
print(f"Note: percentage interpretation scales automatically — applies whether you earn $30k or $100k")
# Full regression output
model_loglin.summary()
```
The headline estimate is meaningful in both senses: economically, each additional year of education is associated with about 13.1% higher earnings; statistically, the coefficient's t-statistic of 9.21 (p < 0.001) makes the association highly significant, so it is very unlikely to reflect sampling variation alone.
*Note on standard errors:* Following AED's convention before Chapter 12, the regression output in this chapter reports classical (iid) standard errors; Section 12.2 introduces heteroskedasticity-robust standard errors, which are preferred in practice.
> **Key Concept 9.3: Interpreting Log-Linear Model Coefficients**
>
> In the **log-linear model** ln(y) = β₀ + β₁x, the slope coefficient β₁ is the **semi-elasticity** of y with respect to x:
>
> $$100 \times \beta_1 = \text{percentage change in } y \text{ when } x \text{ increases by 1 unit}$$
>
> This is the most common specification in labor economics because a percentage interpretation **scales automatically** — a 13% return to education applies equally whether you earn \$30,000 or \$100,000.
>
> **Important:** The exact percentage change for large β₁ is 100 × (e^β₁ - 1), not 100 × β₁. The approximation works well when |β₁| < 0.10. Here the estimate β₁ ≈ 0.131 slightly exceeds that threshold: the exact effect is 100 × (e^0.131 - 1) ≈ 14.0%, a bit above the 13.1% approximation.
### Model 3: Log-Log Model
**Specification:** ln(earnings) = β₀ + β₁ln(education) + ε
**Interpretation:** β₁ = **elasticity** = percentage change in earnings for a 1% change in education
**Note:** A "1% increase in education" is a bit artificial (what does 0.14 more years mean?), but this model lets the percentage return to an additional year of education (100β₁/education) decline as education rises.
```{python}
# Model 3: Log-log
# MODEL 3: LOG-LOG - ln(earnings) = β₀ + β₁ln(education)
model_loglog = pf.feols('lnearn ~ lneduc', data=data_earnings)
# Key results
intercept_3 = model_loglog.coef()['Intercept']
elasticity = model_loglog.coef()['lneduc']
r2_3 = model_loglog._r2
print(f"Estimated equation: ln(earnings) = {intercept_3:.4f} + {elasticity:.4f} x ln(education)")
print(f"Elasticity: a 1% increase in education is associated with a {elasticity:.3f}% increase in earnings")
print(f"R-squared: {r2_3:.4f} ({r2_3*100:.1f}% of variation explained)")
# Full regression output
model_loglog.summary()
```
> **Key Concept 9.4: Interpreting Log-Log Model Coefficients**
>
> In the **log-log model** ln(y) = β₀ + β₁ln(x), the slope coefficient β₁ is the **elasticity** of y with respect to x:
>
> $$\beta_1 = \frac{\%\Delta y}{\%\Delta x}$$
>
> A 1% increase in x is associated with a β₁% change in y. Unlike semi-elasticity, elasticity is a **unit-free** measure — it does not depend on the units of measurement.
>
> **Economic interpretation:** If β₁ < 1, there are **diminishing returns** (each additional percent of x yields less than one percent of y). If β₁ > 1, there are **increasing returns**.
### Model 4: Linear-Log Model
**Specification:** earnings = β₀ + β₁ln(education) + ε
**Interpretation:** β₁/100 = dollar change in earnings for a 1% increase in education
This model is less common but captures **diminishing returns** (additional years of education have decreasing marginal effects).
```{python}
# Model 4: Linear-log
# MODEL 4: LINEAR-LOG - earnings = β₀ + β₁ln(education)
model_linlog = pf.feols('earnings ~ lneduc', data=data_earnings)
# Key results
intercept_4 = model_linlog.coef()['Intercept']
slope_4 = model_linlog.coef()['lneduc']
r2_4 = model_linlog._r2
print(f"Estimated equation: earnings = {intercept_4:,.0f} + {slope_4:,.2f} x ln(education)")
print(f"A 1% increase in education is associated with a ${slope_4/100:,.2f} increase in annual earnings")
print(f"R-squared: {r2_4:.4f} ({r2_4*100:.1f}% of variation explained)")
print(f"Note: This model has the lowest R² among the four specifications")
# Full regression output
model_linlog.summary()
```
### Comparison of All Four Models
The table below collects the slope estimate, its economic interpretation, and R² from all four specifications so you can compare them side by side — look for which model fits best and how differently each slope must be read.
```{python}
# Create comparison table
# MODEL COMPARISON SUMMARY
comparison_df = pd.DataFrame({
'Model': ['Linear', 'Log-linear', 'Log-log', 'Linear-log'],
'Specification': ['y ~ x', 'ln(y) ~ x', 'ln(y) ~ ln(x)', 'y ~ ln(x)'],
'Slope Coefficient': [
f"{model_linear.coef().iloc[1]:,.2f}",
f"{model_loglin.coef().iloc[1]:.4f}",
f"{model_loglog.coef().iloc[1]:.4f}",
f"{model_linlog.coef().iloc[1]:,.2f}"
],
'Interpretation': [
f"${model_linear.coef().iloc[1]:,.0f} per year",
f"{100*model_loglin.coef().iloc[1]:.1f}% per year",
f"{model_loglog.coef().iloc[1]:.2f}% per 1% change",
f"${model_linlog.coef().iloc[1]/100:,.0f} per 1% change"
],
'R²': [
f"{model_linear._r2:.3f}",
f"{model_loglin._r2:.3f}",
f"{model_loglog._r2:.3f}",
f"{model_linlog._r2:.3f}"
]
})
print(comparison_df.to_string(index=False))
# WHICH MODEL IS BEST?
# R² is comparable only across models with the same dependent variable
print(f" - Among ln(earnings) models: Log-linear fits best (R² = {model_loglin._r2:.3f} vs. Log-log {model_loglog._r2:.3f})")
print(f" - Among earnings-level models: Linear fits best (R² = {model_linear._r2:.3f} vs. Linear-log {model_linlog._r2:.3f})")
```
> **Key Concept 9.5: Choosing the Right Functional Form**
>
> The choice between linear, log-linear, log-log, and linear-log specifications should be guided by:
>
> 1. **Economic theory** — Does the theory predict absolute or percentage effects?
> 2. **Data properties** — Is the dependent variable right-skewed? Are both variables positive?
> 3. **Model fit** — Which specification yields the highest R²? (Compare R² only across models with the same dependent variable.)
> 4. **Interpretation needs** — Do you need elasticities, semi-elasticities, or dollar amounts?
>
> **In practice:** The **log-linear model** is most common in economics because many economic relationships involve percentage changes (returns to education, inflation effects, price responses). When in doubt, start with log-linear.
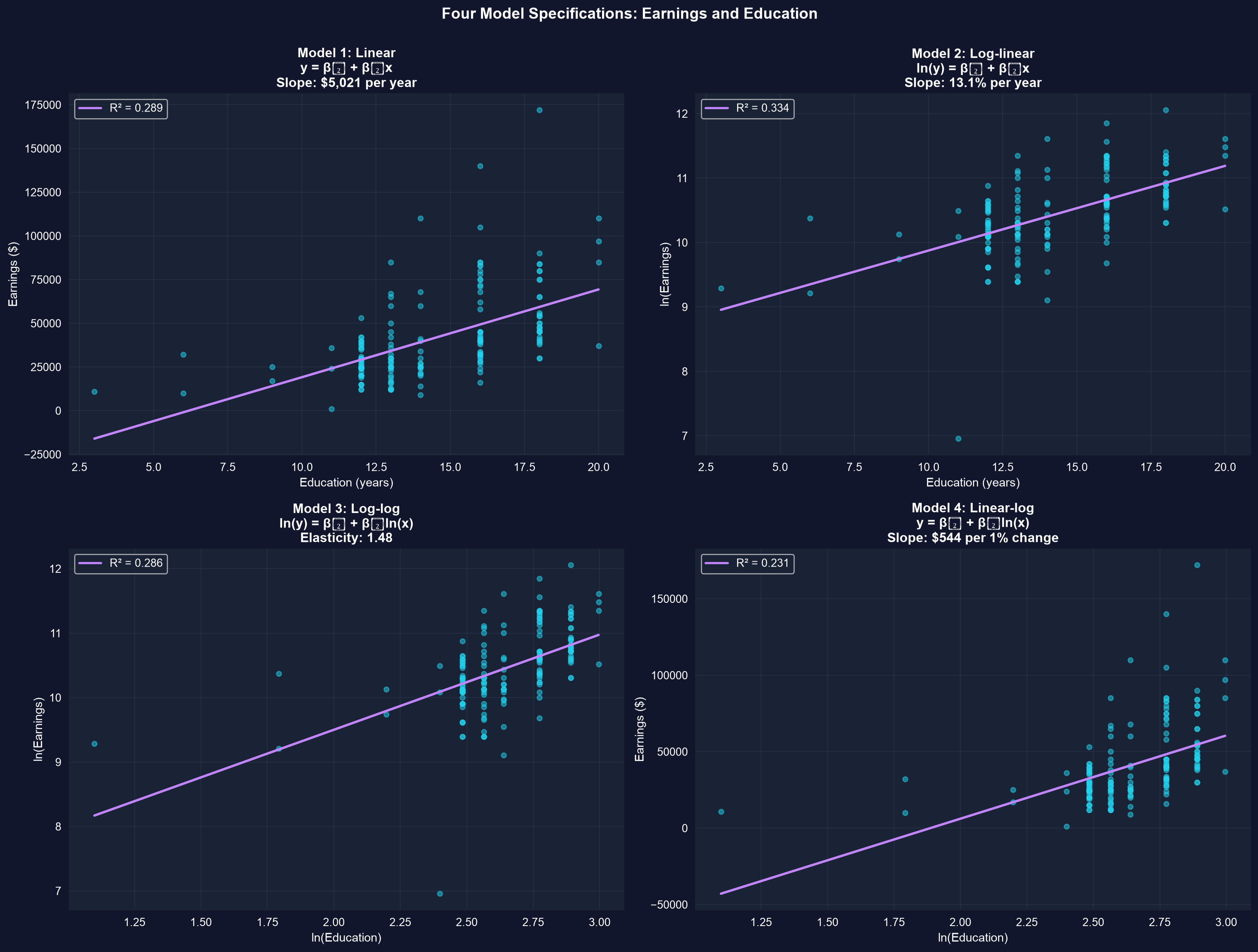
### Visualizing All Four Models
The 2×2 grid below plots each specification with its fitted line on the appropriate axes — note how the log transformations straighten the curvature that the linear model misses.
```{python}
# Create 2x2 comparison plot
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
# Model 1: Linear
axes[0, 0].scatter(data_earnings['education'], data_earnings['earnings'],
alpha=0.5, s=20, color='#22d3ee') # alpha = transparency, s = marker size
axes[0, 0].plot(data_earnings['education'], model_linear.predict(),
color='#c084fc', linewidth=2, label=f'R² = {model_linear._r2:.3f}')
axes[0, 0].set_xlabel('Education (years)', fontsize=11)
axes[0, 0].set_ylabel('Earnings ($)', fontsize=11)
axes[0, 0].set_title('Model 1: Linear\ny = β₀ + β₁x\nSlope: $5,021 per year',
fontsize=12, fontweight='bold')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# Model 2: Log-linear
axes[0, 1].scatter(data_earnings['education'], data_earnings['lnearn'],
alpha=0.5, s=20, color='#22d3ee')
axes[0, 1].plot(data_earnings['education'], model_loglin.predict(),
color='#c084fc', linewidth=2, label=f'R² = {model_loglin._r2:.3f}')
axes[0, 1].set_xlabel('Education (years)', fontsize=11)
axes[0, 1].set_ylabel('ln(Earnings)', fontsize=11)
axes[0, 1].set_title('Model 2: Log-linear\nln(y) = β₀ + β₁x\nSlope: 13.1% per year',
fontsize=12, fontweight='bold')
axes[0, 1].legend()
axes[0, 1].grid(True, alpha=0.3)
# Model 3: Log-log
axes[1, 0].scatter(data_earnings['lneduc'], data_earnings['lnearn'],
alpha=0.5, s=20, color='#22d3ee')
axes[1, 0].plot(data_earnings['lneduc'], model_loglog.predict(),
color='#c084fc', linewidth=2, label=f'R² = {model_loglog._r2:.3f}')
axes[1, 0].set_xlabel('ln(Education)', fontsize=11)
axes[1, 0].set_ylabel('ln(Earnings)', fontsize=11)
axes[1, 0].set_title('Model 3: Log-log\nln(y) = β₀ + β₁ln(x)\nElasticity: 1.48',
fontsize=12, fontweight='bold')
axes[1, 0].legend()
axes[1, 0].grid(True, alpha=0.3)
# Model 4: Linear-log
axes[1, 1].scatter(data_earnings['lneduc'], data_earnings['earnings'],
alpha=0.5, s=20, color='#22d3ee')
axes[1, 1].plot(data_earnings['lneduc'], model_linlog.predict(),
color='#c084fc', linewidth=2, label=f'R² = {model_linlog._r2:.3f}')
axes[1, 1].set_xlabel('ln(Education)', fontsize=11)
axes[1, 1].set_ylabel('Earnings ($)', fontsize=11)
axes[1, 1].set_title('Model 4: Linear-log\ny = β₀ + β₁ln(x)\nSlope: $544 per 1% change',
fontsize=12, fontweight='bold')
axes[1, 1].legend()
axes[1, 1].grid(True, alpha=0.3)
plt.suptitle('Four Model Specifications: Earnings and Education',
fontsize=14, fontweight='bold', y=1.00)
plt.tight_layout()
plt.show()
```
**What to look for across the four panels:**
- **Model 1 (linear)**: Straight line fit, but residuals may be heteroskedastic
- **Model 2 (log-linear)**: Best fit among the ln(earnings) models, captures curvature in original data
- **Model 3 (log-log)**: Both axes logged, captures elasticity
- **Model 4 (linear-log)**: Captures diminishing returns to education
## 9.4 Further Uses: Exponential Growth
**Application:** Modeling exponential growth in time series data
Many economic series grow **exponentially** over time:
$$x_t = x_0 \times (1+r)^t$$
Where:
- x₀ = initial value
- r = constant growth rate
- t = time period
**Taking logarithms:**
$$\ln(x_t) = \ln(x_0) + \ln(1+r) \times t \approx \ln(x_0) + r \times t$$
**Key insight:** Exponential growth in levels → **linear growth in logs**!
**Regression model:**
$$\ln(x_t) = \beta_0 + \beta_1 \times t + \varepsilon$$
The slope β₁ directly estimates the growth rate r.
**Example:** S&P 500 stock index 1927-2019
```{python}
# Load S&P 500 data
data_sp500 = pd.read_stata(GITHUB_DATA_URL + 'AED_SP500INDEX.DTA')
# S&P 500 INDEX DATA (1927-2019)
print(data_sp500[['year', 'sp500', 'lnsp500']].describe())
print("\nFirst and last years:")
print(data_sp500[['year', 'sp500', 'lnsp500']].head(3))
print("...")
print(data_sp500[['year', 'sp500', 'lnsp500']].tail(3))
```
Now we regress ln(sp500) on year — the slope directly estimates the average annual growth rate of the index, and the Rule of 72 converts it into a doubling time.
```{python}
# Estimate exponential growth model
# EXPONENTIAL GROWTH MODEL: ln(sp500) = β₀ + β₁(year)
model_sp500 = pf.feols('lnsp500 ~ year', data=data_sp500)
# Key results
intercept_sp = model_sp500.coef()['Intercept']
growth_rate = model_sp500.coef()['year']
r2_sp = model_sp500._r2
print(f"Estimated equation: ln(SP500) = {intercept_sp:.4f} + {growth_rate:.6f} x year")
print(f"Estimated annual growth rate: {100*growth_rate:.4f}% per year")
print(f"Rule of 72: doubles every {72/(100*growth_rate):.1f} years")
print(f"R-squared: {r2_sp:.4f} ({r2_sp*100:.1f}% of variation explained)")
# Full regression output
model_sp500.summary()
```
> **Key Concept 9.6: Linearizing Exponential Growth**
>
> When a variable grows **exponentially** (x_t = x₀(1+r)^t), its logarithm grows **linearly**:
>
> $$\ln(x_t) \approx \ln(x_0) + r \times t$$
>
> This transformation is powerful because it converts a **nonlinear** growth pattern into a **linear** regression model, where the slope coefficient directly estimates the **constant growth rate** r.
>
> **Practical implication:** To estimate the average growth rate of any exponentially growing series (GDP, stock prices, population), simply regress ln(x) on time. The slope is the growth rate.
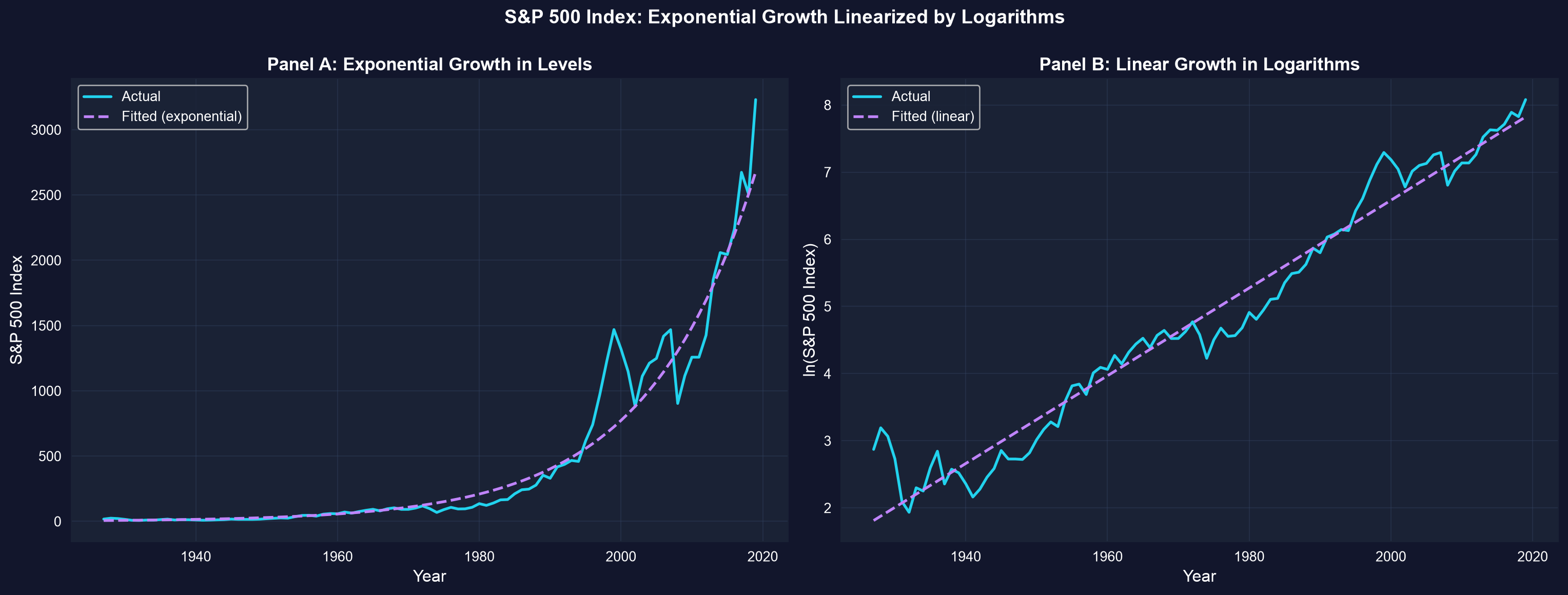
### Visualizing Exponential Growth
The two panels below show the same S&P 500 series twice: as an exponential curve in levels (left) and as a near-straight line after taking logs (right) — visual proof that the log transformation linearizes compound growth.
```{python}
# Create visualization showing exponential vs linear in logs
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
# Panel A: Exponential growth in levels
# Apply retransformation bias correction (normal-errors adjustment: multiply by exp(MSE/2))
n = len(data_sp500)
k = 2 # number of parameters: intercept + slope
MSE = np.sum(model_sp500._u_hat**2) / (n - k)
psp500 = np.exp(model_sp500.predict()) * np.exp(MSE/2) # exp(MSE/2) corrects for log-retransformation bias
axes[0].plot(data_sp500['year'], data_sp500['sp500'], linewidth=2,
label='Actual', color='#22d3ee')
axes[0].plot(data_sp500['year'], psp500, linewidth=2, linestyle='--',
label='Fitted (exponential)', color='#c084fc')
axes[0].set_xlabel('Year', fontsize=12)
axes[0].set_ylabel('S&P 500 Index', fontsize=12)
axes[0].set_title('Panel A: Exponential Growth in Levels',
fontsize=13, fontweight='bold')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# Panel B: Linear growth in logs
axes[1].plot(data_sp500['year'], data_sp500['lnsp500'], linewidth=2,
label='Actual', color='#22d3ee')
axes[1].plot(data_sp500['year'], model_sp500.predict(), linewidth=2,
linestyle='--', label='Fitted (linear)', color='#c084fc')
axes[1].set_xlabel('Year', fontsize=12)
axes[1].set_ylabel('ln(S&P 500 Index)', fontsize=12)
axes[1].set_title('Panel B: Linear Growth in Logarithms',
fontsize=13, fontweight='bold')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.suptitle('S&P 500 Index: Exponential Growth Linearized by Logarithms',
fontsize=14, fontweight='bold', y=1.00)
plt.tight_layout()
plt.show()
```
**What to look for in this comparison:**
- **Left panel**: Exponential curve in levels — hard to model with a straight line
- **Right panel**: Straight line in logs — easy to model with OLS
- **The slope** of the line in the right panel directly estimates the average growth rate
> **Key Concept 9.7: The Rule of 72**
>
> The **Rule of 72** provides a quick estimate of **doubling time** for compound growth:
>
> $$\text{Doubling time} \approx \frac{72}{r}$$
>
> where r is the **percentage** growth rate. This approximation derives from the logarithmic identity: ln(2) ≈ 0.693, combined with ln(1+r) ≈ r for small r.
>
> **Examples:**
>
> - S&P 500 at 6.5% growth → doubles every 72/6.5 ≈ 11 years
> - GDP at 3% growth → doubles every 72/3 = 24 years
> - Population at 1% growth → doubles every 72/1 = 72 years
>
> **Practical value:** The Rule of 72 converts growth rates into an intuitive time horizon without needing a calculator.
## Key Takeaways
1. **Natural logarithms** let us work with **proportionate changes** instead of absolute changes.
- Key approximation: Δln(x) ≈ Δx/x (proportionate change)
- 100 × Δln(x) ≈ percentage change in x
- This approximation is excellent for small changes (< 10%)
2. **Four model specifications** give different interpretations:
| Model | Specification | Interpretation of β₁ |
|-------|---------------|---------------------|
| **Linear** | y = β₀ + β₁x | Δy/Δx (absolute change) |
| **Log-linear** | ln(y) = β₀ + β₁x | Semi-elasticity: (Δy/y)/Δx |
| **Log-log** | ln(y) = β₀ + β₁ln(x) | Elasticity: (Δy/y)/(Δx/x) |
| **Linear-log** | y = β₀ + β₁ln(x) | Δy/(Δx/x) |
3. **Model selection** depends on economic theory, data properties, and interpretation needs:
- R² comparison (higher is better, but only comparable across models with the same dependent variable — and not the only criterion)
- Economic theory should guide functional form choice
- Log-linear is most common in applied economics (earnings, prices)
4. **Earnings-Education results** illustrate the four specifications:
- **Linear:** Each year of education is associated with \$5,021 more earnings
- **Log-linear:** Each year of education is associated with 13.1% more earnings (best fit among ln(y) models, R² = 0.334)
- **Log-log:** 1% more education is associated with 1.48% more earnings (elasticity)
- **Linear-log:** 1% more education is associated with \$544 more earnings
5. **Exponential growth** becomes **linear in logs:**
- If x grows exponentially: x_t = x₀(1+r)^t
- Then ln(x) grows linearly: ln(x_t) ≈ ln(x₀) + r·t
- Regression slope directly estimates the growth rate
- S&P 500: 6.5% annual growth (1927-2019), doubling every 11 years
6. **When to use logarithmic transformations:**
- Dependent variable is right-skewed (earnings, prices, firm size)
- Economic theory predicts percentage effects (elasticities)
- Multiplicative relationships between variables
- Exponential growth or decay patterns
- Not when variables can be zero or negative (ln is undefined)
**Python Libraries and Code:**
This single code block reproduces the core workflow of Chapter 9. It is self-contained — copy it into an empty notebook and run it to review the complete pipeline from logarithmic approximations to semi-elasticity, elasticity, model comparison, and exponential growth estimation.
```python
# =============================================================================
# CHAPTER 9 CHEAT SHEET: Models with Natural Logarithms
# =============================================================================
# --- Libraries ---
import numpy as np # logarithms and exponentials
import pandas as pd # data loading and manipulation
import matplotlib.pyplot as plt # creating plots and visualizations
import pyfixest as pf # fast estimation with robust SEs
# =============================================================================
# STEP 1: Load the earnings-education dataset
# =============================================================================
# pd.read_stata() reads Stata .dta files directly from a URL
url_earn = "https://raw.githubusercontent.com/quarcs-lab/data-open/master/AED/AED_EARNINGS.DTA"
data_earnings = pd.read_stata(url_earn)
print(f"Dataset: {data_earnings.shape[0]} observations, {data_earnings.shape[1]} variables")
# =============================================================================
# STEP 2: Logarithmic approximation — why economists use logs
# =============================================================================
# Key property: Δln(x) ≈ Δx/x (proportionate change)
# Multiplying by 100 gives the percentage change
x0, x1 = 40, 40.4
exact = (x1 - x0) / x0
approx = np.log(x1) - np.log(x0)
print(f"Change from {x0} to {x1}:")
print(f" Exact proportionate change: {exact:.6f} ({exact*100:.2f}%)")
print(f" Log approximation Δln(x): {approx:.6f} ({approx*100:.2f}%)")
# =============================================================================
# STEP 3: Descriptive statistics and log transformations
# =============================================================================
# Create log-transformed variables for the regression models
data_earnings['lnearn'] = np.log(data_earnings['earnings'])
data_earnings['lneduc'] = np.log(data_earnings['education'])
print(data_earnings[['earnings', 'lnearn', 'education', 'lneduc']].describe().round(2))
# =============================================================================
# STEP 4: Estimate all four model specifications
# =============================================================================
# Each model answers a different economic question about earnings and education
# Model 1: Linear — Δy = β₁Δx (dollar change per year of education)
model_linear = pf.feols('earnings ~ education', data=data_earnings)
# Model 2: Log-linear — 100β₁ ≈ % change in y per unit x (semi-elasticity)
model_loglin = pf.feols('lnearn ~ education', data=data_earnings)
# Model 3: Log-log — β₁ ≈ % change in y per % change in x (elasticity)
model_loglog = pf.feols('lnearn ~ lneduc', data=data_earnings)
# Model 4: Linear-log — β₁/100 ≈ dollar change per % change in x
model_linlog = pf.feols('earnings ~ lneduc', data=data_earnings)
# Print the most important model: log-linear (semi-elasticity)
semi_elast = model_loglin.coef()['education']
print(f"Log-linear: each year of education → {100*semi_elast:.1f}% higher earnings")
print(f"Log-log elasticity: {model_loglog.coef()['lneduc']:.3f}")
# Full regression table for the log-linear model
model_loglin.summary()
# =============================================================================
# STEP 5: Compare all four models side by side
# =============================================================================
# The comparison shows that model choice affects both R² and interpretation
models = {
'Linear': ('y ~ x', model_linear, 'education', '${:,.0f} per year'),
'Log-linear': ('ln(y) ~ x', model_loglin, 'education', '{:.1f}% per year'),
'Log-log': ('ln(y) ~ ln(x)', model_loglog, 'lneduc', '{:.2f}% per 1%'),
'Linear-log': ('y ~ ln(x)', model_linlog, 'lneduc', '${:,.0f} per 1%'),
}
print(f"{'Model':<12} {'Specification':<16} {'Slope':>10} {'R²':>8} Interpretation")
print("-" * 75)
for name, (spec, m, var, fmt) in models.items():
slope = m.coef()[var]
# Scale the slope to match each model's interpretation
scaled = 100*slope if name == 'Log-linear' else slope/100 if name == 'Linear-log' else slope
interp = fmt.format(scaled)
print(f"{name:<12} {spec:<16} {slope:>10.4f} {m._r2:>8.3f} {interp}")
# =============================================================================
# STEP 6: Scatter plot with the log-linear fitted line
# =============================================================================
# The log-linear model (semi-elasticity) fits best among the ln(earnings) models
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(data_earnings['education'], data_earnings['lnearn'], s=50, alpha=0.7)
ax.plot(data_earnings['education'], model_loglin.predict(),
color='red', linewidth=2, label='Fitted line')
ax.set_xlabel('Education (years)')
ax.set_ylabel('ln(Earnings)')
ax.set_title(f'Log-Linear Model: semi-elasticity = {semi_elast:.4f} (R² = {model_loglin._r2:.3f})')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# =============================================================================
# STEP 7: Exponential growth — S&P 500 and the Rule of 72
# =============================================================================
# Exponential growth in levels becomes linear in logs:
# ln(x_t) ≈ ln(x₀) + r × t, where slope r = annual growth rate
url_sp500 = "https://raw.githubusercontent.com/quarcs-lab/data-open/master/AED/AED_SP500INDEX.DTA"
data_sp500 = pd.read_stata(url_sp500)
model_sp500 = pf.feols('lnsp500 ~ year', data=data_sp500)
growth_rate = model_sp500.coef()['year']
print(f"S&P 500 estimated growth rate: {100*growth_rate:.2f}% per year")
print(f"Rule of 72: doubles every {72/(100*growth_rate):.1f} years")
print(f"R-squared: {model_sp500._r2:.4f}")
# Visualize: exponential in levels vs. linear in logs
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
axes[0].plot(data_sp500['year'], data_sp500['sp500'], linewidth=2)
axes[0].set_xlabel('Year')
axes[0].set_ylabel('S&P 500 Index')
axes[0].set_title('Exponential Growth in Levels')
axes[0].grid(True, alpha=0.3)
axes[1].plot(data_sp500['year'], data_sp500['lnsp500'], linewidth=2)
axes[1].plot(data_sp500['year'], model_sp500.predict(),
color='red', linewidth=2, linestyle='--', label='Fitted (linear)')
axes[1].set_xlabel('Year')
axes[1].set_ylabel('ln(S&P 500 Index)')
axes[1].set_title(f'Linear in Logs: growth = {100*growth_rate:.2f}%/year')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
**Try it yourself!** Copy this code into an empty Google Colab notebook and run it: [Open Colab](https://colab.research.google.com/notebooks/empty.ipynb)
**Next Steps:**
- **Chapter 10**: Extend to multiple regression with several explanatory variables
- **Chapter 11**: Statistical inference for multiple regression models
- **Chapter 15**: Further variable transformations (polynomials, interactions)
---
**Congratulations!** You now understand how to choose between model specifications, interpret coefficients in log models, and estimate elasticities and semi-elasticities. These tools are fundamental to empirical work in labor economics, industrial organization, macroeconomics, and development economics!
> **Common Mistakes to Avoid**
>
> - **Misinterpreting log-linear coefficients**: A one-unit change in X leads to approximately a (b x 100)% change in Y, not a change of b units
> - **Forgetting that log(0) is undefined**: Log transformations require strictly positive values
> - **Confusing elasticities with semi-elasticities**: The log-log slope is an elasticity (% change in Y per 1% change in X); the log-linear slope is a semi-elasticity (% change in Y per one-unit change in X)
## Practice Exercises
**Exercise 1: Logarithmic Approximation Accuracy**
The logarithmic approximation Δln(x) ≈ Δx/x works well for small changes. Test its accuracy:
a) Compute the exact proportionate change and the log approximation for x increasing from 100 to 101 (1% change). How close are they?
b) Repeat for x increasing from 100 to 110 (10% change). Is the approximation still good?
c) Repeat for x increasing from 100 to 150 (50% change). What happens to the approximation error?
d) At what percentage change does the approximation error exceed 1 percentage point?
**Exercise 2: Interpreting Semi-Elasticity**
A researcher estimates the following log-linear model: ln(wage) = 1.50 + 0.085 × experience, where wage is hourly wage in dollars and experience is years of work experience.
a) Interpret the coefficient 0.085 in economic terms.
b) What is the predicted percentage change in wages for a worker gaining 5 more years of experience?
c) Calculate the exact percentage change using 100 × (e^(0.085×5) - 1). How does it compare to the approximation?
**Exercise 3: Interpreting Elasticity**
An economist estimates a demand function: ln(Q) = 5.2 - 1.3 × ln(P), where Q is quantity demanded and P is price.
a) What is the price elasticity of demand? Is demand elastic or inelastic?
b) If the price increases by 10%, what is the predicted percentage change in quantity demanded?
c) Why is the log-log specification natural for demand analysis?
**Exercise 4: Model Specification Choice**
For each research question below, recommend the most appropriate model specification (linear, log-linear, log-log, or linear-log) and explain your reasoning:
a) How much does an additional bedroom add to house price (in dollars)?
b) What is the percentage return to each additional year of education?
c) What is the price elasticity of demand for gasoline?
d) How does GDP growth relate to years since a policy reform?
**Exercise 5: Exponential Growth and Rule of 72**
A country's real GDP per capita was \$5,000 in 1990 and grew at an average rate of 4% per year.
a) Using the Rule of 72, approximately when did GDP per capita reach \$10,000?
b) Write the exponential growth equation for this country's GDP.
c) What regression model would you estimate to find the growth rate from data? Write the specification.
d) If another country grew at 2% per year, how many times longer would it take to double its GDP?
**Exercise 6: Comparing Model Specifications with Data**
Using the earnings-education results from Section 9.3:
a) A worker has 12 years of education. Using the linear model, predict their earnings. Using the log-linear model, predict their earnings (hint: you need to exponentiate).
b) Repeat for a worker with 18 years of education. Which model gives a larger predicted difference between 12 and 18 years?
c) The log-linear model predicts a 13.1% increase per year of education regardless of current earnings. Explain why this is economically more appealing than a fixed dollar increase.
d) Why can't we directly compare R² values between the linear model (R² = 0.289) and the log-linear model (R² = 0.334)?
## Case Studies
### Case Study: Logarithmic Models for Global Labor Productivity
In this case study, you'll apply logarithmic model specifications to analyze **cross-country labor productivity** — a central question in development economics. You'll use the same Convergence Clubs dataset from earlier chapters, but now focus on how log transformations reveal economic relationships that linear models miss.
**Research Question:** How do logarithmic transformations improve our understanding of cross-country productivity relationships and growth patterns?
**Background:**
Labor productivity varies enormously across countries — from less than \$1,000 per worker in the poorest nations to over \$100,000 in the richest. This extreme right-skewness makes logarithmic transformations essential for meaningful analysis. Development economists use semi-elasticities and elasticities to measure how factors like human capital and physical capital contribute to productivity differences.
**Dataset:**
We'll use the **Mendez Convergence Clubs dataset** containing:
- **country**: Country name (108 countries)
- **year**: Year of observation (1990-2014)
- **lp**: Labor productivity (output per worker, in dollars)
- **kl**: Capital per worker (physical capital stock, in dollars)
- **h**: Human capital index (based on years of schooling and returns to education)
```{python}
# Load the Convergence Clubs dataset
url_mendez = "https://raw.githubusercontent.com/quarcs-lab/mendez2020-convergence-clubs-code-data/master/assets/dat.csv"
data_cc = pd.read_csv(url_mendez)
# CONVERGENCE CLUBS DATASET
print(f"Observations: {len(data_cc)}")
print(f"Countries: {data_cc['country'].nunique()}")
print(f"Years: {data_cc['year'].min():.0f} to {data_cc['year'].max():.0f}")
print(f"\nVariables: {list(data_cc.columns)}")
print("\nFirst 10 observations:")
data_cc[['country', 'year', 'lp', 'kl', 'h']].head(10)
```
### How to Use These Tasks
1. **Read** each task carefully before starting
2. **Write your code** in the provided cells (replace `_____` blanks in guided tasks)
3. **Run your code** to see results
4. **Answer the questions** by interpreting your output
5. **Check your understanding** against the Key Concepts
**Progressive difficulty:**
- Tasks 1-2: **Guided** (fill in blanks with `_____`)
- Tasks 3-4: **Semi-guided** (partial code structure provided)
- Tasks 5-6: **Independent** (write from outline)
**Tip:** Type the code rather than copying — it helps reinforce the concepts!
#### Task 1: Explore Productivity Data (Guided)
**Objective:** Understand why logarithmic transformations are essential for cross-country productivity data.
**Connection:** Section 9.1 (Natural Logarithm Function)
**Your task:** Filter the data to 2014, compute summary statistics for productivity in levels and logs, and compare the distributions.
a) What is the ratio of the highest to lowest labor productivity? What does this tell you about skewness?
b) How does the standard deviation change after log transformation?
c) Compare the mean and median in levels vs. logs. Which distribution is more symmetric?
```python
# Task 1: Explore Productivity Data (Guided)
# Filter to 2014 cross-section
data_2014 = data_cc[data_cc['year'] == _____].copy()
print(f"Countries in 2014: {len(data_2014)}")
# Create log-transformed variable
data_2014['ln_lp'] = np.log(_____)
# Summary statistics: levels vs logs
# LABOR PRODUCTIVITY: LEVELS VS. LOGS
print("\nIn levels (lp):")
print(data_2014['lp'].describe())
print(f"\nSkewness: {data_2014['lp'].skew():.3f}")
print("\nIn logarithms (ln_lp):")
print(data_2014['ln_lp'].describe())
print(f"\nSkewness: {data_2014['_____'].skew():.3f}")
# Ratio of highest to lowest
print(f"\nMax/Min ratio: {data_2014['lp'].max() / data_2014['lp'].min():.1f}x")
```
#### Task 2: Log-Linear Model for Productivity (Guided)
**Objective:** Estimate a log-linear model to measure the semi-elasticity of productivity with respect to human capital.
**Connection:** Section 9.2 (Semi-Elasticities)
**Your task:** Estimate ln(lp) = β₀ + β₁ × h and interpret the coefficient as a semi-elasticity.
a) What is the estimated semi-elasticity of productivity with respect to human capital?
b) By what percentage does productivity increase for each additional unit of the human capital index?
c) Is the coefficient statistically significant at the 5% level?
d) The estimated semi-elasticity here (≈ 1.18) is far larger than the |β₁| < 0.10 range where 100 × β₁ is a good approximation. Compute the exact percentage effect with 100 × (e^β₁ - 1) and compare it to the 100 × β₁ approximation — why do the two diverge so much here?
```python
# Task 2: Log-Linear Model for Productivity (Guided)
# Estimate: ln(lp) = β₀ + β₁ × h
model_hc = pf.feols('_____ ~ _____', data=data_2014)
# LOG-LINEAR MODEL: ln(productivity) ~ human capital
model_hc.summary()
# Interpret the semi-elasticity
beta_hc = model_hc.coef()['h']
print(f"\nSemi-elasticity: {beta_hc:.4f}")
print(f"Interpretation: Each unit increase in human capital is associated with")
print(f" a {100*beta_hc:.1f}% _____ in labor productivity.")
print(f"\nR² = {model_hc._r2:.3f}")
```
#### Task 3: Comparing Model Specifications (Semi-guided)
**Objective:** Estimate all four model specifications using productivity and capital per worker, then compare.
**Connection:** Section 9.3 (Example with four models)
**Your tasks:**
a) Estimate four models: linear (lp ~ kl), log-linear (ln_lp ~ kl), log-log (ln_lp ~ ln_kl), and linear-log (lp ~ ln_kl)
b) Create a comparison table showing the specification, slope coefficient, interpretation, and R² for each model
c) Which model provides the best fit? Which provides the most economically meaningful interpretation?
d) Why might the log-log specification be particularly appropriate for the productivity-capital relationship?
```python
# Task 3: Comparing Model Specifications (Semi-guided)
# Create log-transformed variables
data_2014['ln_kl'] = np.log(data_2014['kl'])
# Estimate the four models
m1_linear = pf.feols('lp ~ kl', data=data_2014)
m2_loglin = pf.feols('ln_lp ~ kl', data=data_2014)
m3_loglog = pf.feols('ln_lp ~ ln_kl', data=data_2014)
m4_linlog = pf.feols('lp ~ ln_kl', data=data_2014)
# Create comparison table
# Hint: Follow the pattern from Section 9.3
# MODEL COMPARISON: Productivity and Capital
# Your comparison table here
# ...
```
> **Key Concept 9.8: Functional Form and Cross-Country Comparisons**
>
> When analyzing cross-country data, **logarithmic models** are essential because:
>
> 1. **Skewed distributions** — Economic variables like GDP, productivity, and capital vary by factors of 100x or more across countries. Log transformations compress this range.
> 2. **Multiplicative relationships** — Production functions in economics are multiplicative (Y = A × K^α × L^β), which become linear in logs.
> 3. **Meaningful comparisons** — Percentage differences are more meaningful than absolute differences when comparing Malawi to the United States.
>
> **In practice:** The log-log specification is standard in cross-country growth analysis because the slope coefficient directly estimates the **output elasticity of capital** — a key parameter in growth theory.
#### Task 4: Elasticity of Productivity with Respect to Capital (Semi-guided)
**Objective:** Estimate the elasticity of labor productivity with respect to capital and interpret it in the context of economic growth theory.
**Connection:** Section 9.2 (Elasticities)
**Your tasks:**
a) Estimate the log-log model: ln(lp) = β₀ + β₁ × ln(kl). Report β₁ and R².
b) Interpret β₁ as an elasticity. Is there evidence of diminishing returns to capital (β₁ < 1)?
c) Construct a 95% confidence interval for the elasticity. Does it include 1?
d) In growth theory, the output elasticity of capital is often assumed to be about 1/3. Test H₀: β₁ = 0.33 against H₁: β₁ ≠ 0.33.
```python
# Task 4: Elasticity of Productivity (Semi-guided)
# Use the log-log model from Task 3
# LOG-LOG MODEL: ln(productivity) ~ ln(capital per worker)
m3_loglog.summary()
# Elasticity and confidence interval
elasticity = m3_loglog.coef()['ln_kl']
ci = m3_loglog.confint().loc['ln_kl']
print(f"\nElasticity: {elasticity:.4f}")
print(f"95% CI: [{ci.iloc[0]:.4f}, {ci.iloc[1]:.4f}]")
# Test H0: beta = 0.33
# Your hypothesis test here
# ...
```
#### Task 5: Productivity Growth Rates (Independent)
**Objective:** Estimate exponential growth rates for labor productivity across countries and apply the Rule of 72.
**Connection:** Section 9.4 (Exponential Growth)
**Your tasks:**
a) Compute the average labor productivity across all countries for each year (1990-2014)
b) Estimate the exponential growth model: ln(avg_lp) = β₀ + β₁ × year. What is the estimated average annual growth rate?
c) Apply the Rule of 72: approximately how many years does it take for average global labor productivity to double?
d) Repeat the growth rate estimation for two regions or groups of countries (e.g., high-income vs. low-income). Do growth rates differ?
```python
# Task 5: Productivity Growth Rates (Independent)
# Compute average productivity per year
# Your code here
# ...
```
#### Task 6: Development Policy Brief (Independent)
**Objective:** Synthesize your findings into a policy-relevant summary.
**Connection:** All sections
**Your task:**
Write a 200-300 word summary analyzing cross-country labor productivity using logarithmic models. Your brief should include:
1. **Data description:** How many countries, what time period, key variables
2. **Model selection:** Which logarithmic specification best captures the productivity-capital relationship and why
3. **Key findings:** Elasticity estimates, semi-elasticity of human capital, growth rates
4. **Policy implications:** What do these results suggest for developing countries seeking to increase productivity?
### Your Development Policy Brief
*(Write your 200-300 word summary here)*
---
> **Key Concept 9.9: Logarithmic Models in Development Economics**
>
> Logarithmic model specifications are the **standard tool** in development economics for analyzing cross-country differences because:
>
> - **Semi-elasticities** measure the percentage return to factors like education and human capital — directly informing policy about where to invest
> - **Elasticities** from log-log models estimate production function parameters (output elasticity of capital) — testing whether countries face diminishing returns
> - **Growth rates** from log-time regressions enable comparisons across countries growing at very different speeds
>
> **The bottom line:** Without logarithmic transformations, cross-country analysis would be dominated by a few rich outliers and miss the economic relationships that matter for development policy.
#### What You've Learned from This Case Study
**Congratulations!** You've applied logarithmic model specifications to real cross-country economic data.
**Statistical Skills:**
- Applied log transformations to highly skewed cross-country data
- Estimated and compared all four model specifications (linear, log-linear, log-log, linear-log)
- Interpreted semi-elasticities (human capital → productivity)
- Interpreted elasticities (capital → productivity, with diminishing returns)
- Estimated exponential growth rates and applied the Rule of 72
**Economic Insights:**
- Cross-country productivity distributions are highly right-skewed, requiring log transformations
- Human capital and physical capital are both strongly associated with higher productivity; for physical capital the estimated elasticity is below 1, indicating diminishing returns
- Log-log models connect directly to production function theory in economics
- Growth rates vary substantially across countries and regions
**Next Steps:**
- **Chapter 10**: Add multiple explanatory variables simultaneously (multiple regression)
- **Chapter 11**: Test joint hypotheses about capital AND human capital effects