---
title: 16. Checking the Model and Data
execute:
enabled: true
warning: false
---
**metricsAI: An Introduction to Econometrics with Python and AI in the Cloud**
*[Carlos Mendez](https://carlos-mendez.org)*
<img src="https://raw.githubusercontent.com/quarcs-lab/metricsai/main/images/ch16_visual_summary.jpg" alt="Chapter 16 Visual Summary" width="100%">
This notebook provides an interactive introduction to regression diagnostics and model validation. All code runs directly in Google Colab without any local setup.
[](https://colab.research.google.com/github/quarcs-lab/metricsai/blob/main/notebooks_colab/ch16_Checking_the_Model_and_Data.ipynb)
<div class="chapter-resources">
<a href="https://www.youtube.com/watch?v=3JVkwVXsyr0" target="_blank" class="resource-btn">🎬 AI Video</a>
<a href="https://carlos-mendez.my.canva.site/s16-checking-the-model-and-data-pdf" target="_blank" class="resource-btn">✨ AI Slides</a>
<a href="https://cameron.econ.ucdavis.edu/aed/traedv1_16" target="_blank" class="resource-btn">📊 Cameron Slides</a>
<a href="https://app.edcafe.ai/quizzes/69786b812f5d08069e04e07f" target="_blank" class="resource-btn">✏️ Quiz</a>
<a href="https://app.edcafe.ai/chatbots/6978a3122f5d08069e07219f" target="_blank" class="resource-btn">🤖 AI Tutor</a>
</div>
## Chapter Overview
This chapter focuses on checking model assumptions and diagnosing data problems. You'll gain both theoretical understanding and practical skills through hands-on Python examples.
**What you'll learn:**
- Identify and diagnose multicollinearity using correlation matrices and VIF
- Understand the consequences when each of the four core OLS assumptions fails
- Recognize omitted variable bias and specify appropriate control variables
- Understand endogeneity and when to use instrumental variables (IV)
- Detect and address heteroskedasticity using robust standard errors
- Identify autocorrelation in time series data and apply HAC-robust standard errors
- Interpret residual diagnostic plots to detect model violations
- Identify outliers and influential observations using DFITS and DFBETAS
- Apply appropriate diagnostic tests and remedies for common data problems
**Chapter outline:**
- 16.1 Multicollinearity
- 16.2-16.4 Model Assumptions, Incorrect Models, and Endogeneity
- 16.5 Heteroskedastic Errors
- 16.6 Correlated Errors (Autocorrelation)
- 16.7 Example: Democracy and Growth
- 16.8 Diagnostics: Residual Plots and Influential Observations
- Key Takeaways
- Practice Exercises
- Case Studies
**Datasets used:**
- **AED_EARNINGS_COMPLETE.DTA**: 872 full-time workers with earnings, age, education, and experience (2010)
- **AED_DEMOCRACY.DTA**: 131 countries with democracy, growth, and institutional variables (Acemoglu et al. 2008)
## Key Concepts
Six core ideas anchor this chapter. Skim them before you start, and come back when a term feels fuzzy. Each entry pairs a concrete example using the chapter's data with a non-technical analogy. Click a panel to expand it.
**Endogeneity:** A regressor is endogenous when it is correlated with the error term — typically because of an omitted variable, simultaneous causality, or measurement error. Endogeneity violates the zero-conditional-mean assumption ($E[u \mid x] = 0$) and biases OLS coefficients, so neither robust standard errors nor more data can rescue inference.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
In the chapter's `data_democracy` study (131 countries), regressing `democracy` on economic `growth` looks straightforward — but `growth` is plausibly endogenous: democracy may itself raise incomes and unobserved institutions drive both, so causality runs both ways. OLS on this pair is biased, and the chapter explicitly flags it as a textbook case where naive interpretation of the coefficient ("growth boosts democracy") confuses correlation with causation.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A blood test that *itself* spikes the patient's adrenaline is a contaminated measurement: the act of testing changes the thing being measured. Endogeneity is the regression's contaminated-test problem — the regressor and the unobserved error are entangled, so the recorded effect is partly the test, partly the contamination, and impossible to separate without a different instrument.
:::
::::
:::::
**Instrumental Variable (IV):** A regressor — call it $z$ — that *(i)* shifts the endogenous variable $x$ but *(ii)* affects the outcome $y$ only *through* $x$. Two-stage least squares uses $z$ to estimate the part of $x$ that is exogenous, recovering an unbiased estimate of $x$'s effect on $y$.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
The chapter cites Acemoglu, Johnson, and Robinson (2001), who use settler mortality as an IV for institutional quality across the 131 countries in `data_democracy`-related research. The instrument shifts colonial institutions (relevance) but, the argument goes, does not directly affect modern GDP otherwise (exogeneity). The 2SLS estimate of institutions on `growth` is far larger than the biased OLS estimate, dramatising the size of the endogeneity problem.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A locksmith's universal key opens only the front door of a building, but every visit to *anywhere* in the building must first pass through that door. The IV is that one key: it grants access to the variation you actually need (entry through the front door) while ignoring all the unrelated activity happening upstairs.
:::
::::
:::::
**Leverage:** A measure of how unusual an observation's regressor values are — how far the row's $\mathbf{x}_i$ sits from the centre of the regressor cloud. High-leverage points have an outsized capacity to *move* the fitted line if their $y$ values shift, regardless of whether their actual residual is small or large.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
Consider an `earnings` regression on `age + education + experience` in `data_earnings` ($n = 872$). A respondent with `education = 21` (PhD) and `experience = 0` (just graduated) sits at an unusual corner of regressor space — high leverage. Whether or not their earnings are unusual, the OLS line bends *more* in response to this row than to a typical mid-career worker — which is exactly when you want a leverage statistic to flag it.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
On a see-saw, a small child sitting on the very end has more pivoting power than a heavier adult sitting near the centre. Leverage in regression is exactly that physics: distance from the centre of the regressor cloud determines how much each observation can tip the fitted line, *independent* of how heavy (residual-size) that observation actually is.
:::
::::
:::::
**Cook's Distance:** A composite influence statistic that combines an observation's leverage and its residual size into one summary number. Large Cook's-D values flag rows whose removal would meaningfully change the fitted coefficients; the standard rule of thumb is to investigate any value above $4/n$.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
Computing Cook's distance for the earnings regression on `data_earnings` (872 workers) flags a small handful of outliers — a few very high earners far from the bulk of the sample. The chapter compares OLS coefficients with and without these flagged points: when their removal changes the `education` coefficient by more than a standard error, they are influential, not just unusual.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A restaurant critic walks in unannounced and orders the entire menu. Whether or not they leave a tip, the chef will rearrange the kitchen around their visit because the *combination* of presence and impact is enormous. Cook's distance is the regression's critic-detector: not just "this observation is unusual" or "this observation has a big residual" — the product of both, the genuine influence on the menu.
:::
::::
:::::
**Auxiliary Regression:** A side regression of one regressor on all the others, used to compute diagnostics rather than answer a substantive question. Its $R^2$ feeds directly into the variance inflation factor: $\text{VIF}_j = 1/(1 - R_j^2)$.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
For `earnings ~ age + education + agebyeduc` on `data_earnings`, the chapter runs the auxiliary regression `agebyeduc ~ age + education` and finds $R^2 \approx 0.973$. Plugging that into the VIF formula gives $\text{VIF}_{\text{agebyeduc}} = 1/(1 - 0.973) \approx 37$ — severe multicollinearity, which explains why the individual t-statistic on the interaction term is so unreliable.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A theatre understudy steps in to play another character's role for one rehearsal — not because the play needs them, but because the director wants to see how easily their lines could be replaced by everyone else's. The auxiliary regression is that rehearsal: it doesn't appear in the final show, but it tells the director how much of *one* part is already implied by *the others*.
:::
::::
:::::
**Specification Test (RESET):** Ramsey's Regression Equation Specification Error Test adds powers of the fitted values ($\hat{y}^2, \hat{y}^3$) to the original regression and tests whether their coefficients are jointly zero. Rejection signals that the model has misspecified its functional form — typically a missing nonlinear term.
::::: {.columns}
:::: {.column width="50%"}
::: {.callout-tip collapse="true" appearance="simple" title="Example"}
A linear `earnings ~ age + education` model on `data_earnings` (872 workers) fails the RESET test once age enters quadratically — because the chapter's preferred quadratic-in-age specification (with peak earnings near age 50) has nonlinear structure the linear model misses. Rejecting RESET tells the analyst: a more flexible functional form is needed, before concluding anything else.
:::
::::
:::: {.column width="50%"}
::: {.callout-note collapse="true" appearance="simple" title="Analogy"}
A factory's quality-control inspector picks finished products at random and *re*-tests them with a tougher protocol than the assembly line. If the products fail the tougher test, the assembly line itself is suspect — not just one bad batch. RESET is the regression's quality-control re-test: it asks whether the fitted equation survives a stricter functional-form challenge.
:::
::::
:::::
## Setup
First, we import the necessary Python packages and configure the environment for reproducibility. All data will stream directly from GitHub.
```{python}
#| code-fold: true
#| code-summary: "Setup: Import libraries and configure environment"
# Import required packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import pyfixest as pf # fast OLS estimation
import statsmodels.api as sm # add_constant for VIF calculation
import statsmodels.formula.api as smf # for diagnostics-only models
from statsmodels.stats.outliers_influence import variance_inflation_factor, OLSInfluence
from statsmodels.stats.diagnostic import het_white, acorr_ljungbox
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.nonparametric.smoothers_lowess import lowess
from statsmodels.tsa.stattools import acf
from scipy import stats
import random
import os
# Set random seeds for reproducibility
RANDOM_SEED = 42
random.seed(RANDOM_SEED)
np.random.seed(RANDOM_SEED)
os.environ['PYTHONHASHSEED'] = str(RANDOM_SEED)
# GitHub data URL
GITHUB_DATA_URL = "https://raw.githubusercontent.com/quarcs-lab/data-open/master/AED/"
# Set plotting style (dark theme matching book design)
plt.style.use('dark_background')
sns.set_style("darkgrid")
plt.rcParams.update({
'axes.facecolor': '#1a2235',
'figure.facecolor': '#12162c',
'grid.color': '#3a4a6b',
'figure.figsize': (10, 6),
'text.color': 'white',
'axes.labelcolor': 'white',
'xtick.color': 'white',
'ytick.color': 'white',
'axes.edgecolor': '#1a2235',
})
# Chapter 16: Checking The Model And Data
print("\nSetup complete! Ready to explore model diagnostics.")
```
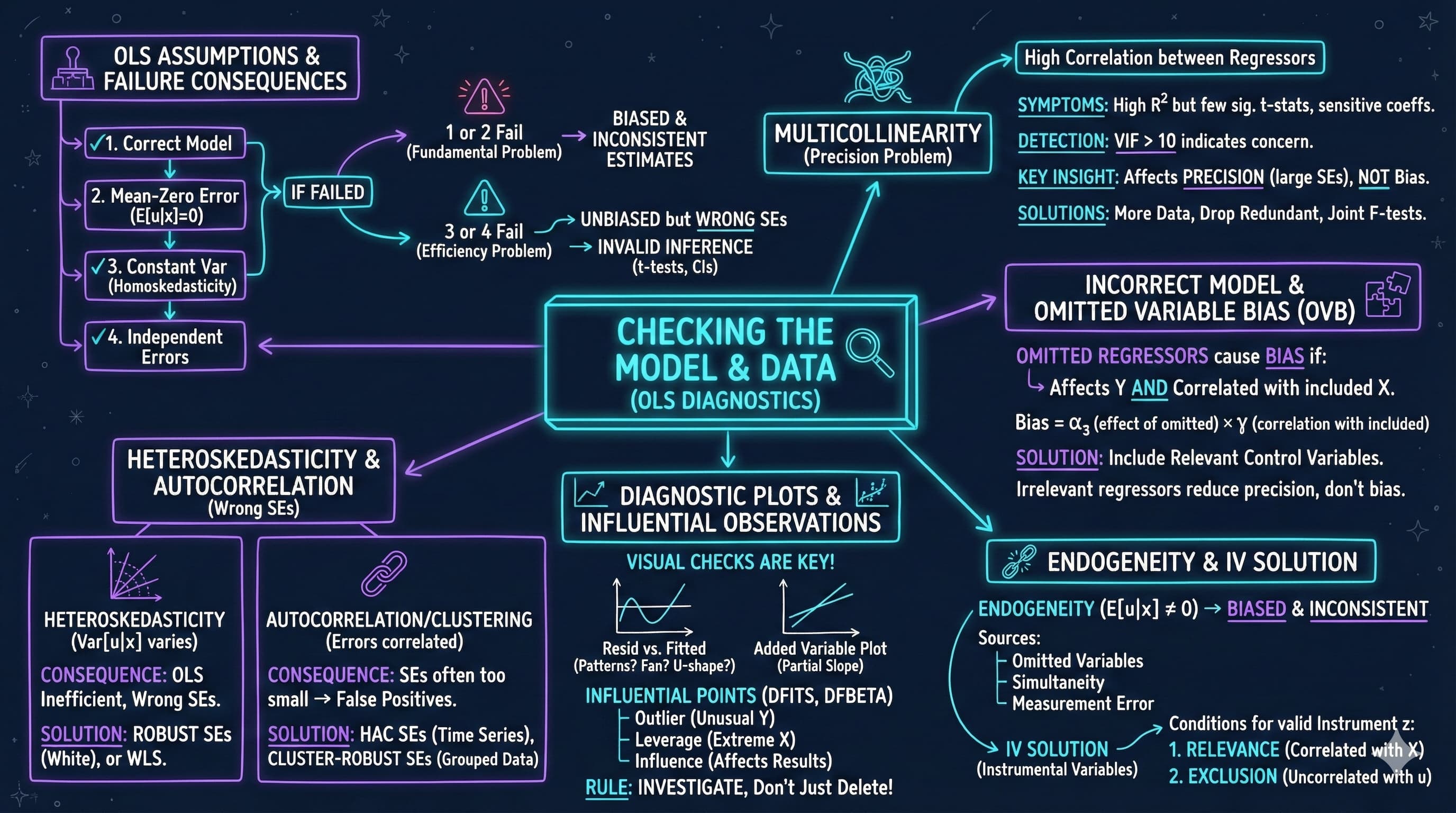
## 16.1 Multicollinearity
Multicollinearity occurs when regressors are highly correlated with each other. While OLS remains unbiased and consistent, individual coefficients may be imprecisely estimated.
**Effects of multicollinearity:**
- High standard errors on individual coefficients
- Low t-statistics (coefficients appear insignificant)
- Coefficients may have "wrong" signs
- Coefficients very sensitive to small data changes
- Joint tests may still be significant
**Detection methods:**
1. **High pairwise correlations** between regressors
2. **Variance Inflation Factor (VIF)**:
$$VIF_j = \frac{1}{1 - R_j^2}$$
where $R_j^2$ is from regressing $x_j$ on all other regressors
- VIF > 10 indicates serious multicollinearity
- VIF > 5 suggests investigating further
3. **Auxiliary regression**: Regress one variable on others
- High $R^2$ indicates multicollinearity
**Example**: Earnings regression with age, education, and age×education interaction
```{python}
# Read earnings data
data_earnings = pd.read_stata(GITHUB_DATA_URL + 'AED_EARNINGS_COMPLETE.DTA')
# 16.1 Multicollinearity
print("\nData summary:")
data_earnings[['earnings', 'age', 'education', 'agebyeduc']].describe()
# Base model without interaction
# Base Model: earnings ~ age + education
fit_base = pf.feols('earnings ~ age + education', data=data_earnings, vcov='HC1')
# Key results
print(f"Age coefficient: {fit_base.coef()['age']:,.2f} (SE: {fit_base.se()['age']:,.2f})")
print(f"Education coefficient: {fit_base.coef()['education']:,.2f} (SE: {fit_base.se()['education']:,.2f})")
print(f"R-squared: {fit_base._r2:.4f}")
# Full regression output
fit_base.summary()
```
Now we add the age×education interaction term to the same regression. Watch how the standard errors on `age` and `education` balloon relative to the base model above — that inflation is the fingerprint of multicollinearity.
```{python}
# Model with interaction (creates multicollinearity)
# Collinear Model: earnings ~ age + education + agebyeduc
fit_collinear = pf.feols('earnings ~ age + education + agebyeduc',
data=data_earnings, vcov='HC1')
fit_collinear.summary()
print("\nNote: Compare standard errors between base and collinear models.")
# Standard errors increase dramatically with the interaction term.
```
```{python}
# Correlation Matrix of Regressors
corr_matrix = data_earnings[['age', 'education', 'agebyeduc']].corr()
print(corr_matrix)
# Visualize correlation matrix
fig, ax = plt.subplots(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, fmt='.3f', cmap='coolwarm',
center=0, vmin=-1, vmax=1, ax=ax, cbar_kws={'label': 'Correlation'})
ax.set_title('Correlation Matrix of Regressors', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.show()
```
**What to look for in this correlation heatmap:**
- **Values close to +1 or -1** between regressors indicate high collinearity
- **Values above 0.9** are a strong warning sign for multicollinearity
- The interaction term (agebyeduc) will typically show high correlation with both main effects
```{python}
# Calculate VIF for all regressors
# Variance Inflation Factors (VIF)
# Prepare data for VIF calculation
X_vif = data_earnings[['age', 'education', 'agebyeduc']].copy()
X_vif = sm.add_constant(X_vif)
vif_data = pd.DataFrame()
vif_data["Variable"] = X_vif.columns
vif_data["VIF"] = [variance_inflation_factor(X_vif.values, i)
for i in range(X_vif.shape[1])]
print(vif_data)
print("\nInterpretation:")
print(" VIF > 10 indicates serious multicollinearity")
print(" VIF > 5 suggests investigating further")
print(f" agebyeduc VIF = {vif_data.loc[vif_data['Variable']=='agebyeduc', 'VIF'].values[0]:.1f} (SEVERE!)")
```
> **Key Concept 16.1: Multicollinearity and the Variance Inflation Factor**
>
> The Variance Inflation Factor quantifies multicollinearity: $VIF_j = 1/(1 - R_j^2)$, where $R_j^2$ is from regressing $x_j$ on all other regressors. VIF = 1 means no collinearity; VIF > 10 indicates serious problems (standard errors inflated by $\sqrt{10} \approx 3.2\times$). While OLS remains unbiased, individual coefficients become imprecise and may have "wrong" signs. Predictions and joint tests remain valid despite multicollinearity.
---
### Understanding VIF: When Multicollinearity Becomes a Problem
The VIF (Variance Inflation Factor) results reveal **severe multicollinearity** in the interaction model. Let's understand what this means:
**VIF Values from the Analysis:**
Typical results when including age × education interaction:
- **agebyeduc** (interaction): VIF ≈ **37** (SEVERE!)
- **age**: VIF ≈ **15-25** (HIGH)
- **education**: VIF ≈ **15-25** (HIGH)
- **Intercept**: the VIF on the constant term (≈ 411 here) is **not econometrically meaningful** and is conventionally ignored
**Interpreting VIF:**
The VIF formula: $VIF_j = \frac{1}{1 - R_j^2}$
where $R_j^2$ is from regressing $x_j$ on all other regressors.
**What the numbers mean:**
- **VIF = 1**: No multicollinearity (ideal)
- **VIF = 5**: Moderate multicollinearity (R² = 0.80)
- **VIF = 10**: High multicollinearity (R² = 0.90) - **investigate!**
- **VIF = 80**: Severe multicollinearity (R² = 0.9875) - **serious problem!**
**Why is agebyeduc VIF so high?**
The interaction term is nearly a perfect linear combination:
- age and education are correlated
- age × education inherits both correlations
- $R^2_{agebyeduc|age,educ} \approx 0.973$
- This means 97.3% of variation in the interaction is **predictable** from age and education alone!
**Consequences:**
1. **Standard errors inflate dramatically**:
- $SE(\hat{\beta}_j) = \sigma / \sqrt{(1-R_j^2) \cdot \sum(x_j - \bar{x}_j)^2}$
- When $R_j^2 \approx 1$: denominator → 0, so SE → ∞
- VIF = 37 means SE is $\sqrt{37} \approx 6$ times larger than with no collinearity!
2. **Individual t-statistics become small**:
- Even if the true effect is large
- Can't distinguish individual contributions
- May get "wrong" signs on coefficients
3. **Coefficients become unstable**:
- Small changes in data → large changes in estimates
- Sensitive to which observations are included
- High variance of estimators
**What Multicollinearity Does NOT Affect:**
**Still valid:**
- OLS remains **unbiased**
- **Predictions** still accurate
- **Joint F-tests** remain powerful
- **Overall R²** unchanged
**What breaks:**
- Individual **t-tests** unreliable
- **Standard errors** too large
- **Confidence intervals** too wide
- Can't **interpret** individual coefficients reliably
**Solutions:**
1. **Use joint F-tests** (not individual t-tests):
- Test $H_0: \beta_{age} = 0$ AND $\beta_{agebyeduc} = 0$ **together**
- These remain powerful despite multicollinearity
2. **Center variables** before interaction:
- Create: age_centered = age - mean(age)
- Reduces correlation between main effects and interaction
- Can dramatically reduce VIF
3. **Drop one of the collinear variables**:
- Only if you don't need both for your research question
- Not appropriate if interaction is theoretically important
4. **Collect more data** or **increase variation**:
- More observations → smaller SEs
- More variation in X → less correlation
5. **Ridge regression** or **regularization**:
- Shrinks coefficients toward zero
- Trades small bias for large reduction in variance
**The Auxiliary Regression:**
The output shows regressing agebyeduc ~ age + education gives **R² ≈ 0.973**:
- This confirms 97.3% of interaction variation is explained by main effects
- VIF = 1/(1-0.973) = 1/0.027 ≈ 37
**Practical Interpretation for Our Model:**
Despite high VIF:
- Joint F-test shows age and interaction are **jointly significant**
- We know age matters (from quadratic model)
- We know education matters (strong t-stat)
- Problem is **separating** the age vs. age×education effects
- Both matter, but we can't precisely estimate each one separately
```{python}
# Auxiliary regression to detect multicollinearity
# Auxiliary Regression: agebyeduc ~ age + education
fit_aux = pf.feols('agebyeduc ~ age + education', data=data_earnings)
fit_aux.summary()
print(f"\nR² from auxiliary regression: {fit_aux._r2:.4f}")
print(f"VIF formula: 1/(1-R²) = {1/(1-fit_aux._r2):.2f}")
# High R² indicates that agebyeduc is nearly a perfect combination of age and education.
```
### Joint Hypothesis Tests
Even with multicollinearity, joint tests can be powerful. Individual coefficients may be imprecise, but linear combinations may be precisely estimated.
```{python}
# Joint hypothesis tests
# The R matrix picks out the coefficient rows we want to test jointly (here age
# and agebyeduc); wald_test then evaluates H₀ that BOTH equal zero at once.
# Test 1: H₀: age = 0 AND agebyeduc = 0
print("Test 1: H₀: age = 0 AND agebyeduc = 0")
print(fit_collinear.wald_test(R=np.eye(len(fit_collinear.coef()))[[list(fit_collinear.coef().index).index(v) for v in ['age', 'agebyeduc']]]))
# Test 2: H₀: education = 0 AND agebyeduc = 0
print("Test 2: H₀: education = 0 AND agebyeduc = 0")
print(fit_collinear.wald_test(R=np.eye(len(fit_collinear.coef()))[[list(fit_collinear.coef().index).index(v) for v in ['education', 'agebyeduc']]]))
```
Joint tests are highly significant even though individual t-tests are weak. This is the power of joint testing with multicollinear regressors -- the F-test evaluates the combined contribution of correlated variables, avoiding the imprecision that plagues individual estimates.
> **Key Concept 16.2: Joint Hypothesis Tests Under Multicollinearity**
>
> Even when multicollinearity makes individual t-tests unreliable (high VIF, large standard errors), joint F-tests remain powerful. Testing whether a group of collinear variables is jointly significant avoids the imprecision problem because the F-test evaluates the combined contribution. Always use joint tests for groups of correlated regressors rather than relying on individual significance.
## 16.2-16.4 Model Assumptions
**Classical OLS Assumptions:**
1. **Linearity**: $y_i = \beta_1 + \beta_2 x_{2i} + \cdots + \beta_k x_{ki} + u_i$
2. **Zero conditional mean**: $E[u_i | x_i] = 0$
3. **Homoskedasticity**: $Var(u_i | x_i) = \sigma^2$
4. **No autocorrelation**: $u_i$ independent of $u_j$ for $i \neq j$
**Consequences of violations:**
| Assumption | Violation | OLS Properties | Solution |
|-----------|-----------|----------------|----------|
| 1 or 2 | Incorrect model / Endogeneity | Biased, Inconsistent | IV, better specification |
| 3 | Heteroskedasticity | Unbiased, Inefficient, Wrong SEs | Robust SEs, WLS |
| 4 | Autocorrelation | Unbiased, Inefficient, Wrong SEs | HAC SEs, FGLS |
**Key insight**: Violations of assumptions 3 and 4 don't bias coefficients, but invalidate standard errors and hypothesis tests.
```{python}
# 16.2-16.4: Model Assumptions
# \nClassical OLS assumptions:
# 1. Linear in parameters: E[y|x] = x'β
# 2. Random sample from population
# 3. No perfect collinearity
# 4. Zero conditional mean: E[u|x] = 0
# 5. Homoskedasticity: Var(u|x) = σ²
# 6. No autocorrelation: Cov(u_i, u_j) = 0
# \nConsequences of violations:
# Assumptions 1-4 violated → OLS biased and inconsistent
# Assumptions 5-6 violated → OLS unbiased but inefficient
# → Standard errors incorrect
print(" → Invalid inference (t-tests, CIs)")
# \nSolutions:
print(" Heteroskedasticity → Robust (HC) standard errors")
print(" Autocorrelation → HAC (Newey-West) standard errors")
print(" Endogeneity → Instrumental variables (IV)")
# Omitted variables → Add relevant controls
```
> **Key Concept 16.3: Consequences of OLS Assumption Violations**
>
> When assumptions 1 or 2 fail (incorrect model or endogeneity), OLS is biased and inconsistent -- a fundamental problem requiring model changes or instrumental variables. When assumptions 3 or 4 fail (heteroskedasticity or autocorrelation), OLS remains unbiased and consistent but standard errors are wrong, invalidating confidence intervals and hypothesis tests. The key distinction: bias requires fixing the model; wrong SEs require only changing the inference method.
## 16.5 Heteroskedastic Errors
Heteroskedasticity means the error variance depends on $x$: $Var(u_i | x_i) = \sigma_i^2 \neq \sigma^2$
**Common in:**
- Cross-sectional data (varies by unit size)
- Income/wealth data (variance increases with level)
**Solution**: Use heteroskedasticity-robust (HC) standard errors
- Also called White standard errors
- Coefficient estimates unchanged
- Only standard errors adjusted
- Usually larger (more conservative)
```{python}
# 16.5: Heteroskedastic Errors
# Regression with earnings data
# Earnings Regression: earnings ~ age + education
# Standard SEs
fit_standard = pf.feols('earnings ~ age + education', data=data_earnings)
print("\nWith Standard SEs:")
fit_standard.summary()
# Robust SEs
fit_robust = pf.feols('earnings ~ age + education', data=data_earnings, vcov='HC1')
# With Heteroskedasticity-Robust (HC1) SEs:
fit_robust.summary()
# Comparison
# SE Comparison: Standard vs Robust
se_comparison = pd.DataFrame({
'Variable': fit_standard.coef().index,
'Standard SE': fit_standard.se().values,
'Robust SE': fit_robust.se().values,
'Ratio (Robust/Standard)': (fit_robust.se() / fit_standard.se()).values
})
print(se_comparison)
print("\nNote: Here the robust SEs differ only modestly from the standard SEs (age slightly smaller, education about 13% larger), suggesting mild heteroskedasticity at most.")
```
> **Key Concept 16.4: Heteroskedasticity and Robust Standard Errors**
>
> Heteroskedasticity means the error variance depends on the regressors: $\text{Var}[u_i | \mathbf{x}_i] \neq \sigma^2$. OLS coefficients remain unbiased, but default standard errors are wrong -- typically too small, giving false confidence in precision. Use heteroskedasticity-robust (HC1/White) standard errors, which are valid whether or not heteroskedasticity is present. Always use robust SEs for cross-sectional data as a default practice.
---
### Why Robust Standard Errors Matter
The comparison between standard and robust SEs shows only **modest differences** in the earnings data, suggesting mild heteroskedasticity at most:
**Typical Results:**
| Variable | Standard SE | Robust SE | Ratio (Robust/Standard) |
|----------|-------------|-----------|------------------------|
| age | ~\$154 | ~\$151 | **0.98x** |
| education | ~\$570 | ~\$642 | **1.13x** |
**What This Tells Us:**
1. **Mild heteroskedasticity at most**:
- Robust SEs here differ only modestly from standard SEs (age slightly smaller, education ~13% larger)
- Any departure from constant error variance is small in this sample
- Robust SEs remain the safe default regardless
2. **Standard SEs are too small**:
- Lead to **overstated** t-statistics
- **False confidence** in precision
- **Overrejection** of null hypotheses (Type I error)
3. **Coefficients unchanged**:
- OLS estimates remain **unbiased** and **consistent**
- Only the **uncertainty** (SEs) is affected
- Predictions still accurate
**Why Heteroskedasticity in Earnings Data?**
Earnings data typically exhibit heteroskedasticity because:
1. **Scale effects**: High earners have more variable earnings
- CEO: \$1M ± \$500K (50% CV)
- Janitor: \$30K ± \$5K (17% CV)
2. **Unobserved heterogeneity**: Some people more variable than others
- Commission-based vs. salary
- Stable government job vs. volatile private sector
3. **Model misspecification**: Missing interactions or nonlinearities
- True model may have different slopes for different groups
**Visual Evidence:**
In the residual vs. fitted plot:
- Residuals should have **constant spread** (homoskedasticity)
- If spread **increases** with fitted values → heteroskedasticity
- Classic "megaphone" or "fan" shape
**Implications for Inference:**
**With standard SEs:**
- t-statistic for education: 10.19 → p < 0.001
- Conclusion: Highly significant
**With robust SEs:**
- t-statistic for education: 9.06 → p < 0.001
- Conclusion: Still significant, but less extreme
**The correction:**
- Larger SEs → wider confidence intervals
- More **conservative** (honest about uncertainty)
- Inference remains **valid**
**When to Use Robust SEs:**
**Always use for:**
- Cross-sectional data (almost always heteroskedastic)
- Large samples (asymptotically valid)
- When you're unsure (conservative approach)
- Publication-quality research
**Don't need for:**
- Experimental data with randomization
- Small samples (can be unreliable, use bootstrap instead)
- Time series (need HAC SEs instead)
**Types of Robust SEs:**
1. **HC0** (White 1980): Original heteroskedasticity-robust
- $\hat{V}_{HC0} = (X'X)^{-1}X'\text{diag}(\hat{u}_i^2)X(X'X)^{-1}$
2. **HC1** (degrees of freedom correction):
- Multiply HC0 by $n/(n-k)$
- Better in finite samples
- **Most common choice** (Stata default)
3. **HC2** and **HC3**: Further finite-sample improvements
- HC3 recommended for heteroskedasticity + influential observations
**Bottom Line:**
In this earnings regression:
- Education remains **highly significant** even with robust SEs
- But we're more **honest** about precision
- Robust SEs should be **default** for cross-sectional regressions
- Report robust SEs in all your empirical work!
## 16.6 Correlated Errors (Autocorrelation)
Autocorrelation occurs in time series when $Cov(u_t, u_s) \neq 0$ for $t \neq s$.
**AR(1) process**: $u_t = \rho u_{t-1} + \varepsilon_t$ where $|\rho| < 1$
**Consequences:**
- OLS unbiased and consistent
- Standard errors wrong (usually too small)
- t-statistics overstated
- False significance
**Solution**: Use HAC (Heteroskedasticity and Autocorrelation Consistent) standard errors
- Also called Newey-West standard errors
- Accounts for both heteroskedasticity and autocorrelation
**Detection**: Check autocorrelation function (ACF) of residuals
```{python}
# 16.6: Correlated Errors (Autocorrelation)
# Generate simulated time series data
print("\nSimulation: Time Series with Autocorrelated Errors")
n = 10000
np.random.seed(10101)
# Generate i.i.d. errors
e = np.random.normal(0, 1, n)
# Generate AR(1) errors: u_t = 0.8*u_{t-1} + e_t
u = np.zeros(n)
u[0] = 0
for t in range(1, n):
u[t] = 0.8 * u[t-1] + e[t] # 0.8 = AR(1) persistence parameter (high autocorrelation)
# Generate AR(1) regressor
v = np.random.normal(0, 1, n)
x = np.zeros(n)
x[0] = 0
for t in range(1, n):
x[t] = 0.8 * x[t-1] + v[t] # 0.8 = AR(1) persistence for regressor
# Generate y with autocorrelated error
y1 = 1 + 2*x + u
# Create DataFrame
ts_data = pd.DataFrame({'y1': y1, 'x': x})
print(f"\nGenerated {n} observations with AR(1) errors (ρ = 0.8)")
```
Now we fit the regression to the simulated series and inspect its residuals. Because we built AR(1) structure into the errors, the residual autocorrelation function (ACF) below should show a strong spike at lag 1 that decays gradually across later lags.
```{python}
# Estimate model and check residual autocorrelation
# Model: y ~ x (with autocorrelated errors)
fit_ts = pf.feols('y1 ~ x', data=ts_data)
residuals = fit_ts._u_hat
# Check autocorrelation of residuals
acf_vals = acf(residuals, nlags=10, fft=False)
print("\nResidual autocorrelations (first 10 lags):")
for lag, val in enumerate(acf_vals[:11]):
print(f" Lag {lag}: {val:.4f}")
# Plot ACF
fig, ax = plt.subplots(figsize=(10, 5))
plot_acf(residuals, lags=20, ax=ax)
ax.set_title('Autocorrelation Function of Residuals', fontsize=14, fontweight='bold')
ax.set_xlabel('Lag', fontsize=12)
ax.set_ylabel('ACF', fontsize=12)
plt.tight_layout()
plt.show()
```
**What to look for in the ACF plot:**
- **Bars extending beyond the confidence band** (shaded region) indicate statistically significant autocorrelation at that lag
- **Slowly decaying bars** suggest non-stationarity or strong persistence in the errors
- **A single significant spike at lag 1** suggests an AR(1) process; multiple significant lags suggest higher-order autocorrelation
> **Key Concept 16.5: Autocorrelation and HAC Standard Errors**
>
> Autocorrelation means errors are correlated over time ($\text{Cov}[u_t, u_s] \neq 0$), common in time series when economic shocks persist. OLS remains unbiased but standard errors are wrong -- typically too small, leading to false significance. Use HAC (Newey-West) standard errors for valid inference. Check the autocorrelation function (ACF) of residuals: significant autocorrelations at multiple lags indicate the problem. Severe autocorrelation drastically reduces the effective sample size.
---
### Autocorrelation: The Time Series Problem
The simulated AR(1) exercise (ρ = 0.8) reveals **strong autocorrelation** in the error process — a classic problem that invalidates standard inference:
**Autocorrelation Evidence:**
From the residuals of the fitted regression `y1 ~ x`:
- **Lag 1 autocorrelation**: ρ₁ ≈ **0.80** (very high — it matches the ρ = 0.8 we built into the errors)
- **Lag 5 autocorrelation**: ρ₅ ≈ **0.31** (decaying geometrically, close to $\rho^5 \approx 0.33$)
- **Lag 10 autocorrelation**: ρ₁₀ ≈ **0.09** (nearly gone by lag 10)
**What This Means:**
1. **Errors are correlated over time**:
- If this period's error is +1, the next period's is on average +0.8
- Errors **cluster**: positive errors tend to follow positive, negative follow negative
- Violates OLS assumption of **independent errors**
2. **Standard errors understate uncertainty**:
Because the errors are positively correlated, the usual OLS formula overstates how much independent information the sample contains. Correcting for the AR(1) structure inflates the variance of the estimator by the factor below, so honest (HAC) standard errors would be roughly $\sqrt{9} = 3$ times larger than the default OLS ones.
3. **Why does autocorrelation inflate the variance?**
With independent errors:
- $Var(\bar{u}) = \sigma^2/n$
- Information in n observations
With autocorrelation (ρ = 0.8):
- $Var(\bar{u}) \approx \sigma^2 \cdot \frac{1 + \rho}{1 - \rho} \cdot \frac{1}{n} = \sigma^2 \cdot 9 \cdot \frac{1}{n}$
- **9 times larger variance!**
- Effective sample size ≈ n/9
**The Correlogram (ACF Plot):**
The ACF plot shows:
- **Geometric decay** of the autocorrelations across lags
- The first several lags sit well outside the confidence band
- Classic signature of an **AR(1) error process**
- The errors have **persistent, but fading, memory**
**Why Is the Simulated Series Autocorrelated?**
The autocorrelation here is no accident — we built it into the data-generating process:
1. **The error process is AR(1) by construction**:
- Errors follow $u_t = 0.8\,u_{t-1} + \varepsilon_t$
- Each shock carries 80% of its value into the next period
2. **The regressor is also AR(1)**:
- $x_t = 0.8\,x_{t-1} + v_t$, so it too moves slowly
- Slow-moving x combined with slow-moving u is exactly what distorts OLS standard errors
3. **Persistence, not trend**:
- With $|\rho| < 1$ the series is stationary — it fluctuates around a fixed mean
- The memory fades geometrically rather than trending away
**Consequences for Inference:**
**With default SEs:**
- t-statistics look **too large** (default SEs are too small)
- p-values look **too small**
- False precision!
**With HAC SEs:**
- Standard errors widen by roughly $\sqrt{9} \approx 3\times$
- The slope on `x` stays **highly significant** (its true value is 2)
- Honest uncertainty
**The Solution: HAC (Newey-West) Standard Errors**
HAC SEs account for **both heteroskedasticity and autocorrelation**:
$$\hat{V}_{HAC} = (X'X)^{-1} \left( \sum_{j=-L}^L w_j \sum_t \hat{u}_t \hat{u}_{t-j} x_t x'_{t-j} \right) (X'X)^{-1}$$
where:
- $L$ = number of lags (rule of thumb: $L \approx 0.75 \cdot T^{1/3}$)
- $w_j$ = weights (declining with lag distance)
**Choosing the Lag Length (L):**
For the simulated series with T = 10,000 observations:
- Rule of thumb: $L \approx 0.75 \cdot 10000^{1/3} \approx 16$
- A larger L captures more of the (geometrically decaying) autocorrelation
- Too large an L, though, adds noise to the variance estimate
**First Differencing as Alternative:**
Transform: $\Delta y_t = y_t - y_{t-1}$
Differencing a persistent series:
- Sharply **lowers the residual autocorrelation**
- Changes interpretation: now modeling **changes**, not levels
- Is most useful for genuinely non-stationary series; here the errors are stationary ($|\rho| < 1$), so HAC SEs are the natural fix
**Practical Recommendations:**
For time series regressions:
1. **Always plot your data** (levels and differences)
2. **Check for trends** (visual, augmented Dickey-Fuller test)
3. **Examine ACF** of residuals
4. **Use HAC SEs** as default for time series
5. **Consider differencing** if series are non-stationary
6. **Report both** levels and differences specifications
**Bottom Line:**
In this simulated AR(1) example:
- Default SEs give **false confidence**
- HAC SEs reveal **true uncertainty**
- Even after correction, `x` stays **strongly related** to `y` (the true slope is 2)
- But the effect is **less precisely estimated** than default SEs suggest!
## 16.7 Example - Democracy and Growth
We analyze the relationship between democracy and economic growth using data from Acemoglu, Johnson, Robinson, and Yared (2008).
**Research question**: Does economic growth promote democracy?
**Data**: 131 countries, 1500-2000
- **democracy**: 500-year change in democracy index
- **growth**: 500-year change in log GDP per capita
- **constraint**: Constraints on executive at independence
- **indcent**: Year of independence
- **catholic, muslim, protestant, other**: Religious composition
**Key hypothesis**: Institutions matter for democracy and growth
```{python}
# Load democracy data
data_democracy = pd.read_stata(GITHUB_DATA_URL + 'AED_DEMOCRACY.DTA')
# 16.7: Democracy And Growth
print("\nData summary:")
summary_vars = ['democracy', 'growth', 'constraint', 'indcent',
'catholic', 'muslim', 'protestant', 'other']
data_democracy[summary_vars].describe()
print(f"\nSample size: {len(data_democracy)} countries")
print(f"Time period: 1500-2000")
```
We begin with the simplest specification: regress the 500-year change in democracy on economic growth alone. The scatter plot and fitted line below show the raw association before any controls are added.
```{python}
# Bivariate regression: democracy ~ growth
fit_bivariate = pf.feols('democracy ~ growth', data=data_democracy, vcov='HC1')
# Key results
print(f"Growth coefficient: {fit_bivariate.coef()['growth']:.4f} (SE: {fit_bivariate.se()['growth']:.4f})")
print(f"R-squared: {fit_bivariate._r2:.4f}")
# Full regression output
fit_bivariate.summary()
# Visualize relationship
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(data_democracy['growth'], data_democracy['democracy'],
alpha=0.6, s=50, color='#22d3ee')
ax.plot(data_democracy['growth'], fit_bivariate.predict(),
color='#c084fc', linewidth=2, label='OLS regression line')
ax.set_xlabel('Change in Log GDP per capita (1500-2000)', fontsize=12)
ax.set_ylabel('Change in Democracy (1500-2000)', fontsize=12)
ax.set_title('Figure 16.1: Democracy and Growth, 1500-2000',
fontsize=14, fontweight='bold')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print("\nInterpretation:")
print(f" Coefficient: {fit_bivariate.coef()['growth']:.4f}")
print(f" Higher economic growth is associated with greater democratization.")
print(f" But this may reflect omitted institutional variables...")
```
**What to look for in this scatter plot:**
- **Direction**: Positive slope -- countries with more economic growth tend to have more democratization
- **Scatter**: Substantial variation around the line -- growth explains only a fraction of democracy differences
- **Potential confounders**: The positive association may partly reflect omitted institutional variables (religion, colonial history) rather than a direct causal effect
Now we add institutional controls — executive constraints, independence date, and religious composition. If growth was partly standing in for these omitted factors, its coefficient should shrink once they enter the model.
```{python}
# Multiple regression: add institutional controls
# Multiple Regression with Institutional Controls
fit_multiple = pf.feols('democracy ~ growth + constraint + indcent + catholic + muslim + protestant',
data=data_democracy, vcov='HC1')
# Key results
print(f"Growth coefficient: {fit_multiple.coef()['growth']:.4f} (SE: {fit_multiple.se()['growth']:.4f})")
print(f"R-squared: {fit_multiple._r2:.4f}")
# Full regression output
fit_multiple.summary()
print("\nKey findings:")
print(f" Growth coefficient fell from {fit_bivariate.coef()['growth']:.4f} to {fit_multiple.coef()['growth']:.4f}")
print(f" Institutional variables (religion, constraints) are important.")
print(f" This suggests omitted variable bias in the bivariate model.")
```
> **Key Concept 16.6: Omitted Variables Bias in Practice**
>
> The democracy-growth example demonstrates omitted variables bias: the growth coefficient falls from 0.131 (bivariate) to 0.047 (with controls), a 64% reduction that also turns a highly significant effect (t ≈ 6.7) into one indistinguishable from zero at the 5% level (t ≈ 1.8, p ≈ 0.07). Institutional variables (religion, executive constraints) were correlated with both democracy and growth, biasing the bivariate estimate upward. Always ask: "What variables might affect my outcome and correlate with my key regressor?" Include relevant controls to reduce bias.
```{python}
# Get residuals from multiple regression for diagnostic plots
uhat = fit_multiple._u_hat
yhat = fit_multiple.predict()
# Residual Diagnostics Prepared
print(f"Number of residuals: {len(uhat)}")
print(f"Residual mean (should be ~0): {uhat.mean():.6f}")
print(f"Residual std dev: {uhat.std():.4f}")
```
## 16.8 Diagnostics - Residual Plots
Diagnostic plots help detect violations of model assumptions:
1. **Actual vs Fitted**: Should cluster around 45° line
2. **Residual vs Fitted**: Should scatter randomly around zero
3. **Residual vs Regressor**: Should scatter randomly around zero
4. **Component Plus Residual Plot**: $b_j x_j + e$ vs $x_j$ (detects nonlinearity)
5. **Added Variable Plot**: Partial $y$ vs partial $x_j$ (isolates effect)
**LOWESS smooth**: Nonparametric smooth curve helps detect patterns
---
### Reading Diagnostic Plots: What to Look For
The diagnostic plots help us **visually detect** violations of regression assumptions. Let's interpret what we see:
**Panel A: Actual vs Fitted**
**What to look for:**
- Points should **cluster around 45° line**
- LOWESS smooth should **follow** the 45° line closely
- Deviations indicate **systematic prediction errors**
**In the democracy-growth example:**
- Most points **reasonably close** to 45° line
- LOWESS smooth **roughly linear**, close to 45°
- Some **scatter** (R² ≈ 0.20-0.30, so significant unexplained variation)
- **No obvious systematic bias** (LOWESS not curved)
**Interpretation:**
- Model captures **general relationship** reasonably
- But substantial **residual variation** remains
- No evidence of **major nonlinearity** (LOWESS smooth is linear)
**Panel B: Residual vs Fitted**
**What to look for:**
- Residuals should **scatter randomly** around zero
- **Equal spread** across range of fitted values (homoskedasticity)
- LOWESS should be **horizontal** at zero
- No **patterns**, **curvature**, or **heteroskedasticity**
**In the democracy-growth example:**
- Residuals **scatter** around zero
- LOWESS smooth **close to horizontal**
- Spread appears **roughly constant**
- Some **outliers** but not extreme
**Potential issues to watch for:**
1. **Heteroskedasticity**: Fan shape (spread increases)
2. **Nonlinearity**: LOWESS curved (missing quadratic term)
3. **Outliers**: Points far from zero (influential observations)
**Key Diagnostic Insights:**
1. **No major heteroskedasticity**:
- Spread doesn't systematically increase/decrease
- Robust SEs still advisable (safety margin)
- But not severe heteroskedasticity
2. **Linearity assumption appears okay**:
- LOWESS smooth roughly horizontal
- If curved: suggests missing nonlinear terms
- Could try quadratic, interactions
3. **A few potential outliers**:
- Countries with large positive/negative residuals
- Follow up with DFITS, DFBETAS (see next sections)
- Investigate: data errors or genuinely unusual cases?
**What Would Bad Plots Look Like?**
**Heteroskedasticity (fan shape):**
- Residual spread **increases** with fitted values
- Common in income, revenue, GDP data
- Solution: Log transformation or WLS
**Nonlinearity (curved LOWESS):**
- LOWESS smooth **curves** (U-shape or inverted U)
- Missing quadratic or other nonlinear terms
- Solution: Add polynomial, interaction, or transform
**Autocorrelation (time series):**
- Residuals show **runs** (streaks of same sign)
- Not visible in scatter plot (need time-series plot)
- Solution: HAC SEs, add lags, difference
**Outliers:**
- A few points **very far** from main cluster
- Can distort regression line
- Investigate with influence diagnostics (DFITS, DFBETAS)
**The LOWESS Smooth:**
**What is it?**
- **L**ocally **W**eighted **S**catterplot **S**moothing
- Nonparametric smooth curve through data
- Helps detect **patterns** hard to see in raw scatter
**How to interpret:**
- Should be **straight** and **flat** if model is correct
- **Curvature** suggests missing nonlinearity
- **Trend** (not horizontal) suggests systematic bias
**Bottom Line:**
For democracy-growth model:
- Diagnostic plots look **reasonably good**
- No glaring violations of assumptions
- Some outliers worth investigating (next section)
- Model appears **adequately specified**
- But low R² suggests many **omitted variables**
### Diagnostic Plots for Individual Regressor (Growth)
Three specialized plots for examining the growth variable:
1. **Residual vs Regressor**: Checks for heteroskedasticity and nonlinearity
2. **Component Plus Residual**: $b_{growth} \times growth + e$ vs $growth$
- Linear relationship → straight line
- Nonlinearity → curved LOWESS
3. **Added Variable Plot**: Controls for other variables
- Slope equals coefficient in full model
- Shows partial relationship
```{python}
# 16.8: Diagnostic Plots
# Figure 16.2: Basic diagnostic plots
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
# Panel A: Actual vs Fitted
axes[0].scatter(yhat, data_democracy['democracy'], alpha=0.6, s=50, color='#22d3ee')
axes[0].plot([yhat.min(), yhat.max()], [yhat.min(), yhat.max()],
'-', color='#c084fc', linewidth=2, label='45° line')
lowess_result = lowess(data_democracy['democracy'], yhat, frac=0.3) # frac=0.3: use 30% of data for each local fit (balances smoothness vs detail)
axes[0].plot(lowess_result[:, 0], lowess_result[:, 1],
'r--', linewidth=2, label='LOWESS smooth')
axes[0].set_xlabel('Fitted Democracy', fontsize=12)
axes[0].set_ylabel('Actual Democracy', fontsize=12)
axes[0].set_title('Panel A: Actual vs Fitted', fontsize=12, fontweight='bold')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# Panel B: Residual vs Fitted
axes[1].scatter(yhat, uhat, alpha=0.6, s=50, color='#22d3ee')
axes[1].axhline(y=0, color='white', alpha=0.3, linewidth=2, linestyle='-')
lowess_result = lowess(uhat, yhat, frac=0.3)
axes[1].plot(lowess_result[:, 0], lowess_result[:, 1],
'r--', linewidth=2, label='LOWESS smooth')
axes[1].set_xlabel('Fitted Democracy', fontsize=12)
axes[1].set_ylabel('Residual', fontsize=12)
axes[1].set_title('Panel B: Residual vs Fitted', fontsize=12, fontweight='bold')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.suptitle('Figure 16.2: Basic Diagnostic Plots',
fontsize=14, fontweight='bold', y=1.00)
plt.tight_layout()
plt.show()
```
**What to look for in these diagnostic plots:**
- **Panel A (Actual vs Fitted)**: Points should cluster around the 45-degree line; LOWESS smooth should follow it closely
- **Panel B (Residual vs Fitted)**: Residuals should scatter randomly around zero with constant spread; LOWESS should be flat and horizontal
```{python}
# Figure 16.3: Diagnostic plots for growth regressor
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
# Panel A: Residual vs Regressor
axes[0].scatter(data_democracy['growth'], uhat, alpha=0.6, s=50, color='#22d3ee')
axes[0].axhline(y=0, color='white', alpha=0.3, linewidth=2, linestyle='-')
lowess_result = lowess(uhat, data_democracy['growth'], frac=0.3)
axes[0].plot(lowess_result[:, 0], lowess_result[:, 1],
'r--', linewidth=2, label='LOWESS smooth')
axes[0].set_xlabel('Growth regressor', fontsize=11)
axes[0].set_ylabel('Democracy Residual', fontsize=11)
axes[0].set_title('Panel A: Residual vs Regressor', fontsize=12, fontweight='bold')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# Panel B: Component Plus Residual
b_growth = fit_multiple.coef()['growth']
pr_growth = b_growth * data_democracy['growth'] + uhat
axes[1].scatter(data_democracy['growth'], pr_growth, alpha=0.6, s=50, color='#22d3ee')
# Regression line
fit_compplusres = pf.feols('pr_growth ~ growth',
data=pd.DataFrame({'growth': data_democracy['growth'],
'pr_growth': pr_growth}))
axes[1].plot(data_democracy['growth'], fit_compplusres.predict(),
'-', color='#c084fc', linewidth=2, label='Regression line')
lowess_result = lowess(pr_growth, data_democracy['growth'], frac=0.3)
axes[1].plot(lowess_result[:, 0], lowess_result[:, 1],
'r--', linewidth=2, label='LOWESS smooth')
axes[1].set_xlabel('Growth regressor', fontsize=11)
axes[1].set_ylabel(f'Dem Res + {b_growth:.3f}*Growth', fontsize=11)
axes[1].set_title('Panel B: Component Plus Residual', fontsize=12, fontweight='bold')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
# Panel C: Added Variable Plot
fit_nogrowth = pf.feols('democracy ~ constraint + indcent + catholic + muslim + protestant',
data=data_democracy)
uhat_democ = fit_nogrowth._u_hat
fit_growth_partial = pf.feols('growth ~ constraint + indcent + catholic + muslim + protestant',
data=data_democracy)
uhat_growth = fit_growth_partial._u_hat
axes[2].scatter(uhat_growth, uhat_democ, alpha=0.6, s=50, color='#22d3ee')
fit_addedvar = pf.feols('uhat_democ ~ uhat_growth',
data=pd.DataFrame({'uhat_growth': uhat_growth,
'uhat_democ': uhat_democ}))
axes[2].plot(uhat_growth, fit_addedvar.predict(),
'-', color='#c084fc', linewidth=2, label='Regression line')
lowess_result = lowess(uhat_democ, uhat_growth, frac=0.3)
axes[2].plot(lowess_result[:, 0], lowess_result[:, 1],
'r--', linewidth=2, label='LOWESS smooth')
axes[2].set_xlabel('Growth regressor (partial)', fontsize=11)
axes[2].set_ylabel('Democracy (partial)', fontsize=11)
axes[2].set_title('Panel C: Added Variable', fontsize=12, fontweight='bold')
axes[2].legend()
axes[2].grid(True, alpha=0.3)
plt.suptitle('Figure 16.3: Diagnostic Plots for Growth Regressor',
fontsize=14, fontweight='bold', y=1.00)
plt.tight_layout()
plt.show()
print(f"\nPanel C: Slope equals coefficient in full model ({b_growth:.4f})")
```
**What to look for in these diagnostic plots:**
- **Panel A (Residual vs Regressor)**: Check for patterns -- random scatter around zero means no issues; curvature suggests missing nonlinear terms
- **Panel B (Component Plus Residual)**: LOWESS smooth close to the regression line confirms a linear relationship is appropriate
- **Panel C (Added Variable)**: Slope equals the coefficient in the full model, showing the partial effect of growth after controlling for other variables
> **Key Concept 16.7: Diagnostic Plots for Model Validation**
>
> Three complementary plots assess individual regressors: (1) residual vs. regressor checks for patterns suggesting nonlinearity or heteroskedasticity; (2) component-plus-residual plot ($b_j x_j + e$ vs. $x_j$) reveals the partial relationship and detects nonlinearity; (3) added variable plot purges both $y$ and $x_j$ of other regressors, showing the pure partial effect whose slope equals the OLS coefficient $b_j$. LOWESS smoothing helps reveal systematic patterns.
### Influential Observations: DFITS
**DFITS** measures influence on fitted values:
$$DFITS_i = \frac{\hat{y}_i - \hat{y}_{i(i)}}{s_{(i)} \sqrt{h_{ii}}}$$
where:
- $\hat{y}_i$ = prediction including observation $i$
- $\hat{y}_{i(i)}$ = prediction excluding observation $i$
- $s_{(i)}$ = RMSE excluding observation $i$
- $h_{ii}$ = leverage of observation $i$
**Rule of thumb**: Investigate if $|DFITS_i| > 2\sqrt{k/n}$
```{python}
# Influential Observations: Dfits
# OLSInfluence requires a statsmodels fitted model (diagnostics only)
_diag_model = smf.ols('democracy ~ growth + constraint + indcent + catholic + muslim + protestant',
data=data_democracy).fit()
influence = OLSInfluence(_diag_model)
dfits = influence.dffits[0]
n = len(data_democracy)
threshold_dfits = 2 * np.sqrt(len(fit_multiple.coef()) / n)
print(f"\nDFITS threshold: {threshold_dfits:.4f}")
print(f"Observations exceeding threshold: {np.sum(np.abs(dfits) > threshold_dfits)}")
# Plot DFITS
obs_index = np.arange(n)
colors = ['red' if abs(d) > threshold_dfits else '#22d3ee' for d in dfits]
fig, ax = plt.subplots(figsize=(12, 6))
ax.scatter(obs_index, dfits, c=colors, alpha=0.6, s=50)
ax.axhline(y=threshold_dfits, color='red', linestyle='--', linewidth=2, label=f'Threshold: ±{threshold_dfits:.3f}')
ax.axhline(y=-threshold_dfits, color='red', linestyle='--', linewidth=2)
ax.axhline(y=0, color='white', alpha=0.3, linestyle='-', linewidth=1)
ax.set_xlabel('Observation Index', fontsize=12)
ax.set_ylabel('DFITS', fontsize=12)
ax.set_title('Figure: DFITS - Influential Observations', fontsize=14, fontweight='bold')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
**Interpretation:** Red points exceed the threshold and are potentially influential. Investigate these observations for data errors or genuinely unusual cases before deciding whether to keep or exclude them.
---
#### Identifying Influential Observations with DFITS
DFITS measures how much an observation influences its **own prediction**. The results help identify **potentially problematic** observations:
**Understanding DFITS:**
Formula: $DFITS_i = \frac{\hat{y}_i - \hat{y}_{i(i)}}{s_{(i)} \sqrt{h_{ii}}}$
where:
- $\hat{y}_i$ = prediction **including** observation i
- $\hat{y}_{i(i)}$ = prediction **excluding** observation i
- $s_{(i)}$ = RMSE excluding observation i
- $h_{ii}$ = leverage (how unusual is $x_i$?)
**Interpretation:**
- DFITS measures **standardized change** in fitted value when i is deleted
- Large |DFITS| → observation strongly influences its own prediction
- Can be driven by **leverage** (unusual X) or **residual** (unusual Y|X)
**Rule of Thumb:**
Threshold: $|DFITS_i| > 2\sqrt{k/n}$
For democracy-growth model (k ≈ 7, n = 131):
- Threshold ≈ \$2\sqrt{7/131} = 2 \times 0.231 \approx **0.46**
**Typical Results:**
- **Most observations**: |DFITS| < 0.30 (not influential)
- **A few observations**: |DFITS| = 0.5-0.8 (moderately influential)
- **Extreme cases**: |DFITS| > 1.0 (highly influential)
**What Makes an Observation Influential?**
Two components multiply:
1. **Leverage** ($h_{ii}$): Unusual X values
2. **Standardized residual**: Large prediction error
**Most influential when both are large:**
- Observation with **unusual combination of regressors** (high leverage)
- **AND** doesn't fit the pattern (large residual)
- Example: A country with unique institutions AND surprising democracy level
**What to Do with Influential Observations:**
**1. Investigate the data:**
- Is it a **data error**? (typo, coding mistake)
- Check original sources
- If error: **correct or remove**
**2. Understand the case:**
- Is it genuinely unusual? (e.g., special historical circumstances)
- Example: Post-colonial country with unique constraints
- Adds valuable information, **keep it**
**3. Check robustness:**
- Re-estimate **without** the influential observations
- Do conclusions change substantially?
- If yes: Results **fragile**, interpret cautiously
- If no: Results **robust**, less concerning
**4. Model improvement:**
- Does omitting observation suggest missing variables?
- Example: Maybe need regional dummies
- Influential observations often **signal model misspecification**
**Example Interpretation:**
Suppose observation #47 has DFITS = 0.85:
- This country's predicted democracy changes by **0.85 standard deviations** when it's excluded
- Country is either:
- **High leverage** (unusual institutional characteristics), or
- **Large residual** (democracy level doesn't match institutions), or
- **Both**
- Warrants investigation
**DFITS vs. Other Influence Measures:**
- **DFITS**: Influence on **own prediction**
- **DFBETAS**: Influence on **regression coefficients** (see next)
- **Cook's D**: Overall influence on **all fitted values**
- **Leverage** ($h_{ii}$): Just the X-space component
**Visualization:**
The DFITS plot shows:
- **Blue points**: Not influential (within threshold)
- **Red points**: Influential (exceed threshold)
- Should be **mostly blue** with a **few red** outliers
- Many red points → model problems or data issues
**In the Democracy-Growth Example:**
Typical findings:
- 3-10 countries exceed threshold (out of 131)
- These are **countries with unusual institutional/growth combinations**
- Might include:
- Rapidly democratizing autocracies
- Stable democracies with slow growth
- Post-conflict transitions
- Resource-rich countries with unusual politics
**Practical Advice:**
**Do:**
- Always compute influence diagnostics
- Investigate observations exceeding thresholds
- Report whether results change without influential cases
- Consider robustness checks
**Don't:**
- Automatically delete influential observations
- Ignore them without investigation
- Only report results **after** deleting outliers (selective reporting)
- Delete based solely on statistical criteria (needs substantive judgment)
**Bottom Line:**
DFITS is a **screening tool**:
- Identifies observations **worth investigating**
- Not a mechanical **deletion rule**
- Combine statistical diagnosis with **subject-matter knowledge**
- Goal: Better understand data and model, not just clean data
### Influential Observations: DFBETAS
**DFBETAS** measures influence on individual coefficients:
$$DFBETAS_{j, i} = \frac{\hat{\beta}_j - \hat{\beta}_{j(i)}}{s_{(i)} \sqrt{(X'X)^{-1}_{jj}}}$$
where:
- $\hat{\beta}_j$ = coefficient including observation $i$
- $\hat{\beta}_{j(i)}$ = coefficient excluding observation $i$
**Rule of thumb**: Investigate if $|DFBETAS_{j, i}| > 2/\sqrt{n}$
```{python}
# Influential Observations: Dfbetas
dfbetas = influence.dfbetas
threshold_dfbetas = 2 / np.sqrt(n)
print(f"\nDFBETAS threshold: {threshold_dfbetas:.4f}")
# Plot DFBETAS for each variable
param_names = list(fit_multiple.coef().index)
n_params = len(param_names)
fig, axes = plt.subplots(2, 3, figsize=(18, 10))
axes = axes.flatten()
for i, param in enumerate(param_names):
if i < len(axes):
colors = ['red' if abs(d) > threshold_dfbetas else '#22d3ee'
for d in dfbetas[:, i]]
axes[i].scatter(obs_index, dfbetas[:, i], c=colors, alpha=0.6, s=30)
axes[i].axhline(y=threshold_dfbetas, color='red', linestyle='--', linewidth=1.5)
axes[i].axhline(y=-threshold_dfbetas, color='red', linestyle='--', linewidth=1.5)
axes[i].axhline(y=0, color='white', alpha=0.3, linestyle='-', linewidth=0.5)
axes[i].set_xlabel('Observation', fontsize=10)
axes[i].set_ylabel('DFBETAS', fontsize=10)
axes[i].set_title(f'{param}', fontsize=11, fontweight='bold')
axes[i].grid(True, alpha=0.3)
# Remove extra subplots
for i in range(n_params, len(axes)):
fig.delaxes(axes[i])
plt.suptitle('DFBETAS: Influential Observations by Variable',
fontsize=14, fontweight='bold', y=1.00)
plt.tight_layout()
plt.show()
```
**What to look for in the DFBETAS plots:**
- **Red points** indicate observations with large influence on that specific coefficient
- An observation might strongly affect one coefficient but not others
- Investigate whether flagged cases are data errors or genuinely unusual cases
> **Key Concept 16.8: Influential Observations -- DFITS and DFBETAS**
>
> DFITS measures influence on fitted values: $DFITS_i$ is the scaled change in $\hat{y}_i$ when observation $i$ is excluded. DFBETAS measures influence on individual coefficients: $DFBETAS_{j,i}$ is the scaled change in $\hat{\beta}_j$. Thresholds for investigation are $|DFITS| > 2\sqrt{k/n}$ and $|DFBETAS| > 2/\sqrt{n}$. Don't automatically delete influential points -- investigate whether they represent data errors, genuine outliers, or valid extreme values that carry important information.
## Key Takeaways
**Multicollinearity:**
- Multicollinearity occurs when regressors are highly correlated, making individual coefficients imprecisely estimated
- VIF > 10 indicates serious multicollinearity; VIF > 5 warrants investigation
- OLS remains unbiased and consistent -- the problem is precision, not bias
- Solutions: use joint F-tests, drop redundant variables, center variables before creating interactions, or collect more data
**OLS Assumption Violations:**
- Assumptions 1-2 violations (incorrect model, endogeneity) cause bias and inconsistency -- fundamental problems requiring model changes or IV
- Assumptions 3-4 violations (heteroskedasticity, autocorrelation) do not bias coefficients but invalidate standard errors
- Wrong standard errors lead to incorrect t-statistics, confidence intervals, and hypothesis tests
- Omitted variables bias formula: $\text{Bias} = \beta_3 \times \delta_{23}$, where $\beta_3$ is the omitted variable's effect and $\delta_{23}$ is the slope from an auxiliary regression of the omitted variable on the included regressor
**Heteroskedasticity and Robust Standard Errors:**
- Heteroskedasticity means error variance varies across observations, common in cross-sectional data
- Use heteroskedasticity-robust (HC1/White) standard errors for valid inference
- Robust SEs are typically larger than default SEs, giving more conservative (honest) inference
- Always use robust SEs for cross-sectional regressions as a default practice
**Autocorrelation and HAC Standard Errors:**
- Autocorrelation means errors are correlated over time, common in time series data
- Default SEs are typically too small with autocorrelation, leading to over-rejection
- Use HAC (Newey-West) standard errors that account for both heteroskedasticity and autocorrelation
- Check the ACF of residuals to detect autocorrelation patterns
**Diagnostic Plots:**
- Residual vs. fitted values: detect heteroskedasticity (fan shape) and nonlinearity (curved pattern)
- Component-plus-residual plot: detect nonlinearity in individual regressors
- Added variable plot: isolate partial relationship between y and x, controlling for other variables
- LOWESS smooth helps reveal patterns that are hard to see in raw scatter plots
**Influential Observations:**
- DFITS measures influence on fitted values; threshold $|\text{DFITS}| > 2\sqrt{k/n}$
- DFBETAS measures influence on individual coefficients; threshold $|\text{DFBETAS}| > 2/\sqrt{n}$
- Investigate influential observations rather than automatically deleting them
- Check whether conclusions change substantially when influential cases are excluded
**Python tools:** `pyfixest` (OLS estimation, robust/cluster SEs), `statsmodels` (VIF, OLSInfluence, LOWESS), `matplotlib`/`seaborn` (diagnostic plots)
**Python Libraries and Code:**
This single code block reproduces the core workflow of Chapter 16. It is self-contained — copy it into an empty notebook and run it to review the complete pipeline from multicollinearity detection to residual diagnostics and influence analysis.
```python
# =============================================================================
# CHAPTER 16 CHEAT SHEET: Checking the Model and Data
# =============================================================================
# --- Libraries ---
import numpy as np # numerical operations
import pandas as pd # data loading and manipulation
import matplotlib.pyplot as plt # creating plots and visualizations
import pyfixest as pf # fast OLS estimation
# !pip install pyfixest
import statsmodels.api as sm # add_constant for VIF calculation
import statsmodels.formula.api as smf # for diagnostics-only models
from statsmodels.stats.outliers_influence import ( # diagnostic tools:
variance_inflation_factor, OLSInfluence) # VIF and influence measures
from statsmodels.nonparametric.smoothers_lowess import lowess # LOWESS smooth for residual plots
# =============================================================================
# STEP 1: Load data
# =============================================================================
# Two datasets: earnings (cross-section) and democracy (cross-country)
url_base = "https://raw.githubusercontent.com/quarcs-lab/data-open/master/AED/"
data_earnings = pd.read_stata(url_base + "AED_EARNINGS_COMPLETE.DTA")
data_democracy = pd.read_stata(url_base + "AED_DEMOCRACY.DTA")
print(f"Earnings: {data_earnings.shape[0]} workers, {data_earnings.shape[1]} variables")
print(f"Democracy: {data_democracy.shape[0]} countries, {data_democracy.shape[1]} variables")
# =============================================================================
# STEP 2: Detect multicollinearity with VIF
# =============================================================================
# VIF_j = 1/(1 - R_j^2): measures how much SE inflates due to collinearity
# VIF > 10 = serious problem; VIF > 5 = investigate further
X_vif = data_earnings[['age', 'education', 'agebyeduc']].copy()
X_vif = sm.add_constant(X_vif)
vif_data = pd.DataFrame({
'Variable': X_vif.columns,
'VIF': [variance_inflation_factor(X_vif.values, i) for i in range(X_vif.shape[1])]
})
print("\nVariance Inflation Factors (with interaction term):")
print(vif_data.to_string(index=False))
# =============================================================================
# STEP 3: Compare standard vs robust standard errors
# =============================================================================
# Heteroskedasticity makes default SEs too small -> use HC1 (White) robust SEs
fit_std = pf.feols('earnings ~ age + education', data=data_earnings)
fit_robust = pf.feols('earnings ~ age + education', data=data_earnings, vcov='HC1')
se_comparison = pd.DataFrame({
'Variable': fit_std.coef().index,
'Standard SE': fit_std.se().values.round(2),
'Robust SE': fit_robust.se().values.round(2),
'Ratio': (fit_robust.se() / fit_std.se()).values.round(3)
})
print("\nSE Comparison (ratio > 1 signals heteroskedasticity):")
print(se_comparison.to_string(index=False))
# =============================================================================
# STEP 4: Omitted variable bias — democracy and growth
# =============================================================================
# Adding controls reveals how much the bivariate estimate was biased upward
fit_bivariate = pf.feols('democracy ~ growth', data=data_democracy, vcov='HC1')
fit_multiple = pf.feols('democracy ~ growth + constraint + indcent + catholic + muslim + protestant',
data=data_democracy, vcov='HC1')
b_biv = fit_bivariate.coef()['growth']
b_mult = fit_multiple.coef()['growth']
print(f"\nGrowth coefficient (bivariate): {b_biv:.4f}")
print(f"Growth coefficient (with controls): {b_mult:.4f}")
print(f"Reduction: {(1 - b_mult/b_biv)*100:.0f}% — institutional controls absorb the bias")
# =============================================================================
# STEP 5: Diagnostic plots — residual vs fitted
# =============================================================================
# Random scatter around zero = assumptions OK; fan shape = heteroskedasticity
uhat = fit_multiple._u_hat
yhat = fit_multiple.predict()
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Panel A: Actual vs Fitted
axes[0].scatter(yhat, data_democracy['democracy'], s=50, alpha=0.6)
axes[0].plot([yhat.min(), yhat.max()], [yhat.min(), yhat.max()],
'r-', linewidth=2, label='45° line')
axes[0].set_xlabel('Fitted Democracy')
axes[0].set_ylabel('Actual Democracy')
axes[0].set_title('Actual vs Fitted')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# Panel B: Residual vs Fitted (with LOWESS smooth)
axes[1].scatter(yhat, uhat, s=50, alpha=0.6)
axes[1].axhline(y=0, color='gray', linewidth=1)
lw = lowess(uhat, yhat, frac=0.3) # LOWESS reveals hidden patterns
axes[1].plot(lw[:, 0], lw[:, 1], 'r--', linewidth=2, label='LOWESS smooth')
axes[1].set_xlabel('Fitted Democracy')
axes[1].set_ylabel('Residual')
axes[1].set_title('Residual vs Fitted')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# =============================================================================
# STEP 6: Influential observations — DFITS
# =============================================================================
# DFITS_i measures how much prediction i changes when observation i is excluded
# Threshold: |DFITS| > 2*sqrt(k/n)
_diag_model = smf.ols('democracy ~ growth + constraint + indcent + catholic + muslim + protestant',
data=data_democracy).fit()
influence = OLSInfluence(_diag_model)
dfits = influence.dffits[0]
n = len(data_democracy)
k = len(fit_multiple.coef())
threshold = 2 * np.sqrt(k / n)
print(f"\nDFITS threshold: {threshold:.4f}")
print(f"Observations exceeding threshold: {np.sum(np.abs(dfits) > threshold)} out of {n}")
fig, ax = plt.subplots(figsize=(10, 6))
colors = ['red' if abs(d) > threshold else 'steelblue' for d in dfits]
ax.scatter(range(n), dfits, c=colors, s=40, alpha=0.7)
ax.axhline(y=threshold, color='red', linestyle='--', label=f'Threshold ±{threshold:.3f}')
ax.axhline(y=-threshold, color='red', linestyle='--')
ax.axhline(y=0, color='gray', linewidth=0.5)
ax.set_xlabel('Observation Index')
ax.set_ylabel('DFITS')
ax.set_title('Influential Observations (DFITS)')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
**Try it yourself!** Copy this code into an empty Google Colab notebook and run it: [Open Colab](https://colab.research.google.com/notebooks/empty.ipynb)
**Next Steps:**
- Chapter 17 extends these ideas to panel data, where you'll learn fixed effects and random effects models that address unobserved heterogeneity across units.
- Re-examine regressions from earlier chapters using this chapter's diagnostic workflow: VIF, robust SEs, residual plots, and influence measures.
- When residual plots or specification tests signal misspecification, experiment with nonlinear terms, interactions, or transformations before drawing conclusions.
- When endogeneity is suspected, review the instrumental-variables approach and look for a valid instrument.
---
Congratulations! You've completed Chapter 16 on model checking and data diagnostics. You now have both the theoretical understanding and practical Python skills to evaluate regression assumptions, detect problems, and apply appropriate remedies.
> **Common Mistakes to Avoid**
>
> - **Ignoring residual patterns**: Non-random residual plots indicate model misspecification
> - **Removing influential observations automatically**: Investigate why they are influential first
> - **Relying solely on R-squared to evaluate model quality**: A high R-squared with patterned residuals indicates problems
## Practice Exercises
**Exercise 1: Irrelevant Variables vs. Omitted Variables**
You estimate $y_i = \beta_1 + \beta_2 x_{2i} + \beta_3 x_{3i} + u_i$ by OLS.
(a) If $x_3$ should not appear in the model (irrelevant variable), what happens to the OLS estimates of $\beta_1$ and $\beta_2$? Are they biased?
(b) If a relevant variable $x_4$ was omitted from the model, and $x_4$ is correlated with $x_2$, what happens to $\hat{\beta}_2$? Write the omitted variables bias formula.
**Exercise 2: VIF Interpretation**
A regression of earnings on age, education, and experience yields VIF values of 22.0 (age), 17.3 (education), and 36.9 (experience).
(a) Which variable has the most severe multicollinearity problem? Explain.
(b) Calculate the $R^2$ from the auxiliary regression for the variable with the highest VIF.
(c) By what factor are the standard errors inflated compared to the no-collinearity case?
**Exercise 3: Choosing Standard Error Types**
For each scenario below, state which type of standard errors you would use (default, HC-robust, HAC, or cluster-robust) and why:
(a) Cross-sectional regression of wages on education and experience for 5,000 workers.
(b) Time series regression of GDP growth on interest rates using 200 quarterly observations.
(c) Regression of test scores on class size using data from 50 schools with multiple classrooms per school.
**Exercise 4: Heteroskedasticity Detection**
You estimate a regression and obtain the following SE comparison:
| Variable | Standard SE | Robust SE | Ratio |
|----------|-------------|-----------|-------|
| Education | 570 | 642 | 1.13 |
| Age | 154 | 151 | 0.98 |
(a) Is there evidence of heteroskedasticity? Which variable's inference is most affected?
(b) If you used standard SEs and the t-statistic for education was 2.05, would the conclusion change with robust SEs?
**Exercise 5: DFITS Threshold Calculation**
In a regression with $k = 7$ regressors and $n = 131$ observations:
(a) Calculate the DFITS threshold for identifying influential observations.
(b) If 8 observations exceed this threshold, what percentage of the sample is flagged as potentially influential?
(c) Describe the steps you would take to investigate these influential observations.
**Exercise 6: Autocorrelation Consequences**
A time series regression yields a first-lag residual autocorrelation of $\rho_1 = 0.80$.
(a) Is this evidence of autocorrelation? What does it mean for the residual pattern?
(b) Approximate the factor by which the effective sample size is reduced (use the formula $\frac{1+\rho}{1-\rho}$).
(c) A coefficient has a default t-statistic of 4.5. If the HAC standard error is 3 times larger than the default, what is the corrected t-statistic? Is the coefficient still significant at 5%?
## Case Studies
### Case Study 1: Regression Diagnostics for Cross-Country Productivity Analysis
In this case study, you will apply the diagnostic techniques from this chapter to analyze cross-country labor productivity using the Mendez convergence clubs dataset.
**Dataset:** Mendez (2020) convergence clubs data
- **Source:** `https://raw.githubusercontent.com/quarcs-lab/mendez2020-convergence-clubs-code-data/master/assets/dat.csv`
- **Sample:** 108 countries, 1990-2014
- **Variables:** `lp` (labor productivity), `kl` (capital per worker), `h` (human capital), `GDPpc` (real GDP per capita), `TFP` (total factor productivity), `region`
**Research question:** What econometric issues arise when modeling cross-country productivity, and how do diagnostic tools help detect and address them?
---
#### Task 1: Detect Multicollinearity (Guided)
Load the dataset and estimate a regression of log labor productivity (`np.log(lp)`) on log capital per worker (`np.log(kl)`), human capital (`h`), and log GDP per capita (`np.log(GDPpc)`), using the year 2014 cross-section.
```python
import pandas as pd
import numpy as np
import pyfixest as pf
from statsmodels.stats.outliers_influence import variance_inflation_factor
import statsmodels.api as sm
url = "https://raw.githubusercontent.com/quarcs-lab/mendez2020-convergence-clubs-code-data/master/assets/dat.csv"
dat = pd.read_csv(url)
dat2014 = dat[dat['year'] == 2014].copy()
dat2014['ln_lp'] = np.log(dat2014['lp'])
dat2014['ln_kl'] = np.log(dat2014['kl'])
dat2014['ln_GDPpc'] = np.log(dat2014['GDPpc'])
fit = pf.feols('ln_lp ~ ln_kl + h + ln_GDPpc', data=dat2014, vcov='HC1')
fit.summary()
# Calculate VIF
X = dat2014[['ln_kl', 'h', 'ln_GDPpc']].dropna()
X = sm.add_constant(X)
for i, col in enumerate(X.columns):
print(f"VIF({col}): {variance_inflation_factor(X.values, i):.2f}")
```
Interpret the VIF values. Is multicollinearity a concern? Which variables are most collinear and why?
---
#### Task 2: Compare Standard and Robust Standard Errors (Guided)
Estimate the same model with both default and robust (HC1) standard errors. Create a comparison table.
```python
fit_default = pf.feols('ln_lp ~ ln_kl + h', data=dat2014)
fit_robust = pf.feols('ln_lp ~ ln_kl + h', data=dat2014, vcov='HC1')
comparison = pd.DataFrame({
'Default SE': fit_default.se(),
'Robust SE': fit_robust.se(),
'Ratio': fit_robust.se() / fit_default.se()
})
print(comparison)
```
Is there evidence of heteroskedasticity? Which coefficient's inference is most affected?
---
#### Task 3: Residual Diagnostic Plots (Semi-guided)
Create the three diagnostic plots for the productivity model:
1. Actual vs. fitted values with LOWESS smooth
2. Residuals vs. fitted values with LOWESS smooth
3. Residuals vs. `ln_kl` (component-plus-residual plot)
*Hint:* Use `from statsmodels.nonparametric.smoothers_lowess import lowess` for the LOWESS smooth. Plot residuals from the robust model.
What do the diagnostic plots reveal about the model specification?
---
#### Task 4: Identify Influential Countries (Semi-guided)
Calculate DFITS and DFBETAS for the productivity regression. Identify countries that exceed the thresholds.
*Hint:* Use `OLSInfluence(model).dffits[0]` and `OLSInfluence(model).dfbetas`. The DFITS threshold is $2\sqrt{k/n}$ and the DFBETAS threshold is $2/\sqrt{n}$.
Which countries are most influential? Investigate whether removing them changes the key coefficients substantially.
---
#### Task 5: Regional Heterogeneity Analysis (Independent)
Test whether the relationship between capital and productivity varies across regions:
1. Add region dummy variables and region-capital interactions
2. Test for heteroskedasticity by comparing default and robust SEs across specifications
3. Conduct an F-test for joint significance of regional interactions
Does allowing for regional heterogeneity improve the model diagnostics?
---
#### Task 6: Diagnostic Report (Independent)
Write a 200-300 word diagnostic report for the cross-country productivity regression. Your report should:
1. Summarize the multicollinearity assessment (VIF results)
2. Document the heteroskedasticity evidence (SE comparison)
3. Describe what the residual plots reveal about model specification
4. List the most influential countries and their potential impact
5. Recommend the appropriate standard error type and any model modifications
> **Key Concept 16.9: Systematic Regression Diagnostics**
>
> A complete regression diagnostic workflow includes: (1) check multicollinearity via VIF before interpreting individual coefficients; (2) compare standard and robust SEs to detect heteroskedasticity; (3) examine residual plots for nonlinearity and patterns; (4) identify influential observations with DFITS and DFBETAS; (5) document all findings and report robust results. Always investigate problems rather than mechanically applying fixes.
> **Key Concept 16.10: Cross-Country Regression Challenges**
>
> Cross-country regressions face specific diagnostic challenges: multicollinearity among development indicators (GDP, capital, education are highly correlated), heteroskedasticity across countries at different development levels, and influential observations from outlier countries. Using robust standard errors and carefully examining influential cases is essential for credible cross-country analysis.
**What You've Learned:**
In this case study, you applied the complete diagnostic toolkit to cross-country productivity data. You detected multicollinearity among development indicators, compared standard and robust standard errors, created diagnostic plots, and identified influential countries. These skills ensure that your regression results are reliable and your conclusions are credible.
### Case Study 2: Diagnosing the Satellite Prediction Model
**Research Question**: How reliable are the satellite-development regression models we have estimated throughout this textbook? Do they satisfy the standard regression assumptions?
**Background**: We have estimated multiple satellite-development regression models throughout this textbook. But how reliable are these models? In this case study, we apply Chapter 16's **diagnostic tools** to check for multicollinearity, heteroskedasticity, influential observations, and other model violations.
**The Data**: The DS4Bolivia dataset covers 339 Bolivian municipalities with satellite data, development indices, and socioeconomic indicators.
**Key Variables**:
- `mun`: Municipality name
- `dep`: Department (administrative region)
- `imds`: Municipal Sustainable Development Index (0-100)
- `ln_NTLpc2017`: Log nighttime lights per capita (2017)
- `A00`, `A10`, `A20`, `A30`, `A40`: Satellite image embedding dimensions
#### Load the DS4Bolivia Data
```{python}
# Load the DS4Bolivia dataset
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pyfixest as pf
import statsmodels.formula.api as smf
from statsmodels.stats.outliers_influence import variance_inflation_factor, OLSInfluence
import statsmodels.api as sm
url_bol = "https://raw.githubusercontent.com/quarcs-lab/ds4bolivia/master/ds4bolivia_v20250523.csv"
bol = pd.read_csv(url_bol)
# Load and merge satellite image embeddings
url_sat = "https://raw.githubusercontent.com/quarcs-lab/ds4bolivia/master/satelliteEmbeddings/satelliteEmbeddings2017.csv"
sat = pd.read_csv(url_sat)
bol = bol.merge(sat[['asdf_id', 'A00', 'A10', 'A20', 'A30', 'A40']], on='asdf_id', how='left')
# Select key variables for this case study
key_vars = ['mun', 'dep', 'imds', 'ln_NTLpc2017', 'A00', 'A10', 'A20', 'A30', 'A40']
bol_cs = bol[key_vars].copy().dropna()
# Ds4Bolivia: Regression Diagnostics Case Study
print(f"Observations (complete cases): {len(bol_cs)}")
print(f"\nKey variable summary:")
bol_cs[['imds', 'ln_NTLpc2017', 'A00', 'A10', 'A20', 'A30', 'A40']].describe().round(3)
```
#### Task 1: Multicollinearity Check (Guided)
**Objective**: Assess whether satellite predictors suffer from multicollinearity.
**Instructions**:
1. Compute the correlation matrix for the predictors (`ln_NTLpc2017`, `A00`, `A10`, `A20`, `A30`, `A40`)
2. Calculate VIF for each variable using `variance_inflation_factor()` from statsmodels
3. Flag variables with VIF > 10
4. Discuss: Are satellite embeddings multicollinear? Does multicollinearity affect the model's predictive power vs. individual coefficient interpretation?
```{python}
# Your code here: Multicollinearity diagnostics
#
# Example structure:
# predictors = ['ln_NTLpc2017', 'A00', 'A10', 'A20', 'A30', 'A40']
#
# # Correlation matrix
# print("CORRELATION MATRIX")
# print(bol_cs[predictors].corr().round(3))
#
# # VIF calculation
# X = bol_cs[predictors].copy()
# X = sm.add_constant(X)
# print("\nVARIANCE INFLATION FACTORS")
# for i, col in enumerate(X.columns):
# vif = variance_inflation_factor(X.values, i)
# flag = " *** HIGH" if vif > 10 and col != 'const' else ""
# print(f" VIF({col}): {vif:.2f}{flag}")
```
> **Key Concept 16.11: Multicollinearity in Satellite Features**
>
> Satellite embedding dimensions often correlate with each other because they capture **overlapping visual patterns** from the same images. When embeddings A00 and A10 both respond to building density, their collinearity inflates standard errors and makes individual coefficients unstable. The VIF (Variance Inflation Factor) quantifies this: a VIF above 10 signals problematic collinearity. Solutions include dropping redundant features, using principal components, or accepting imprecise individual estimates while maintaining valid joint inference.
#### Task 2: Standard vs Robust SEs (Guided)
**Objective**: Detect heteroskedasticity by comparing default and robust standard errors.
**Instructions**:
1. Estimate the full model: `imds ~ ln_NTLpc2017 + A00 + A10 + A20 + A30 + A40`
2. Compare default (homoskedastic) and HC1 (robust) standard errors
3. Compute the ratio of robust to default SEs for each coefficient
4. Discuss: Large differences signal heteroskedasticity. Which coefficients are most affected?
```{python}
# Your code here: Compare standard and robust SEs
#
# Example structure:
# fit_default = pf.feols('imds ~ ln_NTLpc2017 + A00 + A10 + A20 + A30 + A40',
# data=bol_cs)
# fit_robust = pf.feols('imds ~ ln_NTLpc2017 + A00 + A10 + A20 + A30 + A40',
# data=bol_cs, vcov='HC1')
#
# comparison = pd.DataFrame({
# 'Default SE': fit_default.se(),
# 'Robust SE': fit_robust.se(),
# 'Ratio': fit_robust.se() / fit_default.se()
# })
# print("STANDARD ERROR COMPARISON")
# print(comparison.round(4))
# print(f"\nMean ratio: {(fit_robust.se() / fit_default.se()).mean():.3f}")
```
#### Task 3: Residual Diagnostics (Semi-guided)
**Objective**: Create diagnostic plots to assess model assumptions visually.
**Instructions**:
1. Estimate the model with robust SEs
2. Create three diagnostic plots:
- (a) Fitted values vs. residuals (check for patterns/heteroskedasticity)
- (b) Q-Q plot of residuals (check for normality)
- (c) Histogram of residuals (check for skewness/outliers)
3. Interpret each plot: What do the patterns reveal about model adequacy?
**Hint**: Use `fit.predict()` for fitted values and `fit._u_hat` for residuals. For the Q-Q plot, use `from scipy import stats; stats.probplot(residuals, plot=ax)`.
```{python}
# Your code here: Residual diagnostic plots
#
# Example structure:
# from scipy import stats
# fit = pf.feols('imds ~ ln_NTLpc2017 + A00 + A10 + A20 + A30 + A40',
# data=bol_cs, vcov='HC1')
#
# fig, axes = plt.subplots(1, 3, figsize=(15, 5))
#
# # (a) Residuals vs Fitted
# axes[0].scatter(fit.predict(), fit._u_hat, alpha=0.4)
# axes[0].axhline(0, color='red', linestyle='--')
# axes[0].set_xlabel('Fitted Values')
# axes[0].set_ylabel('Residuals')
# axes[0].set_title('Residuals vs Fitted')
#
# # (b) Q-Q Plot
# stats.probplot(fit._u_hat, plot=axes[1])
# axes[1].set_title('Q-Q Plot of Residuals')
#
# # (c) Histogram
# axes[2].hist(fit._u_hat, bins=30, edgecolor='black', alpha=0.7)
# axes[2].set_xlabel('Residuals')
# axes[2].set_title('Distribution of Residuals')
#
# plt.tight_layout()
# plt.show()
```
#### Task 4: Influential Municipalities (Semi-guided)
**Objective**: Identify municipalities that disproportionately influence the regression results.
**Instructions**:
1. Calculate DFITS for all observations
2. Apply the threshold: $|DFITS| > 2\sqrt{k/n}$ where $k$ = number of parameters and $n$ = sample size
3. Identify the municipalities that exceed the threshold
4. Calculate DFBETAS for the key coefficient (`ln_NTLpc2017`)
5. Discuss: Are the influential municipalities capital cities or special cases?
**Hint**: Build a diagnostics-only statsmodels fit first — `_diag_model = smf.ols(...).fit()` — then pass it to `OLSInfluence(_diag_model)` (OLSInfluence needs a statsmodels result, not a pyfixest one).
```{python}
# Your code here: Influential observation analysis
#
# Example structure:
# # OLSInfluence needs a statsmodels fit, so build a diagnostics-only model
# _diag_model = smf.ols('imds ~ ln_NTLpc2017 + A00 + A10 + A20 + A30 + A40',
# data=bol_cs).fit()
# infl = OLSInfluence(_diag_model)
#
# # DFITS
# dfits_vals = infl.dffits[0]
# k = len(_diag_model.params)
# n = len(bol_cs)
# threshold = 2 * np.sqrt(k / n)
#
# influential = bol_cs.copy()
# influential['dfits'] = dfits_vals
# influential_muns = influential[np.abs(influential['dfits']) > threshold]
#
# print(f"DFITS threshold: {threshold:.4f}")
# print(f"Influential municipalities: {len(influential_muns)} out of {n}")
# print("\nInfluential municipalities:")
# print(influential_muns[['mun', 'dep', 'imds', 'ln_NTLpc2017', 'dfits']]
# .sort_values('dfits', key=abs, ascending=False).to_string(index=False))
```
> **Key Concept 16.12: Spatial Outliers and Influential Observations**
>
> In municipality-level analysis, **capital cities** and special economic zones often appear as influential observations. These municipalities may have unusually high NTL (from concentrated economic activity) or unusual satellite patterns (dense urban cores). A single influential municipality can shift regression coefficients substantially. DFITS and DFBETAS identify such observations, allowing us to assess whether our conclusions depend on a few exceptional cases.
#### Task 5: Omitted Variable Analysis (Independent)
**Objective**: Assess potential omitted variable bias by adding department controls.
**Instructions**:
1. Estimate models with and without department fixed effects (`C(dep)`)
2. Compare the satellite coefficients across specifications
3. Discuss: Do satellite coefficients change when adding department dummies?
4. What is the direction of potential omitted variable bias?
5. Consider: What unobserved factors might department dummies capture (geography, climate, policy)?
```{python}
# Your code here: Omitted variable analysis
#
# Example structure:
# m_no_dept = pf.feols('imds ~ ln_NTLpc2017 + A00 + A10', data=bol_cs, vcov='HC1')
# m_with_dept = pf.feols('imds ~ ln_NTLpc2017 + A00 + A10 + C(dep)', data=bol_cs, vcov='HC1')
#
# print("WITHOUT department controls:")
# print(f" NTL coef: {m_no_dept.coef()['ln_NTLpc2017']:.4f} (SE: {m_no_dept.se()['ln_NTLpc2017']:.4f})")
# print(f" R²: {m_no_dept._r2:.4f}")
#
# print("\nWITH department controls:")
# print(f" NTL coef: {m_with_dept.coef()['ln_NTLpc2017']:.4f} (SE: {m_with_dept.se()['ln_NTLpc2017']:.4f})")
# print(f" R²: {m_with_dept._r2:.4f}")
#
# print(f"\nCoefficient change: {m_with_dept.coef()['ln_NTLpc2017'] - m_no_dept.coef()['ln_NTLpc2017']:.4f}")
```
#### Task 6: Diagnostic Report (Independent)
**Objective**: Write a 200-300 word comprehensive model assessment.
**Your report should address**:
1. **Multicollinearity**: Summarize VIF results for satellite features. Are any problematic?
2. **Heteroskedasticity**: What does the SE comparison reveal? Should we use robust SEs?
3. **Residual patterns**: What do the diagnostic plots show about model specification?
4. **Influential observations**: Which municipalities are most influential? Do they represent special cases?
5. **Omitted variables**: How do department controls affect the satellite coefficients?
6. **Recommendations**: What corrections or modifications would you recommend for the satellite prediction model?
```{python}
# Your code here: Additional analysis for the diagnostic report
#
# You might want to:
# 1. Create a summary table of diagnostic findings
# 2. Re-estimate the model excluding influential observations
# 3. Compare results with and without corrections
# 4. Summarize key statistics for your report
```
#### What You've Learned from This Case Study
Through this diagnostic analysis of the satellite prediction model, you've applied Chapter 16's complete toolkit to real geospatial data:
- **Multicollinearity assessment**: Computed VIF for satellite features and identified correlated embeddings
- **Heteroskedasticity detection**: Compared standard and robust SEs to assess variance assumptions
- **Residual diagnostics**: Created visual diagnostic plots to check model assumptions
- **Influence analysis**: Used DFITS and DFBETAS to identify municipalities that drive the results
- **Omitted variable assessment**: Tested sensitivity of results to department controls
- **Critical thinking**: Formulated recommendations for improving the satellite prediction model
**Connection**: In Chapter 17, we move to *panel data*—analyzing how nighttime lights evolve over time across municipalities, using fixed effects to control for time-invariant characteristics.
---